






不懂Embedding,何以懂AI?
本文将从Text Embedding工作原理 、Image Embedding工作原理、Vedio _Embedding工作原理三个方面,带您一文搞懂Embedding工作原理。
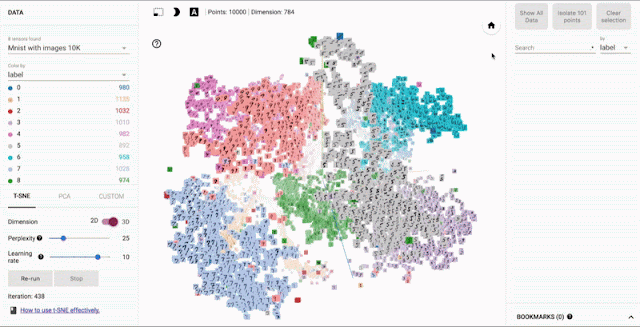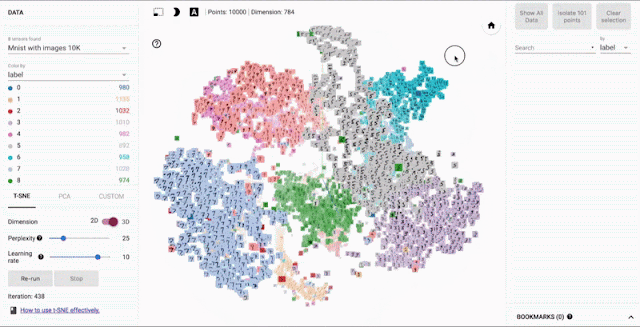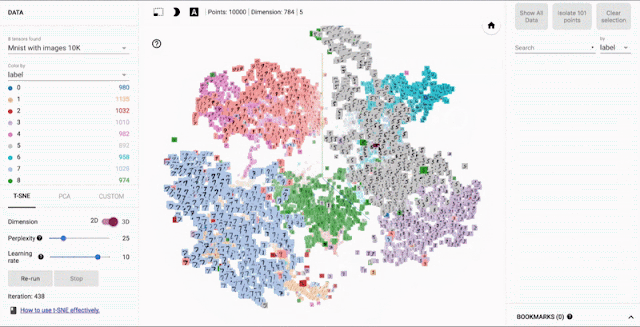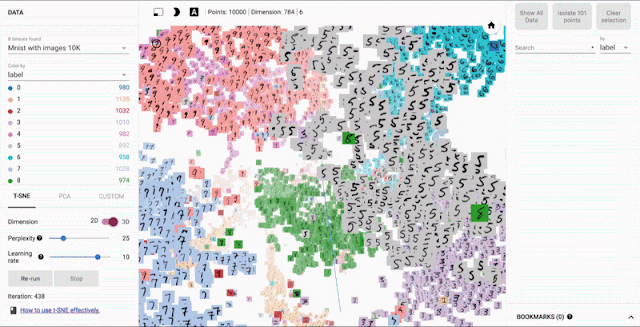
Embedding可视化

文本向量化(Text Embedding): 将文本数据(词、句子、文档)表示成向量的方法。
词向量化将词转为二进制或高维实数向量,句子和文档向量化则将句子或文档转为数值向量,通过平均、神经网络或主题模型实现。
-
词向量化:将单个词转换为数值向量。
-
独热编码(One-Hot Encoding):为每个词分配一个唯一的二进制向量,其中只有一个位置是1,其余位置是0。
-
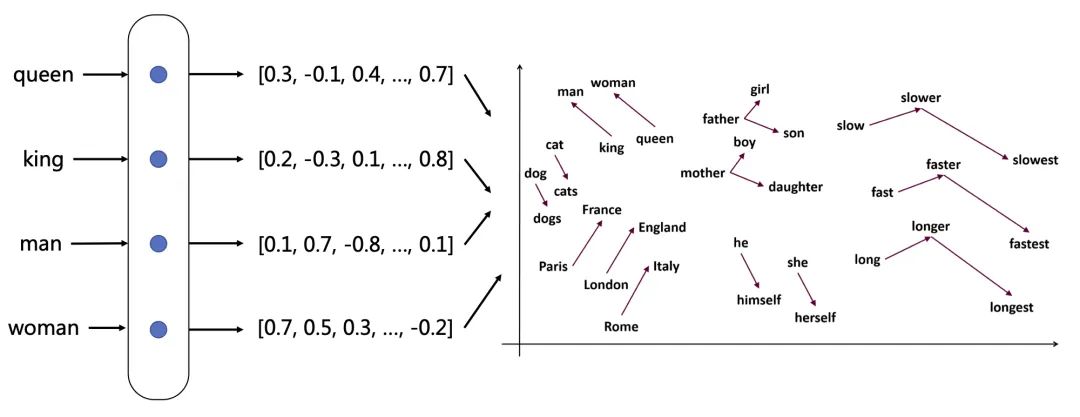
词嵌入(Word Embeddings):如Word2Vec, GloVe, FastText等,将每个词映射到一个高维实数向量,这些向量在语义上是相关的。
词向量化
-
句子向量化:将整个句子转换为一个数值向量。
-
简单平均/加权平均:对句子中的词向量进行平均或根据词频进行加权平均。
-
递归神经网络(RNN):通过递归地处理句子中的每个词来生成句子表示。
-
卷积神经网络(CNN):使用卷积层来捕捉句子中的局部特征,然后生成句子表示。
-
自注意力机制(如Transformer):如BERT模型,通过对句子中的每个词进行自注意力计算来生成句子表示。
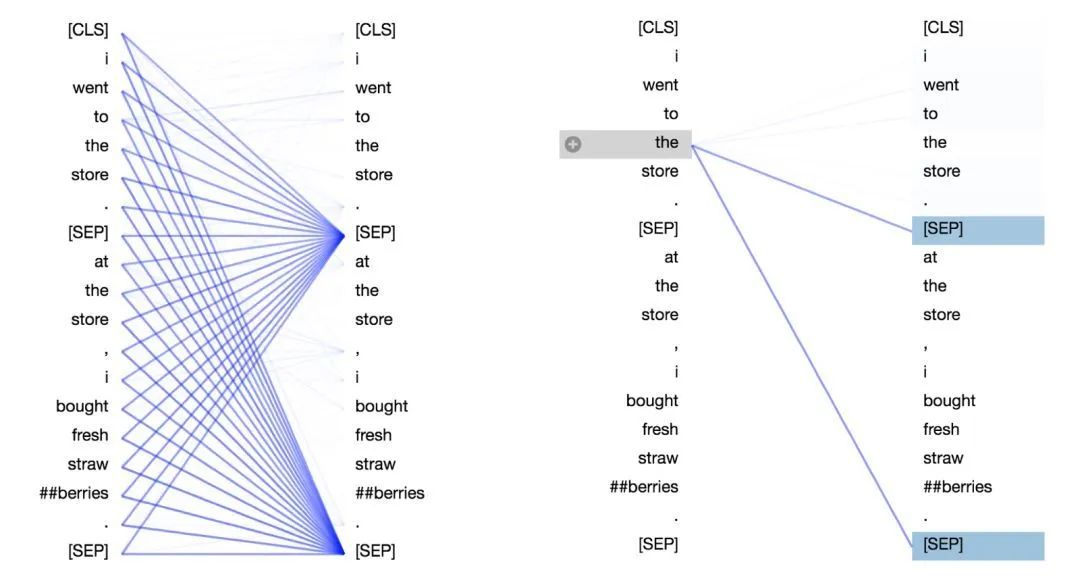
BERT句子向量化
-
文档向量化:将整个文档(如一篇文章或一组句子)转换为一个数值向量。
-
简单平均/加权平均:对文档中的句子向量进行平均或加权平均。
文档主题模型(如LDA):通过捕捉文档中的主题分布来生成文档表示。
层次化模型:如Doc2Vec,它扩展了Word2Vec,可以生成整个文档的向量表示。
文档向量化
统计方法用TF-IDF和N-gram统计生成文本向量,而神经网络方法如Word2Vec、GloVe等通过深度学习学习文本向量。

TF-IDF
-
基于神经网络的方法
-
词嵌入:
Word2Vec:通过预测词的上下文来学习词向量。
GloVe:通过全局词共现统计来学习词向量。
FastText:考虑词的n-gram特征来学习词向量。
-
句子嵌入:
RNN:包括LSTM和GRU,可以处理变长句子并生成句子向量。
Transformer:使用自注意力机制和位置编码来处理句子,生成句子向量。
-
文档嵌入:
Doc2Vec:扩展了Word2Vec,可以生成整个文档的向量表示。
BERT:基于Transformer的预训练模型,可以生成句子或短文档的向量表示。
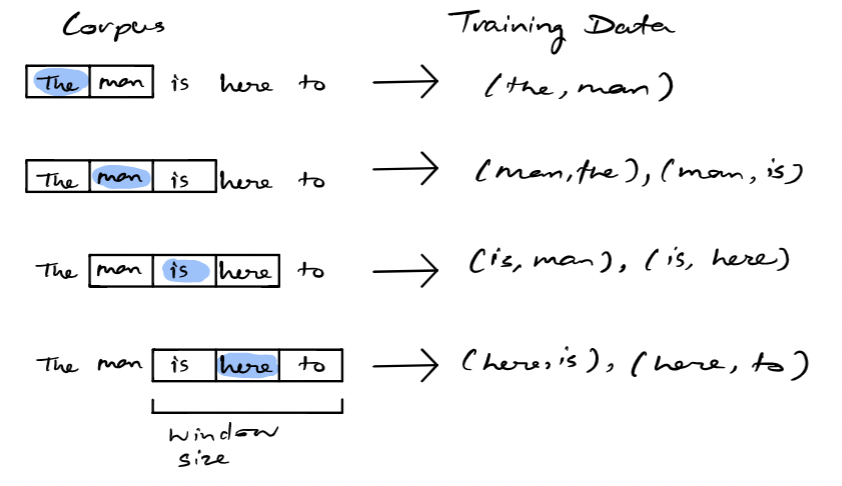
Word2Vec
工作原理:将离散的文字信息(如单词)转换成连续的向量数据。这样,语义相似的词在向量空间中位置相近,并通过高维度捕捉语言的复杂性。
-
将离散信息(如单词、符号)转换为分布式连续值数据(向量)。
-
相似的项目(如语义上相近的单词)在向量空间中被映射到相近的位置。
-
提供了更多的维度(如1536个维度)来表示人类语言的复杂度。
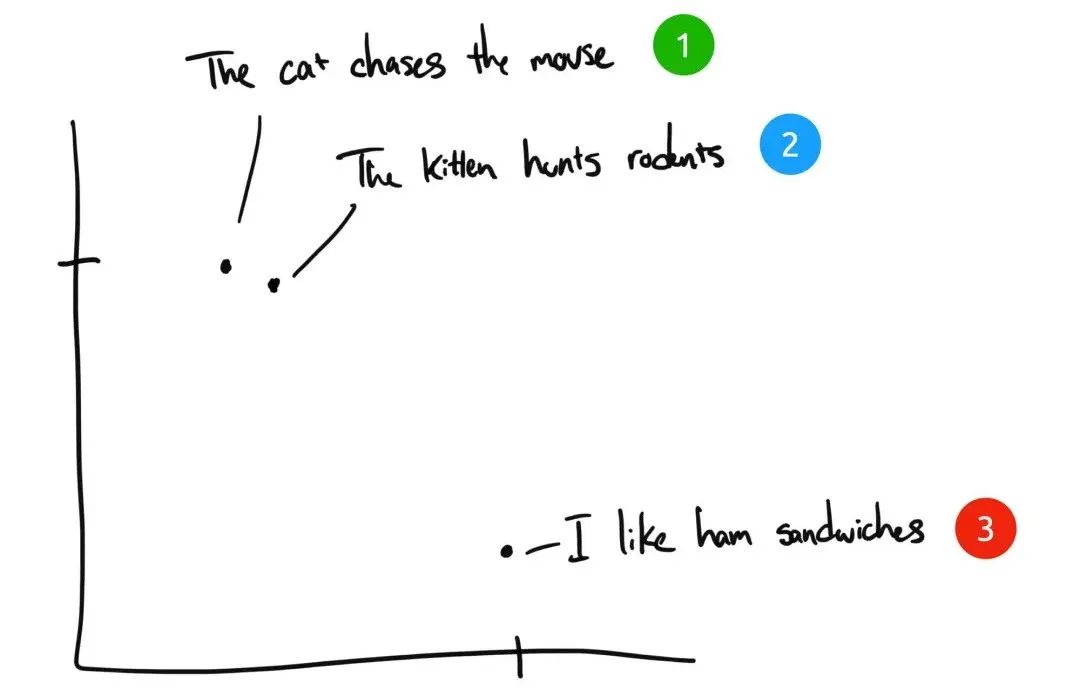
举例来讲,这里有三句话:
-
“The cat chases the mouse” 猫追逐老鼠。
-
“The kitten hunts rodents” 小猫捕猎老鼠。
-
“I like ham sandwiches” 我喜欢火腿三明治。
人类能理解句子1和句子2含义相近,尽管它们只有“The”这个单词相同。但计算机需要Embedding技术来理解这种关系。Embedding将单词转换为向量,使得语义相似的句子在向量空间中位置相近。这样,即使句子1和句子2没有很多共同词汇,计算机也能理解它们的相关性。
如果是人类来理解,句子 1 和句子 2 几乎是同样的含义,而句子 3 却完全不同。但我们看到句子 1 和句子 2 只有“The”是相同的,没有其他相同词汇。计算机该如何理解前两个句子的相关性?
Embedding将单词转换为向量,使得语义相似的句子在向量空间中位置相近。这样,即使句子1和句子2没有很多共同词汇,计算机也能理解它们的相关性。
向量空间可视化
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈


图像向量化(Image Embedding):将图像数据转换为向量的过程。
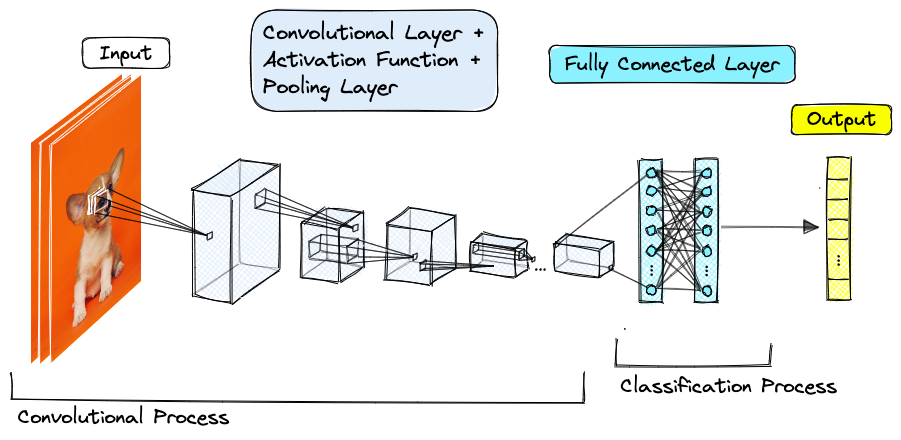
卷积神经网络和自编码器都是用于图像向量化的有效工具,前者通过训练提取图像特征并转换为向量,后者则学习图像的压缩编码以生成低维向量表示。
-
卷积神经网络(CNN):通过训练卷积神经网络模型,我们可以从原始图像数据中提取特征,并将其表示为向量。例如,使用预训练的模型(如VGG16, ResNet)的特定层作为特征提取器。
-
自编码器(Autoencoders):这是一种无监督的神经网络,用于学习输入数据的有效编码。在图像向量化中,自编码器可以学习从图像到低维向量的映射。
CNN
_工作原理:_通过算法提取图像的关键特征点及其描述符,将这些特征转换为高维向量表示,使得在向量空间中相似的图像具有相近的向量表示,从而便于进行图像检索、分类和识别等任务。
-
特征提取:使用算法(如SIFT、SURF、HOG等)从图像中提取关键特征点及其描述符。
-
高维空间:图像向量通常在高维空间中表示,每个维度对应一个特征或特征描述符。
-
相似度度量:在向量空间中,可以使用距离度量(如欧氏距离、余弦相似度等)来比较不同图像向量的相似度。

图像向量化

视频向量化 (Vedio Embedding):OpenAI的Sora将视觉数据转换为图像块(Turning visual data into patches)。
-
视觉块的引入: 为了将视觉数据转换成适合生成模型处理的格式,研究者提出了视觉块嵌入编码(visual patches)的概念。这些视觉块是图像或视频的小部分,类似于文本中的词元。
-
处理高维数据: 在处理高维视觉数据时(如视频),首先将其压缩到一个低维潜在空间。这样做可以减少数据的复杂性,同时保留足够的信息供模型学习。

将视觉数据转换为图像块
工作原理: Sora 用visual patches 代表被压缩后的视频向量进行训练,每个patches相当于GPT中的一个token。使用patches,可以对视频、音频、文字进行统一的向量化表示,和大模型中的 tokens 类似,Sora用 patches 表示视频,把视频压缩到低维空间(latent space)后表示为Spacetime patches。
OpenAI大模型的核心架构:大力出奇迹。Embedding技术实现文本、图像、视频等数据向量化表示,为大型模型提供了丰富的特征输入。只要模型规模足够大,这些向量化数据就能驱动模型生成各种所需的内容,体现了“万物皆可生成”的能力。
在大模型时代,我们如何有效的去学习大模型?
现如今大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也_想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家_。
一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,下面是我整理好的一套完整的学习路线,希望能够帮助到你们学习AI大模型。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF书籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型各大场景实战案例

结语
【一一AGI大模型学习 所有资源获取处(无偿领取)一一】
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}