






去年年初LLM刚起步的时候,大模型的部署方案还不是很成熟,如今仅仅过了一年多,LLM部署方案已经遍地都是了。
而多模态模型相比大语言模型来说,发展的还没有很“特别”成熟,不过由于两者结构很相似,LLMs的经验还是可以很好地利用到VLMs中。
本篇文章中提到的多模态指的是视觉多模态,即VLM(Vision Language Models)。
以下用一张图展示下简单多模态模型的运行流程:
-
Text Embeddings即文本输入,就是常见LLM中的输入;
-
而Multomode projector则是多模态模型额外一个模态的输入,这里指的是视觉输入信息,当然是转换维度之后的;
将这个转换维度之后的视觉特征和Text Embeddings执行concat操作合并起来,输入decoder中(例如llama)就完成推理流程了;
Multomode projector负责将原始的图像特征转换下维度,输出转换后的图像特征;所以有个中文叫投射层,这个名字有点抽象,理解就行,其实就是个mlp层,转换下视觉特征的维度
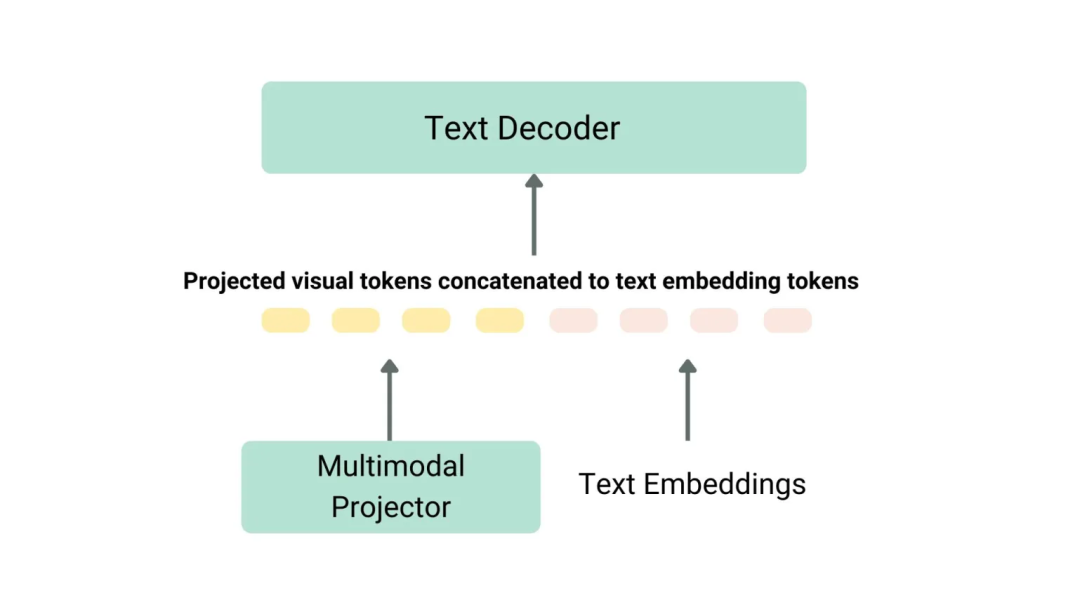
多模态运作流程 from https://huggingface.co/blog/zh/vlms
引入VLM
VLM就是视觉encoder加上语言decoder,这么说可能有点抽象,我们先简单回顾下transformer的基本结构:
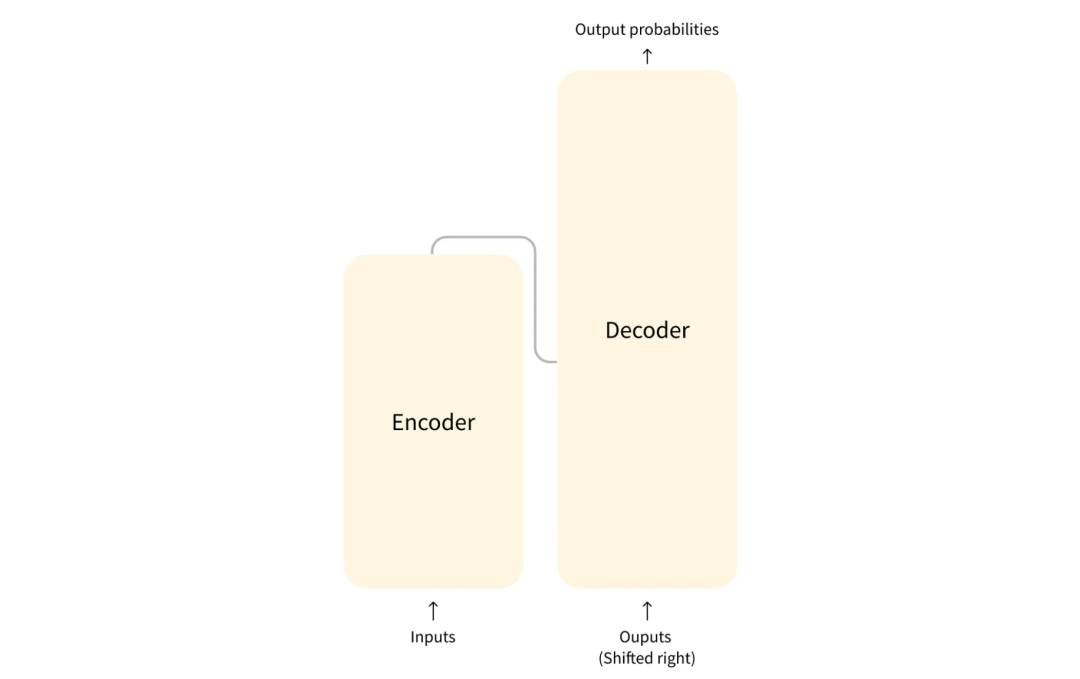
from huggingface
由编码器和解码器组成,最开始的transformer主要是处理机器翻译任务,结构是encoder+decoder。除了这个结构,还有一些其他结构适用于各种任务,比如
-
Encoder-only models:适用于需要理解输入的任务,例如句子分类和命名实体识别。
-
Decoder-only models:适用于生成性任务,如文本生成。
-
Encoder-decoder models or sequence-to-sequence models:适用于需要输入的生成性任务,例如翻译或摘要。
我们常见的llama属于Decoder-only models,只有decoder层;bert属于encoder-only;T5属于encoder-decoder。llama不多说了,BERT 是一种仅包含编码器的模型,它通过学习双向的上下文来更好地理解语言的深层含义。
BERT 通常用于理解任务,如情感分析、命名实体识别、问题回答等。T5 模型包括编码器和解码器,适用于同时需要理解和生成语言的任务。T5 被设计来处理各种“文本到文本”的任务,比如机器翻译、文摘生成、文本分类等。这种结构允许模型首先通过编码器理解输入文本,然后通过解码器生成相应的输出文本。基础知识就过到这里,我们先说enc-dec结构。
Encoder-Decoder (Enc-Dec)
注意,Enc-Dec模型需要区别于多模态模型,目前TensorRT-LLM官方支持的enc-dec模型如下:
-
T5[1]
-
T5v1.1[2] and Flan-T5[3]
-
mT5[4]
-
BART[5]
-
mBART[6]
-
FairSeq NMT[7]
-
ByT5[8]
第一个就是T5也就是上述提到的编码器+解码器结构。需要注意这些模型都是基于Transformer架构的自然语言处理(NLP)模型,区别于多模态模型,这些模型主要是处理文本,算是单模态。
VLM or multimodal
而多模态除了本文,就带上了图像:
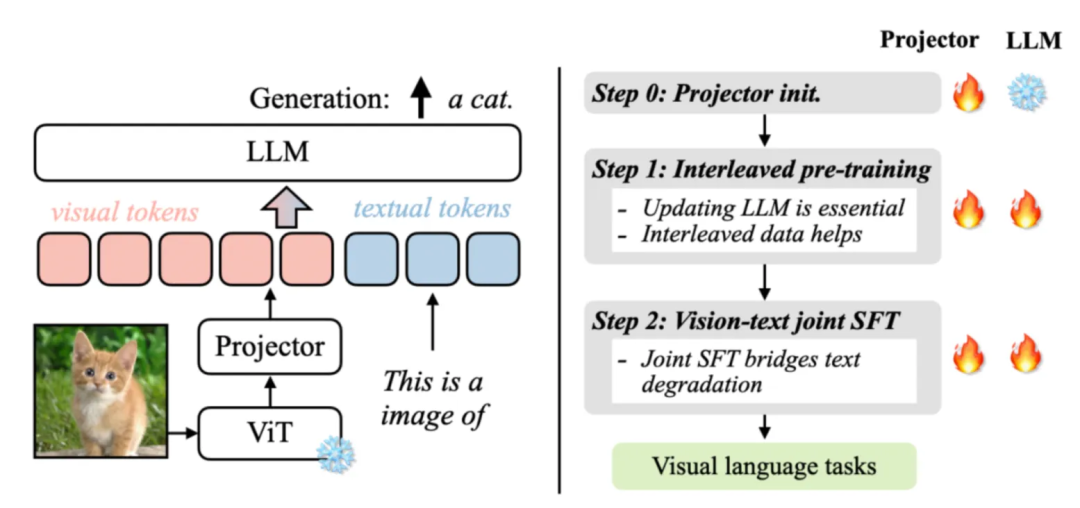
VILA架构和训练流程
VILA[9]是nvidia推出的一个视觉语言模型,上图很清楚地介绍了其推理和训练流程。我知道的一些多模态模型有(这些模型来自lmdeploy官方github介绍):
-
LLaVA(1.5,1.6) (7B-34B)
-
InternLM-XComposer2 (7B, 4khd-7B)
-
QWen-VL (7B)
-
DeepSeek-VL (7B)
-
InternVL-Chat (v1.1-v1.5)
-
MiniGeminiLlama (7B)
-
CogVLM-Chat (17B)
-
CogVLM2-Chat (19B)
-
MiniCPM-Llama3-V-2_5
这里我只简单介绍下llava,毕竟llava是较早的做多模态的模型,之后很多多模态的架构和llava基本都差不多。剩下的多模态模型大家可以自行查阅,结构基本都类似。
LLAVA
LLaVA(2304)[10]作为VLMs的代表性工作,号称只需要几个小时的训练,即可让一个LLM转变为VLM:
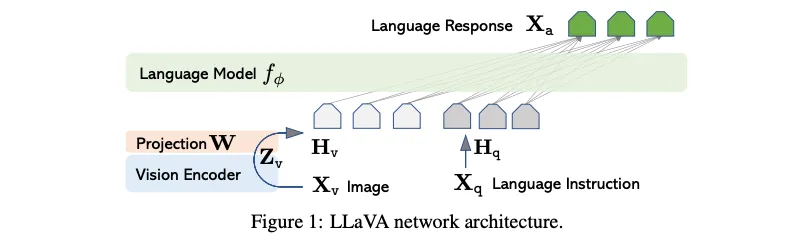
image
训练方式比较简单,主要操作是将视觉图像视作一种“外语”(相比于之前纯nlp,图像可以当做额外输入的外语),利用vision-encoder和projection[11]将“图像翻译成文本信号”,并微调LLM从而可以适应图像任务,我们简单看下其推理代码:

llava的整体运行过程
其中processor就是图像预处理,处理后得到的input为:inputs.pixel_values,其shape是torch.Size([1, 3, 336, 336])。然后进入generate阶段:
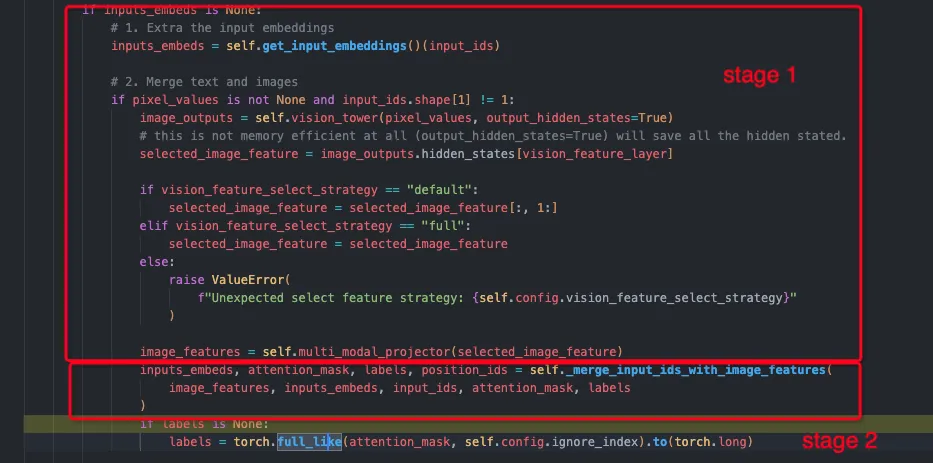
image
第一步(stage-1)是执行encoder部分:
-
input_ids(torch.Size([1, 17])) -> input_embeds(torch.Size([1, 17, 4096]))
-
pixel_values(torch.Size([1, 3, 336, 336]))经过视觉模型 输出视觉特征(torch.Size([1, 576, 1024]))
-
视觉特征经过投影层(mlp)输出最终的图像特征(torch.Size([1, 576, 4096]))
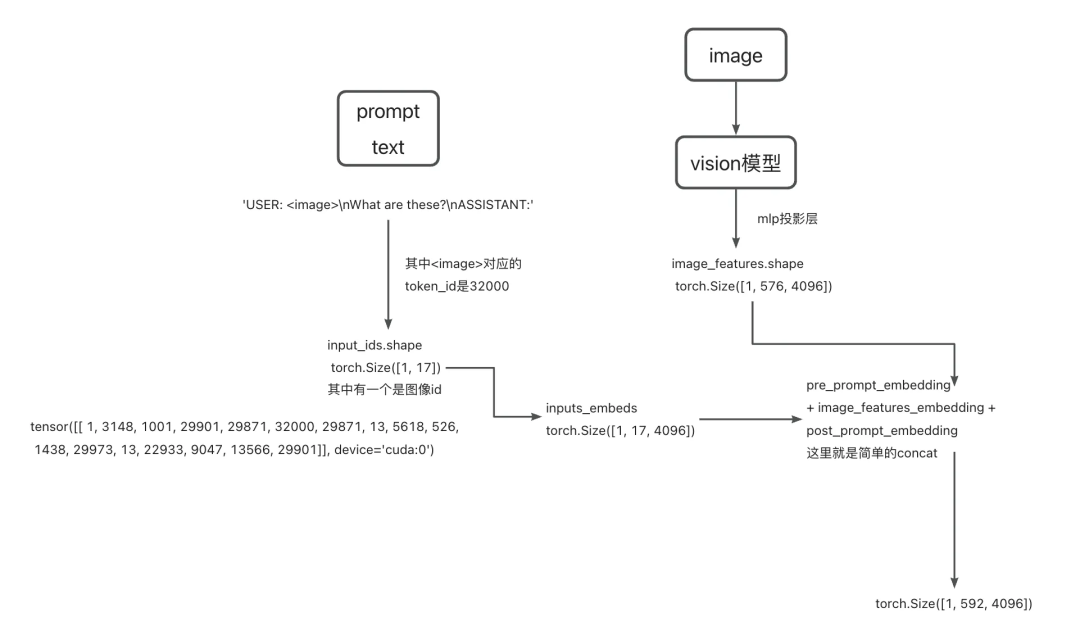
第二步(stage-2)是执行文字embed和图像embed合并过程,也就是合并inputs_embeds + image_features,最终得到的inputs_embeds维度为torch.Size([1, 592, 4096]),具体在llava中是pre_prompt + image + post_prompt一起输入进来,其中image的特征替换prompt中的标记,对应的token id为32000。
而这个_merge_input_ids_with_image_features函数的作用主要是将image_features和inputs_embeds合并起来:在合并完两者之后,其余部分就和普通的decoder基本一致了。整体运行流程如下:
其他多模态模型拼输入的方式和llava类似,比如InternVLChat[12],输入的prompt是这样的:
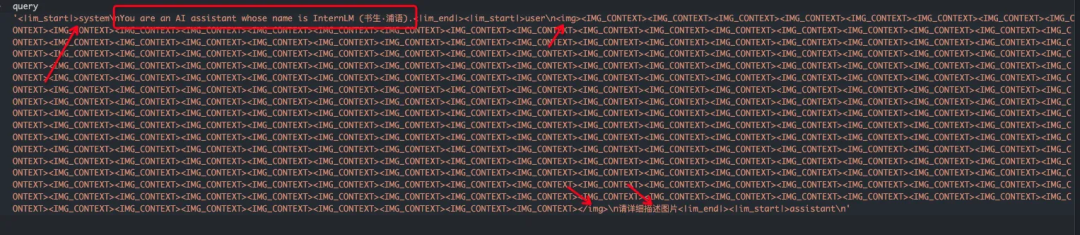
image
转换为token_ids如下,其图像特征占位,img_context_token_id是92546:
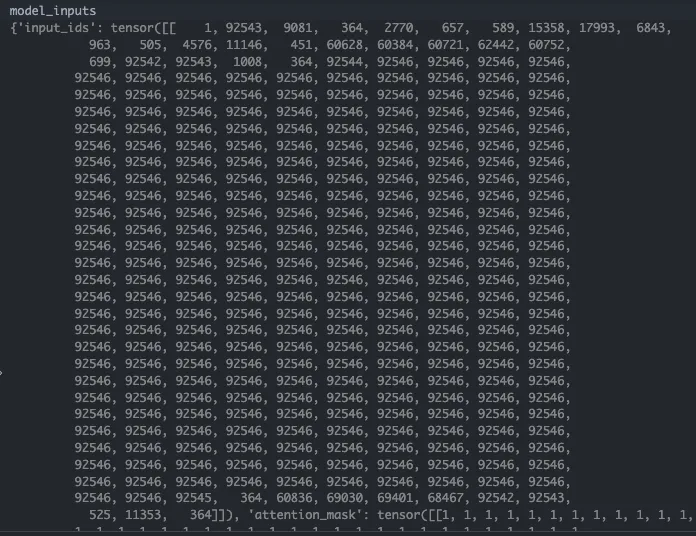
image
上述prompt中的<IMG_CONTEXT>之后会被实际的图像特征填上,目前只是占个位子。运行过程中的维度变化:
-
pixel_values.shape torch.Size([1, 3, 224, 224]) -> vision model -> torch.Size([1, 64, 2048])
-
input_ids torch.Size([1, 293]) -> language model embed -> torch.Size([1, 293, 2048])
核心代码如下,需要注意这里是先占位再填(input_embeds[selected]=…)的形式,不是llava中concat的形式,最终实现效果是一样的。
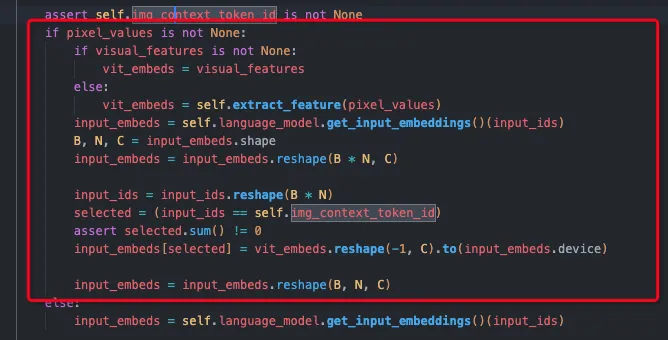
image
最终也是将合并后的embeds送入language-decoder中。
包含cross-attention的多模态
上述介绍的多模态模型都是文本输入和图像输入转换为embeds合并后,输入language decoder中,这个decoder可以是常见的decoder-only models,比如llama。
还有些特殊的多模态模型的decoder部分会有cross-attention结构,比如meta推出的nougat[13]。其视觉特征不会和input_ids合并,而是单独输入decoder,在decoder中和文本特征进行cross attention:
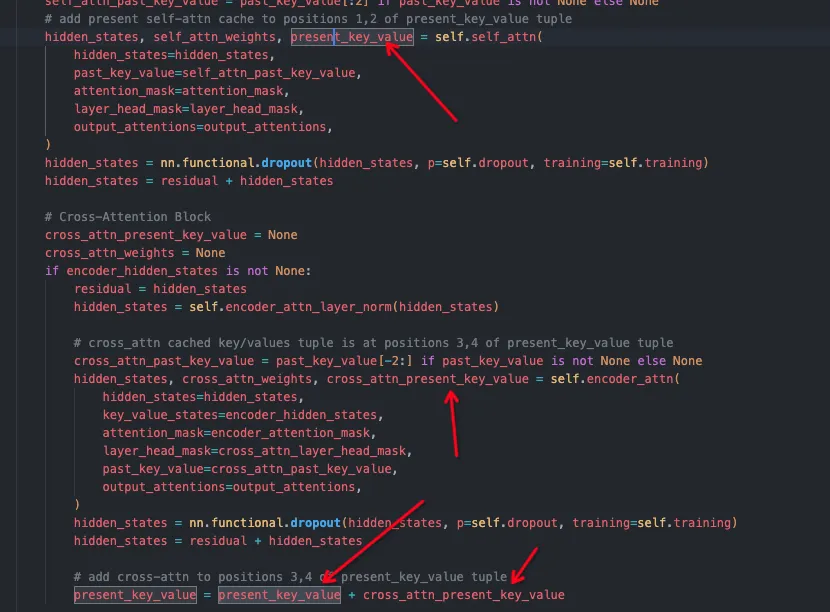
这种结构相对稍微复杂一些。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

部署方案
部署方案的话,我们参考主流开源(TensorRT-LLM不完全开源)框架来窥探下。虽然一些大厂有自己的LLM部署方案,不过技术其实也多是“借鉴”,大同小异。这几个LLM框架应该是用的比较多的:
-
TensorRT-LLM
-
vLLM
-
lmdeploy
目前这三个框架都支持VLM模型,只不过支持程度不同,我们先看trt-llm。
TensorRT-LLM
trt-llm中多模态部分在Multimodal示例中,如果是跑demo或者实际中使用trt-llm的python session跑的话,直接看官方的example即可:
如果我们更进一步,想要部署在生产环境,也是可以搞的。如果我们想要使用triton inference server部署的话,TensorRT-LLM对多模态模型的支持限于将cv-encoder和decoder分离开,搞成两个模型服务。
即通过ensemble或者tensorrt_llm_bls(python backend)的方式串起来,整体运行流程和在普通模型中是一致的(先输入image和text,然后两者经过tokenizer转换为token id,最终拼接和encoder输出特征图一并传入decoder中)。
视觉端
视觉端模型转换和普通CV模型一致,可以通过onnx的方式或者直接通过trt-python-api搭建。
以llava举例子,在TensorRT-LLM中,首先把视觉模型(encoder)使用Wrapper类套一层,其中:
-
self.vision_tower是视觉模型, -
multi_modal_projector是投影层,将特征维度转换为和input_embeds相匹配的维度:
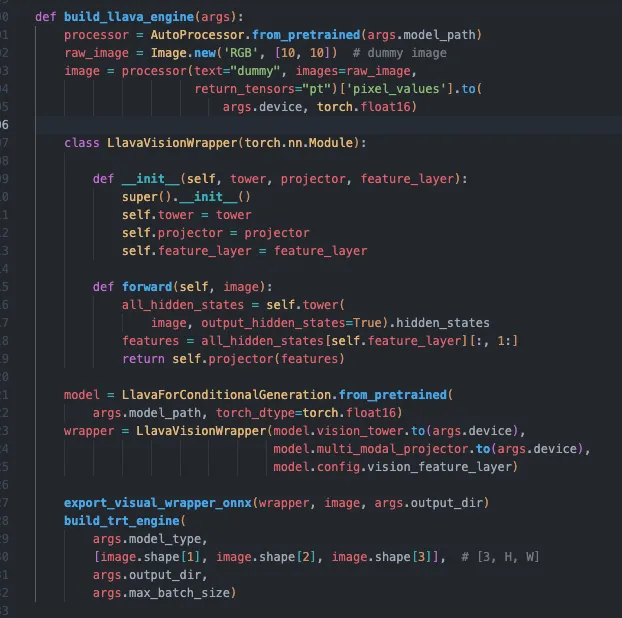
转换好之后,模型信息如下:
[I] ==== TensorRT Engine ====
Name: Unnamed Network 0 | Explicit Batch Engine
---- 1 Engine Input(s) ----
{input [dtype=float16, shape=(-1, 3, 336, 336)]}
---- 1 Engine Output(s) ----
{output [dtype=float16, shape=(-1, 576, 4096)]}
---- Memory ----
Device Memory: 56644608 bytes
---- 1 Profile(s) (2 Tensor(s) Each) ----
- Profile: 0
Tensor: input (Input), Index: 0 | Shapes: min=(1, 3, 336, 336), opt=(2, 3, 336, 336), max=(4, 3, 336, 336)
Tensor: output (Output), Index: 1 | Shape: (-1, 576, 4096)
---- 398 Layer(s) ----
语言端
decoder端需要额外加入一个合并input_ids 和prompt_table_data的embedding层(这里称为PromptTuningEmbedding),其余的和普通llama一致:
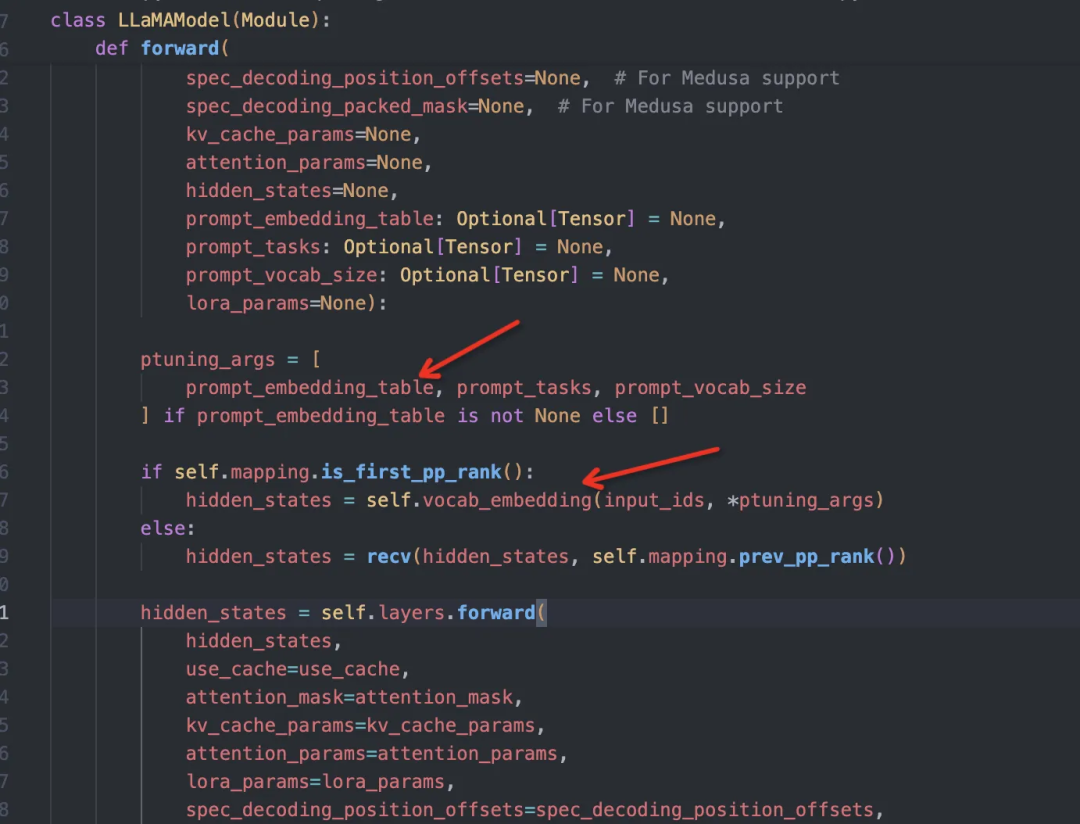
image
通过设置 use_prompt_tuning来确定该decoder是否需要额外的 prompt_tuning 输入:
class LLaMAModel(Module):
def __init__(self,
num_layers,
num_heads,
...# 省略参数
use_prompt_tuning: bool = False, # !!!
enable_pos_shift=False,
dense_context_fmha=False,
max_lora_rank=None):
super().__init__()
self.mapping = mapping
self.use_prompt_tuning = use_prompt_tuning
EmbeddingCls = PromptTuningEmbedding if use_prompt_tuning else Embedding
其中PromptTuningEmbedding的forward代码如下,这个使用trt-python-api搭出来的layer主要作用就是将input_ids和视觉特征prompt_embedding_table进行embed并且concat,和上述一开始提到的concat流程大差不差:
# PromptTuningEmbedding
def forward(self, tokens, prompt_embedding_table, tasks, task_vocab_size):
# do not use '>=' because internally the layer works with floating points
prompt_tokens_mask = tokens > (self.vocab_size - 1)
# clip tokens in the [0, vocab_size) range
normal_tokens = where(prompt_tokens_mask, self.vocab_size - 1, tokens)
normal_embeddings = embedding(normal_tokens, self.weight.value,
self.tp_size, self.tp_group,
self.sharding_dim, self.tp_rank)
# put virtual tokens in the [0, max_prompt_vocab_size) range
prompt_tokens = where(prompt_tokens_mask, tokens - self.vocab_size, 0)
# add offsets to match the concatenated embedding tables
tasks = tasks * task_vocab_size
# tasks: [batch_size, seq_len]
# prompt_tokens: [batch_size, seq_len]
prompt_tokens = prompt_tokens + tasks
prompt_embeddings = embedding(prompt_tokens, prompt_embedding_table)
# prompt_tokens_mask: [batch_size, seq_len] -> [batch_size, seq_len, 1]
# combine the correct sources of embedding: normal/prompt
return where(unsqueeze(prompt_tokens_mask, -1), prompt_embeddings,
normal_embeddings)
服务整合
服务整合其实很容易,只不过官方一开始并没有给出示例,只有在最近才在tutorial中给出实际例子:
- https://github.com/triton-inference-server/tutorials/blob/main/Popular_Models_Guide/Llava1.5/llava_trtllm_guide.md[14]
其实我们可以很早发现tensorrt_llm/config.pbtxt中已经包含了这两个输入:
-
prompt_embedding_table
-
prompt_vocab_size
意味着在trt-llm的executor中包装着decoder-engine,可以接受这两个输入。而trt-llm提供的executor,在triton-trt-llm-backend去通过调用这个API实现inflight batching:

image
# inflight_batcher_llm/tensorrt_llm/config.pbtxt
{
name: 'prompt_embedding_table'
data_type: TYPE_FP16
dims: [ -1, -1 ]
optional: true
allow_ragged_batch: true
},
{
name: 'prompt_vocab_size'
data_type: TYPE_INT32
dims: [ 1 ]
reshape: { shape: [ ] }
optional: true
},
而之前介绍的llava的decoder结构,则可以看到有prompt_embedding_table和prompt_vocab_size这两个输入:
[03/04/2024-03:23:39] [TRT-LLM] [I] Engine:name=Unnamed Network 0, refittable=False, num_layers=495, device_memory_size=1291851264, nb_profiles=1
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=input_ids, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=position_ids, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=prompt_embedding_table, mode=TensorIOMode.INPUT, shape=(-1, 4096), dtype=DataType.HALF, tformat=Row major linear FP16 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=tasks, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=prompt_vocab_size, mode=TensorIOMode.INPUT, shape=(1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=last_token_ids, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=kv_cache_block_offsets, mode=TensorIOMode.INPUT, shape=(-1, 2, -1), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=host_kv_cache_block_offsets, mode=TensorIOMode.INPUT, shape=(-1, 2, -1), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=host_kv_cache_pool_pointers, mode=TensorIOMode.INPUT, shape=(2,), dtype=DataType.INT64, tformat=Row major linear INT8 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=sequence_length, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=host_request_types, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=host_past_key_value_lengths, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=context_lengths, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=host_context_lengths, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=host_max_attention_window_sizes, mode=TensorIOMode.INPUT, shape=(32,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=host_sink_token_length, mode=TensorIOMode.INPUT, shape=(1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=cache_indirection, mode=TensorIOMode.INPUT, shape=(-1, 1, -1), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[03/04/2024-03:23:39] [TRT-LLM] [I] Tensor:name=logits, mode=TensorIOMode.OUTPUT, shape=(-1, 32064), dtype=DataType.FLOAT, tformat=Row major linear FP32 format (kLINEAR)
这是普通decoder-only server中的服务文件组织:
而最终整体的目录文件,我们再多一个encoder文件夹就行,具体我们可以在preprocessing中调用encoder,然后去处理prompt合并,最终通过prompt_embedding_table和prompt_vocab_size送入tensorrt_llm中即可。
不过需要注意,trt-llm不支持cross attention这种多模态的inflight batching,因为在config.pbtxt没有暴露出相关的接口,cross attention这种多模态不需要prompt_embedding_table和prompt_vocab_size,而是需要类似于encoder_output这种原始的图像特征输入,以下是官方nougat模型decoder部分转为trt的结构:
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=input_ids, mode=TensorIOMode.INPUT, shape=(-1, 1), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=position_ids, mode=TensorIOMode.INPUT, shape=(-1, 1), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=encoder_input_lengths, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=encoder_max_input_length, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=encoder_output, mode=TensorIOMode.INPUT, shape=(-1, -1, 1024), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=host_past_key_value_lengths, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=sequence_length, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=context_lengths, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=host_request_types, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=last_token_ids, mode=TensorIOMode.INPUT, shape=(-1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cache_indirection, mode=TensorIOMode.INPUT, shape=(-1, 1, -1), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=host_max_attention_window_sizes, mode=TensorIOMode.INPUT, shape=(10,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=host_sink_token_length, mode=TensorIOMode.INPUT, shape=(1,), dtype=DataType.INT32, tformat=Row major linear INT32 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=past_key_value_0, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_past_key_value_0, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=past_key_value_1, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_past_key_value_1, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=past_key_value_2, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_past_key_value_2, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=past_key_value_3, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_past_key_value_3, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=past_key_value_4, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_past_key_value_4, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=past_key_value_5, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_past_key_value_5, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=past_key_value_6, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_past_key_value_6, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=past_key_value_7, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_past_key_value_7, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=past_key_value_8, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_past_key_value_8, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=past_key_value_9, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_past_key_value_9, mode=TensorIOMode.INPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_kv_cache_gen, mode=TensorIOMode.INPUT, shape=(1,), dtype=DataType.BOOL, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=present_key_value_0, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_present_key_value_0, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=present_key_value_1, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_present_key_value_1, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=present_key_value_2, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_present_key_value_2, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=present_key_value_3, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_present_key_value_3, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=present_key_value_4, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_present_key_value_4, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=present_key_value_5, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_present_key_value_5, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=present_key_value_6, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_present_key_value_6, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=present_key_value_7, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_present_key_value_7, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=present_key_value_8, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_present_key_value_8, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=present_key_value_9, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=cross_present_key_value_9, mode=TensorIOMode.OUTPUT, shape=(-1, 2, 16, -1, 64), dtype=DataType.BF16, tformat=Row major linear INT8 format (kLINEAR)
[04/23/2024-03:56:36] [TRT-LLM] [I] Tensor:name=logits, mode=TensorIOMode.OUTPUT, shape=(-1, 50000), dtype=DataType.FLOAT, tformat=Row major linear FP32 format (kLINEAR)
lmdeploy
lmdeploy对多模态的支持方式也在预料之中,decoder使用自家的turbomind或者pytorch engine去跑,然后cv-encoder端复用原始transformers库中的代码去跑,整理流程和trt-llm中的相似。
vLLM
vllm对多模态模型的支持尚可,官方展示的不是很多,但实际上支持了不少(https://github.com/vllm-project/vllm/issues/4194[15]);而且鉴于vllm的易接入性,自己增加模型还是比较简单的:

image
另外,vLLM近期也在修改相关VLM的架构,正在进行重构[16],以及vllm对vlm的一些后续优化:
-
Make VLMs work with chunked prefill
-
Unify tokenizer & multi-modal processor (so that we can leverage AutoProcessor from transformers)
-
Prefix caching for images
-
Streaming inputs of multi-modal data
简单测试了llava,测试性能在同样fp16的情况下性能不如trt-llm,原因表现可以参考在llama上的对比。
优化点TODO
优化点其实有很多,不过占大头的就是量化[17]。
量化
因为多模态的decoder部分就是普通的decode模型,我们可以复用现有的成熟的量化技术量化decoder部分就可以拿到很大的收益。整个pipeline当中视觉encoder部分的耗时占比一般都很小5%左右,
encoder部分可以按照我们平常的小模型的方式去优化即可,量化也可以上。需要注意的就是量化方法,大模型量化方法很多,需要选对。
The AWQ quantization algorithm is suitable for multi-modal applications since AWQ does not require backpropagation or reconstruction, while GPTQ does. Thus, it has better generalization ability to new modalities and does not overfit to a specific calibration set. We only quantized the language part of the model as it dominates the model size and inference latency. The visual part takes less than 4% of the latency. AWQ outperforms existing methods (RTN, GPTQ) under zero-shot and various few-shot settings, demonstrating the generality of different modalities and in-context learning workloads.
Runtime
还有cv-encoder需要和decoder最好放到一个runtime当中,要不然会有一些冗余的显存拷贝,不过这部分对吞吐影响不大,主要是latency。trt-llm中对enc-dec结构已经做了这样的优化,在trt-llm-0607版本中将这俩放到了同一个runtime中,这里指的是Executor,可以看到多出了一个encoder的model path:
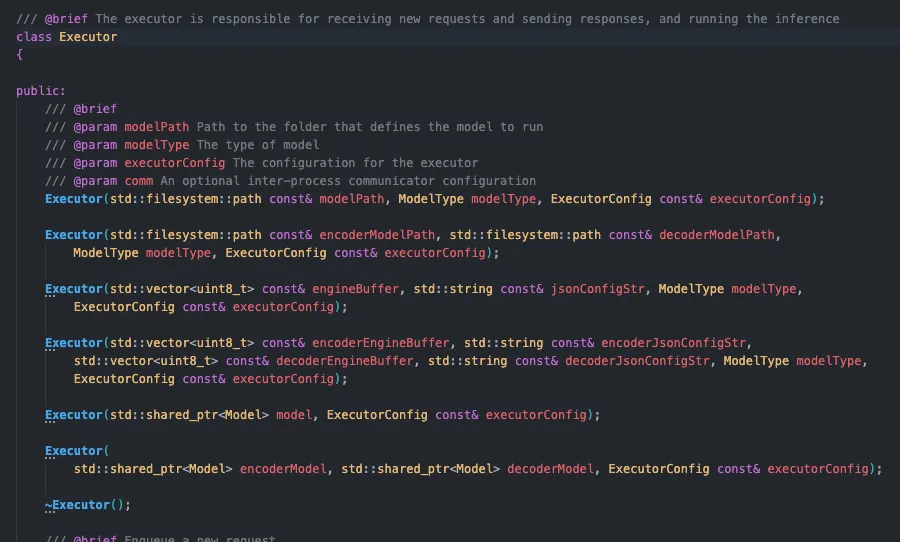
可以看到triton-llm-backend中多了一个encoder_model_path的输入,这里将encoder和decoder放到同一个runtime中了:

还有一些其他的优化空间,这里暂时不谈了,后续有新的结论了再补充。
这里的讨论还不是很全很细,算是抛砖引玉,之后有更新也会再发篇文章单独介绍。各位读者如果有比较好的方法或者建议也欢迎留言,我们一起讨论。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 1132
1132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}