






https://zhuanlan.zhihu.com/p/667865945
https://zhuanlan.zhihu.com/p/653902791
接下来将按照:多模态任务、自监督预训练,经典模型,下游微调这3部分展开:
Multi-Modal Task
多模态上/下游任务:上游训模型,下游做应用。

多模态图像-文本的下游任务主要分为4类:

-
闭集分类:
限定选项/类别的VQA视觉问答、Image-Text Matching图文匹配、NLVR2两图一文匹配、VCR视觉常识推理、Visual Entailment视觉蕴涵

-
开放文本序列生成:
开放文本生成的Visual Captioning视觉描述、Paragreph Captioning段落描述、Open-ended VQA开放域VQA

-
方框/遮罩定位:Groundded Captioning定位描述、REC指向性表达理解(bounding box)、RES指向性表达分割(segment mask)

-
像素预测:T2I文生图、I2I基于文本的图像编辑

目前多模态大模型的发展趋势:
- 上游,用
海量数据多任务 自监督 视觉语言预训练基础模型VLP Foundation Model,统一上述各种图文任务的建模能力。 - 下游,用
特定领域任务的高质量数据微调迁移,然后部署。

自监督预训练
看我知乎的文章:视觉(image)自监督预训练方案总结
基础VLM模型
CLIP (Contrastive Language-Image Pre-training)
基本思想:CLIP的基本算法原理是文本和图像在特征域进行对齐。
模型结构:为了对image和text建立联系,首先分别对image和text进行特征提取,image特征提取的backbone可以是resnet系列模型也可以是VIT系列模型;text特征提取目前一般采用bert模型。特征提取之后,由于做了normalize,直接相乘来计算余弦距离,同一pair对的结果趋近于1,不同pair对的结果趋近于0,因为就可以采用对比损失loss(info-nce-loss)【这里要比较大的batch size才能有效果,类似于维护一个大的特征相似度矩阵】

推理时,利用clip进行图像分类有两种方式,一种是直接利用zero-shot 方式进行预测,如下图所示,将text假设为 a photo of [object], 分别对image 和 text 进行特征提取以及余弦距离,当object为目标类别时,相似度最高,即为预测结果(效果好);还有一种方式就是再重新finetune,同样也是对类别设计几种不同的文本,这样效果能够达到sota的水平!

训练loss:参考对比学习损失,采用了info-nce-loss。
-
交叉熵代价函数(cross entropy):最基础的有监督学习多分类损失函数,gt是n个类别的one-hot编码,目标是最小化gt的one-hot标签和预测logits的负对数乘积在多个类别上的加和,从信息论的角度也就是最小化模型数据分布与训练数据之间的KL散度;

-
NCE(noise contrastive estimation):和交叉熵类似,但是把多分类问题转化成了二分类问题,一个类是数据类别 data sample,另一个类是噪声类别 noisy sample,目标是学习数据样本和噪声样本之间的区别,也就是“噪声对比(noise contrastive)
-
Info-NCE:是NCE的一个简单变体,把噪声样本从一个类别又划分为多个类看待。公式中的temp是一个温度超参数(标量),如果忽略temp,那么infoNCE loss其实就是cross entropy loss,只是在cross entropy loss里,k指代的是数据集里类别的数量,而InfoNCE loss里,k指的是负样本的数量。公式分母中的sum是在1个正样本和k个负样本上做的,做的是一个k+1类的分类任务,目的就是想把query这个图片分到k+这个类。

-
温度系数temperature(本文固定0.07):作用是控制logits的分布形状,对于既定的logits分布的形状,当temp值变大,则(q*k)/temp变小,指数运算之后更小,导致原来的logits分布更平滑。相反,如果temp取得值小,原来的logits分布里的数值就相应的变大,指数运算之后更大,则这个分布变得更集中,更peak。需要取一个合适的数值,既不会对所有的负样本一视同仁,也不会过度关注难样本。

细节:CLIP用了大量的训练数据以及训练资源,大力出奇迹。CLIP用了400million的image-text pair对进行训练,对于image backbone,CLIP尝试了两种结构,DN50x64 和 vit-L,分别用了592 个 V100 + 18天 的时间 和 256 个 V100 + 12天 的时间,非大公司直接劝退。
BLIP的 high level 理解能力比CLIP强:
-
CLIP是Contrastive Pre-training对比学习预训练(图文对比学习,本质是
understanding理解,只有image和text的Encoder的结构)。

-
BLIP是多任务预训练(图文对比学习+图文匹配+文本生成:本质是
understanding理解+generation生成)。不仅有image和text的Encoder,还有text的Decoder。其中text的编码器和解码器都是基于image的(cross attention注入了)。
BLIP(Bootstraping language Image Pre-training)
基本思想:同时兼顾图文理解和图文生成的多模态模型(Multimodal mixture of Encoder-Decoder),同时在三个视觉语言目标上联合预训练:图像文本对比学习ITC、图像文本匹配ITM、图像条件语言建模LM;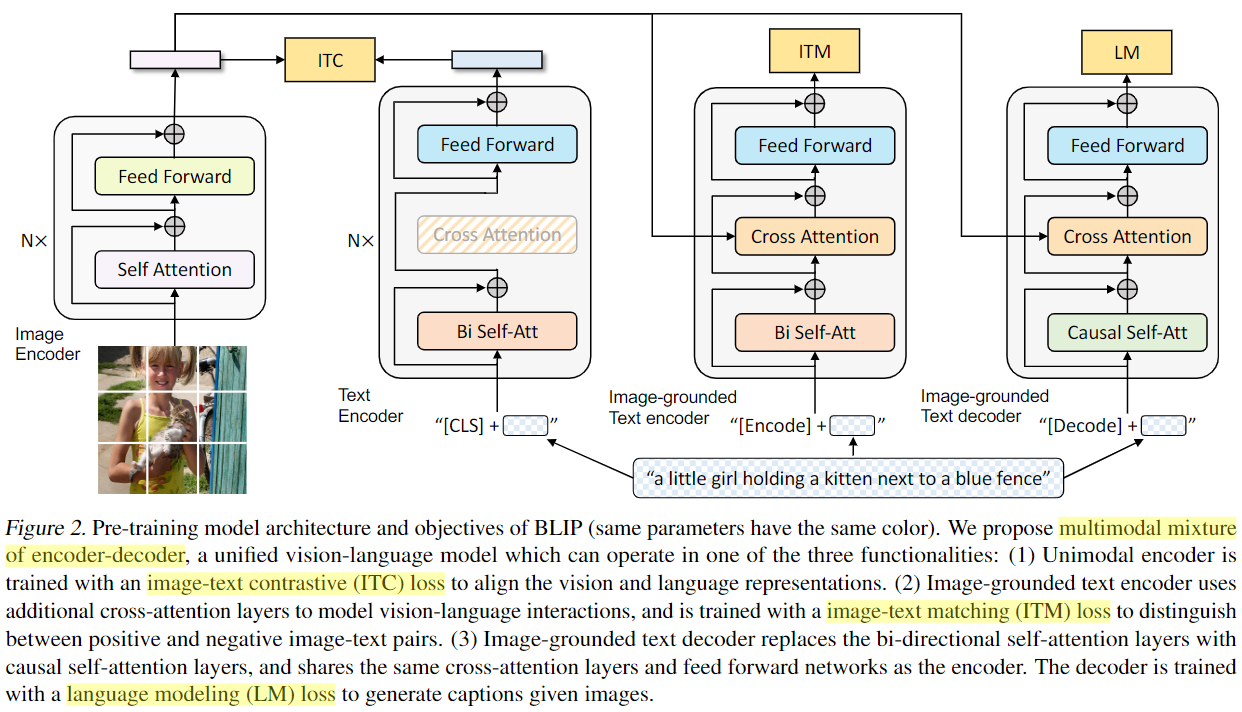
- 理解:图文搜索(只用Image Encoder和Text Encoder)/ 图文匹配(只用Image Encoder和Image-grounded Text Encoder)
- 生成:图文生成(只用只用Image Encoder和Image-grounded Text Decoder)
模型结构:
Image Encoder(ViT):图像打成patches块后进行编码,增加cls token来记录image的全局的特征(作用类似位置编码,保留patches的空间特征)。Text Encoder(BERT):对句子进行编码,增加cls token记录text的全局特征。Image-grounded Text Encoder:在文本embedding中注入了图像特征,通过在self-attention和FFN中间增加一层cross-attention来对齐text-encoder和img-encoder的特征。Image-grounded Text Decoder:用causal self-attention层(预测下一个token)代替了双向自注意力层(建立当前输入token的表达)【和左边的encoder共享除了self-attention之外的层的参数】。
训练loss:预训练阶段同时优化3个loss项,每个图文对只过1次vision-transormer(算力消耗较大),过3次text-transormer
Image-Text Contrastive Loss (ITC)理解功能:(输出图文的相似度)优化vision-transormer + text-transormer,让匹配的图文对有较高相似度的表达(用了soft labels),多模态中的经典loss->使其互信息最大化;Image-Text Matching Loss (ITM)理解功能 :(输出图文是否匹配的True/False)优化Image-grounded text encoder,学习图文的细粒度匹配的二分类,采用了hard negative mining strategy(将ITC任务中容易判断错的样本当作hard negative sample);Language Modeling Loss (LM)生成功能:(生成图像的文本描述)优化image-grounded text decoder,学习如何从给定图生成连贯的文本描述,采用交叉熵代价函数以自回归方式最大化对应文本概率。
采样+过滤机制:同时提出了一种高效利用网络收集的嘈杂图文对的采样+过滤机制。bootstraping翻译成“自举”有点别扭,我还是习惯理解为有放回抽样/迭代优化。首先在包含脏数据的数据集(网上爬取的数据+人工标注的数据)上进行预训练,然后在ITC和ITM任务、LM任务上分别微调,分别得到1个图文匹配的检测模型,1个caption的生成模型。图文匹配的检测模型用于过滤不符合脏数据,caption生成模型对不符合的数据中图像生成caption,再给匹配模型进行检验。
效果:过滤了图文匹配度差的数据、对部分图片生成了更好的文本标注。
VLM系列
模型架构
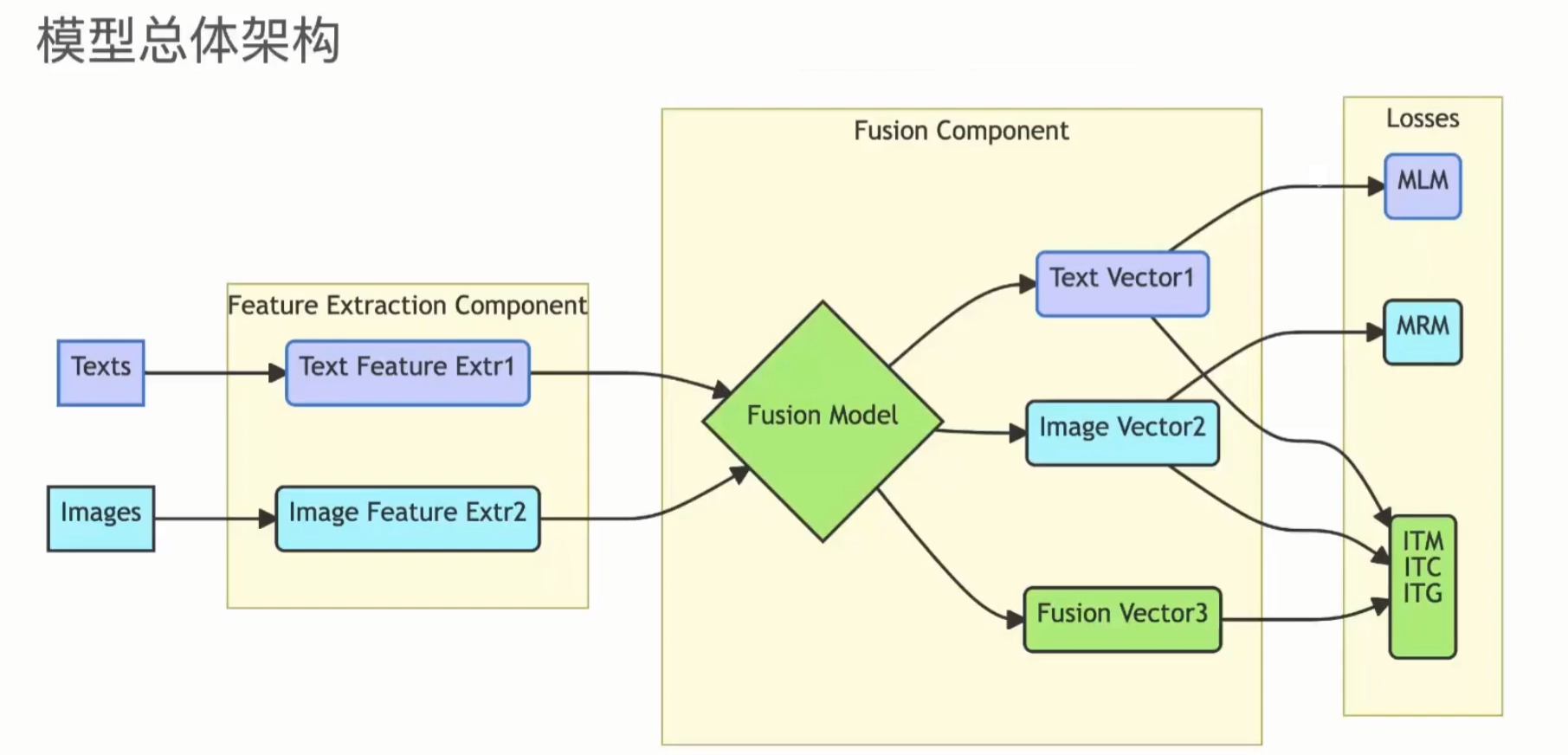
大多数MLM的模型架构分为5个模块:不同模态的Encoder,Input Projector,LLM Backbone,Output Projector,不同模态的Generator。

MLM 微调期间(模态对齐),一般冻结 encoder,LLM Backbone 和 generator。主要微调 较为轻量级的 Input 和 Output 的 Projector,用于连接其他模特和文本模态。MM-LLMs 中可以训练的参数比例和总参数相比非常小(2% 左右),模型的总体参数规模取决于LLM 部分。但有的多模态大模型,也会对 Encoder,甚至 LLM 进行微调,来提升整体的模型的能力。
而相较于更多模态的MLM,视觉+语言的多模态大模型(VLM)架构会更加简单(无需Output Projector 和 不同模态的Generator),目前VLM主流方法是:借助预训练好的大语言模型和图像编码器,用一个图文输入特征对齐模块来连接,从而让语言模型理解图像特征并进行更深层的问答推理。其中Input Projector就是下图的Adapter,主要是3中类型:MLP、Q-Former、XAttn-LLM

训练Loss:
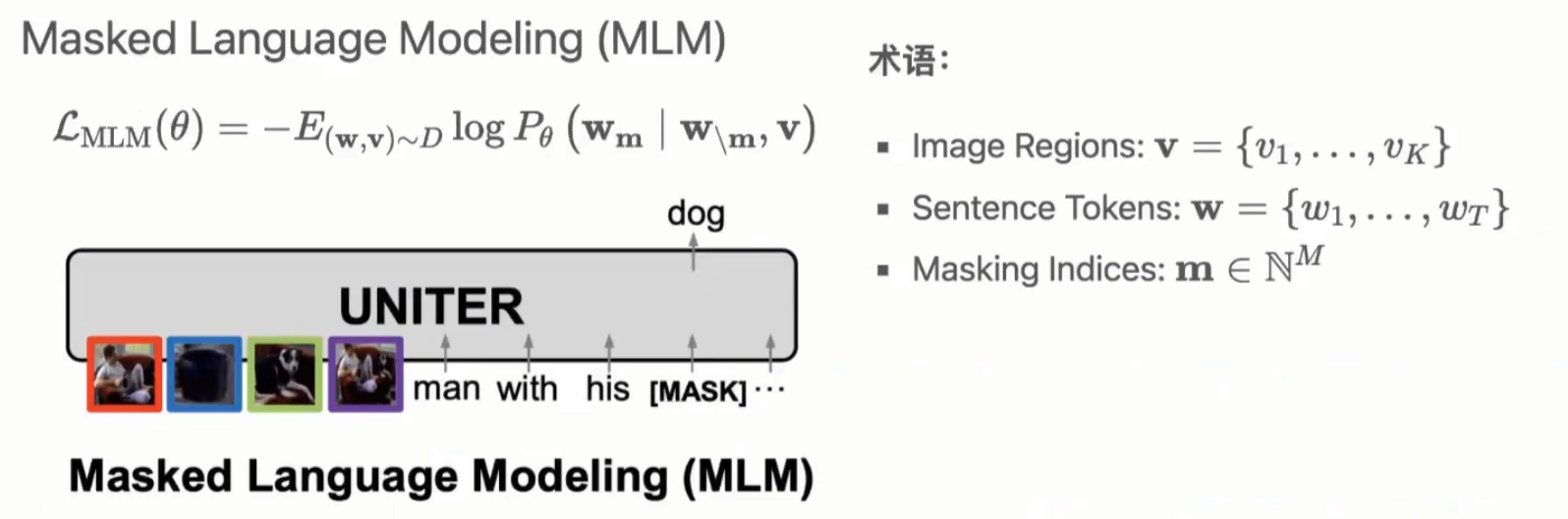
- MLM Loss:掩码语言建模
- MRM Loss:掩码图片建模

- ITM Loss:图文匹配(二分类:是1/否0)

- ITC Loss:图文对比学习(图文相似度)

Modality Encoder
模态编码器主要是对来自不同模态的输入进行编码,来获得相应的特征:
F X = M E X ( I X ) F_X = ME_X(I_X) FX=MEX(IX)
存在各种预训练的编码器来处理不同的模态,模态可以是图像,视频,音频,3D 等。
视觉模态:对于图像,一般有四个可选的编码器,NFNet-F6,ViT,CLIP VIT,EVA-CLIP ViT。对于视频,可以统一采样 5 帧,进行与图像同样的处理。
NFNet-F6:是一个无归一化的 ResNet 网络,可以在增强过的数据集上获得 SOTA 的图像识别的性能。ViT:采用 transformer 模型,将 image 变成 patch,然后对图像进行处理。然后经过线性投影flatten,然后经过多个 transformer 模块。CLIP-VIT:利用大量的文本-图像对,通过对比学习来优化 ViT,将成对的文本图像视为正样本,其他的文本和图像视为负样本。EVA-CLIP:对大规模的 CLIP 训练稳定了训练过程和优化过程。
音频模态:通常使用 C-Former,HuBERT,BEATs 和 Whisper 等进行编码。
- C-Former:使用了 CIF 对齐机制来实现序列的转换,并且使用一个 Transformer 来提取音频特征
- HuBERT:是一个自监督的语音表征徐诶框架,基于 BERT。通过离散hidden units 的mask 预测来实现
- BEAT 是:是一个迭代的音频预训练框架,使用音频 Transformer 来学习双向编码表示
Input Projector
输入 Projecor 的任务是将其他模态的编码特征 F X F_X FX与文本特征空间的特征T进行对齐。对齐后的特征作为prompts P x P_x Px联通文本特征 F T F_T FT输入到 LLM Backbone 内。给定 X 模态-text数据集 { I X , t } \{I_X,t\} {IX,t},目标是最小化生成损失。
输入 Projecor 可以通(多层)MLP来实现。也有复杂的实现,比如 Cross-Attention,Q-Former,P-Former 等。Cross-Attention 使用一系列的可训练的 query 和编码特征
F
X
F_X
FX作为 key 来压缩特征序列到固定的长度。将压缩的表示特征输给 LLM。
LLM Backbone
LLM作为核心智能体,MM-LLMs 可以继承一些显着的属性,如零样本泛化(zero-shot)、少样本 ICL、思想链 (CoT) 和指令遵循。 LLM 主干处理来自各种模态的表示,参与有关输入的语义理解、推理和决策。它产生 (1) 直接文本输出 t,以及 (2) 来自其他模式(如果有)的信号token S x S_x Sx。这些信号token充当指导生成器是否生成 MM 内容的指令,如果是,则指定要生成的内容:
t , S X = L L M ( P X , F T ) t,S_X = LLM(P_X,F_T) t,SX=LLM(PX,FT)
上式中,其他模态 P X P_X PX的对齐后的表征,可以认为是软 prompt-tuning,输给 LLM Backbone。发而且一些研究工作引入了 PEFT 的方法,例如 Prefix-tuning,Adapter 和 LoRA。这些 case 里面,希望更少的参数可以被训练,甚至少于 0.1% 的 LLM 的参数参与训练。
通常用到的 LLM 模型有 Flan-T5,ChatGLM,UL2,Qwen,Chinchilla,OPT,PaLM,LLaMA ,LLaMA2 ,Vicuna 等。
Output Projector
输出Projector将 LLM 的输出的 token 表征 S X S_X SX转变成特征 H X H_X HX,然后输给生成器 M G X MG_X MGX。
给定数据X-text数据集 { I X , t } \{I_X, t\} {IX,t},首先将文本t输给 LLM,生成对应的 S X S_X SX,然后映射得到 H X H_X HX。模型优化的目标是最小化 H X H_X HX与 M G X MG_X MGX的条件文本之间的距离。
Modality Generator
模态生成器 M G X MG_X MGX一般用于生成不同的模态来输出。当前的工作一般使用现成的扩大模型(Latent diffusion model),例如 Stable Diffusion用于图像生成,Zeroscope用于视频生成,AudioLDM-2 用于音频生成。
输出 Projector 输出的特征 H x H_x Hx作为条件输入,在去噪的过程中,用于生成 MM 的内容。训练过程中, gt content 首先转换为 latent feature z 0 z_0 z0,由预训练好的 VQA 模型。然后噪声 ϵ \epsilon ϵ加到 z 0 z_0 z0上,获得 noise latent feature z t z_t zt,预训练好的 UNet 用于计算条件损失,通过最小化 loss 来优化参数。
主流VLM简介


(1) Flamingo。 代表了一系列视觉语言 (VL) 模型,旨在处理交错的视觉数据和文本,生成自由格式的文本作为输出。
(2) BLIP-2 引入了一个资源效率更高的框架,包括用于弥补模态差距的轻量级 Q-Former ,实现对冻结 LLMs 的充分利用。利用 LLMs,BLIP-2 可以使用自然语言提示进行零样本图像到文本的生成。
(3) LLaVA 率先将 IT 技术应用到 MM 领域。为了解决数据稀缺问题,LLaVA 引入了使用 ChatGPT/GPT-4 创建的新型开源 MM 指令跟踪数据集以及 MM 指令跟踪基准 LLaVA-Bench。
(4) MiniGPT-4 提出了一种简化的方法,仅训练一个线性层即可将预训练的视觉编码器与 LLM 对齐。这种有效的方法能够复制 GPT-4 所展示的功能。
(5) mPLUG-Owl提出了一种新颖的 MM-LLMs 模块化训练框架,结合了视觉上下文。为了评估不同模型在 MM 任务中的表现,该框架包含一个名为 OwlEval 的教学评估数据集。
(6) X-LLM 陈等人 扩展到包括音频在内的各种模式,并表现出强大的可扩展性。利用Q-Former的语言可迁移性,X-LLM成功应用于汉藏语境。
(7) VideoChat 开创了一种高效的以聊天为中心的 MM-LLM 用于视频理解对话,为该领域的未来研究制定标准,并为学术界和工业界提供协议。
(8)InstructBLIP 基于预训练的BLIP-2模型进行训练,在MM IT期间仅更新Q-Former。通过引入指令感知的视觉特征提取和相应的指令,该模型使得能够提取灵活多样的特征。
(9) PandaGPT 是一种开创性的通用模型,能够理解 6 不同模式的指令并根据指令采取行动:文本、图像/视频、音频、热、深度和惯性测量单位。
(10) PaLI-X 使用混合 VL 目标和单峰目标进行训练,包括前缀完成和屏蔽令牌完成。事实证明,这种方法对于下游任务结果和在微调设置中实现帕累托前沿都是有效的。
(11) Video-LLaMA 张引入了多分支跨模式PT框架,使LLMs能够在与人类对话的同时同时处理给定视频的视觉和音频内容。该框架使视觉与语言以及音频与语言保持一致。
(12) VideoChatGPT Maaz 等人。 (2023)是专门为视频对话设计的模型,能够通过集成时空视觉表示来生成有关视频的讨论。
(13) Shikra Chen 等人。 (2023d) 介绍了一种简单且统一的预训练 MM-LLM,专为参考对话(涉及图像中区域和对象的讨论的任务)而定制。该模型展示了值得称赞的泛化能力,可以有效处理看不见的设置。
(14) DLP提出 P-Former 来预测理想提示,并在单模态句子数据集上进行训练。这展示了单模态训练增强 MM 学习的可行性。
(15) BuboGPT 是通过学习共享语义空间构建的模型,用于全面理解MM内容。它探索图像、文本和音频等不同模式之间的细粒度关系。 (16)ChatSpot 引入了一种简单而有效的方法来微调 MM-LLM 的精确引用指令,促进细粒度的交互。由图像级和区域级指令组成的精确引用指令的结合增强了多粒度 VL 任务描述的集成。
(17) Qwen-VL 是一个多语言MM-LLM,支持英文和中文。 Qwen-VL 还允许在训练阶段输入多个图像,提高其理解视觉上下文的能力。
(18) NExT-GPT 是一款端到端、通用的any-to-any MM-LLM,支持图像、视频、音频、文本的自由输入输出。它采用轻量级对齐策略,在编码阶段利用以LLM为中心的对齐方式,在解码阶段利用指令跟随对齐方式。
(19) MiniGPT-5 郑等人。是一个 MM-LLM,集成了生成 voken 的反演以及与稳定扩散的集成。它擅长为 MM 生成执行交错 VL 输出。在训练阶段加入无分类器指导可以提高生成质量。
BLIP2
基本思想:如标题所言 Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models,分两个阶段,通过利用预训练好的视觉模型和语言模型来提升多模态效果和降低训练成本。(只训练对齐模块Q-Former,少的训练参数,得到更好的效果)
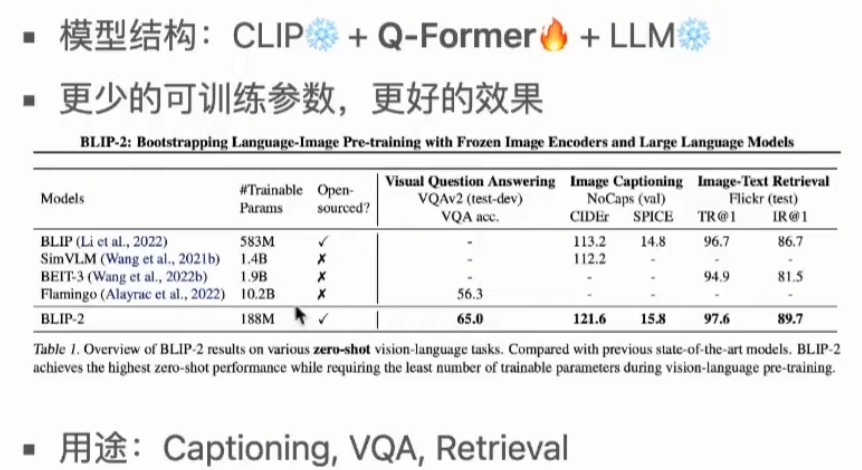
模型结构:BLIP-2 由3部分组成:预训练的Image Encoder,预训练的Large Language Model,和一个可学习的 Q-Former 组成(CLIP + Q-Former + LLM)。
-
Image Encoder:从输入图片中提取视觉特征,尝试了两种网络结构,
CLIP 训练的 ViT-L/14和EVA-CLIP训练的 ViT-g/14(去掉了最后一层)。 -
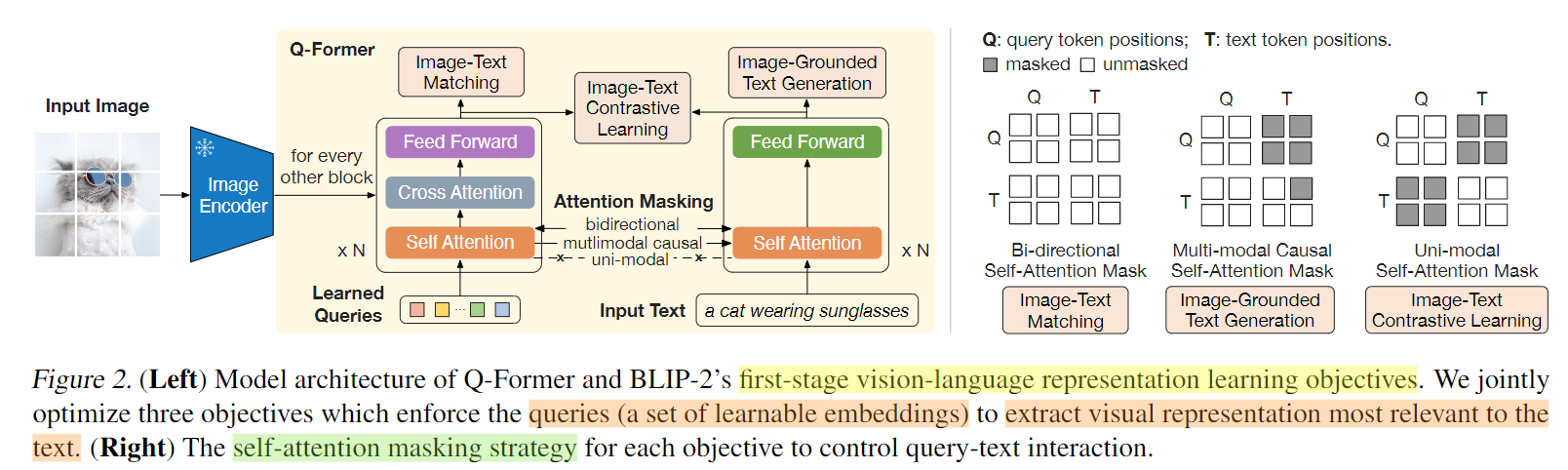
Q-Former:弥补视觉和语言两种模态的modality gap,可以理解为固定图像编码器和固定LLM之间的信息枢纽,
将原始图像特征对齐到文本特征空间,使得可以给LLM来生成文本。其中,Q-Former由Image Transformer和Text Transformer两个子模块构成,它们共享相同自注意力层。- Image Transformer:通过和image encoder交互来提取视觉特征,输入是一系列(文中用的32个x768长度)可学习的 Queries,这些Query通过自注意力层相互交互,并通过交叉注意力层与冻结的图像特征交互,还可以通过共享的自注意力层与文本进行交互;输出的query尺寸是32x768,远小于冻结的图像特征257*1024(ViT-L/14)。
- Text Transformer:既作为文本编码器也作为文本解码器。
- Text Transformer自注意力层与Image Transformer共享参数,是同一个self-attention,QFormer中self-attention的tokens序列是
[learnable query tokens, text tokens],根据预训练任务:用不同的self-attention masks来控制Query和文本的交互方式。
-
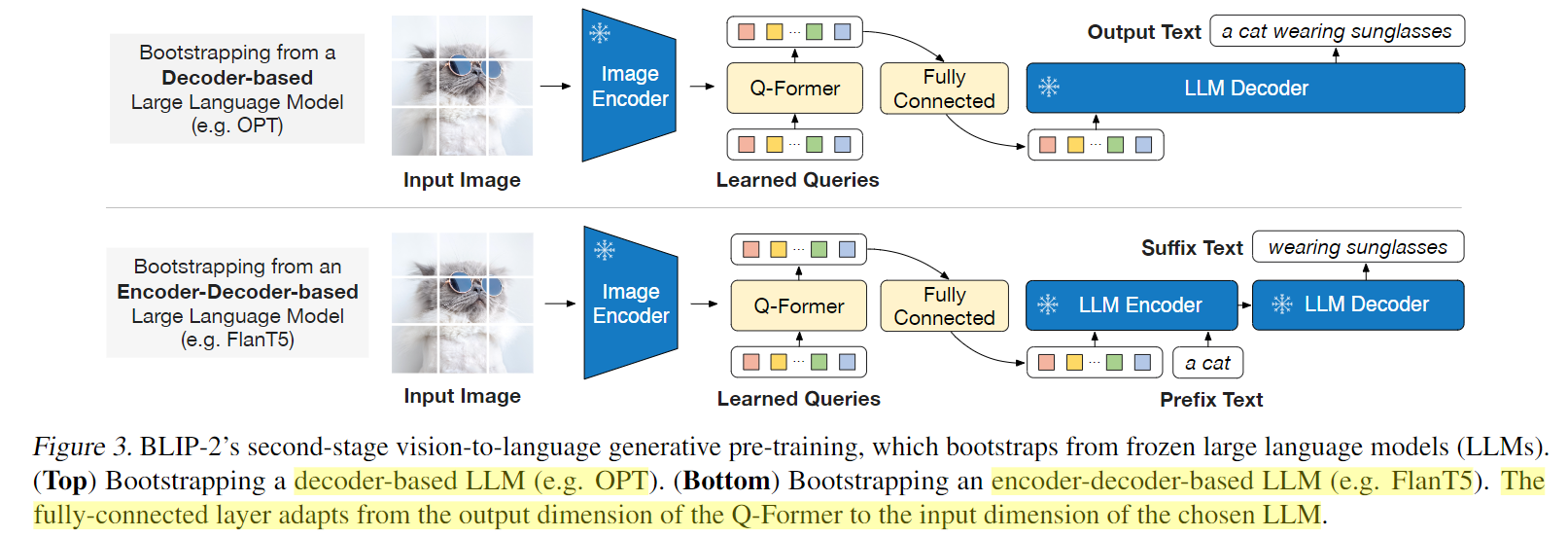
Large Language Model:大语言模型进行文本生成,尝试了接入decoder-based LLM 和 encoder-decoder-based LLM两种结构。
VQA任务微调结构:把文本问题和Q-Former提取的视觉表示一起输入LLM从而得到答案,不过还多了一个把问题也加入了Q-Former的输入,使提取的图像特征和问题更相关。这种方式也用在了他们的下一篇文章InstructBLIP中,用于注入指令进行微调。
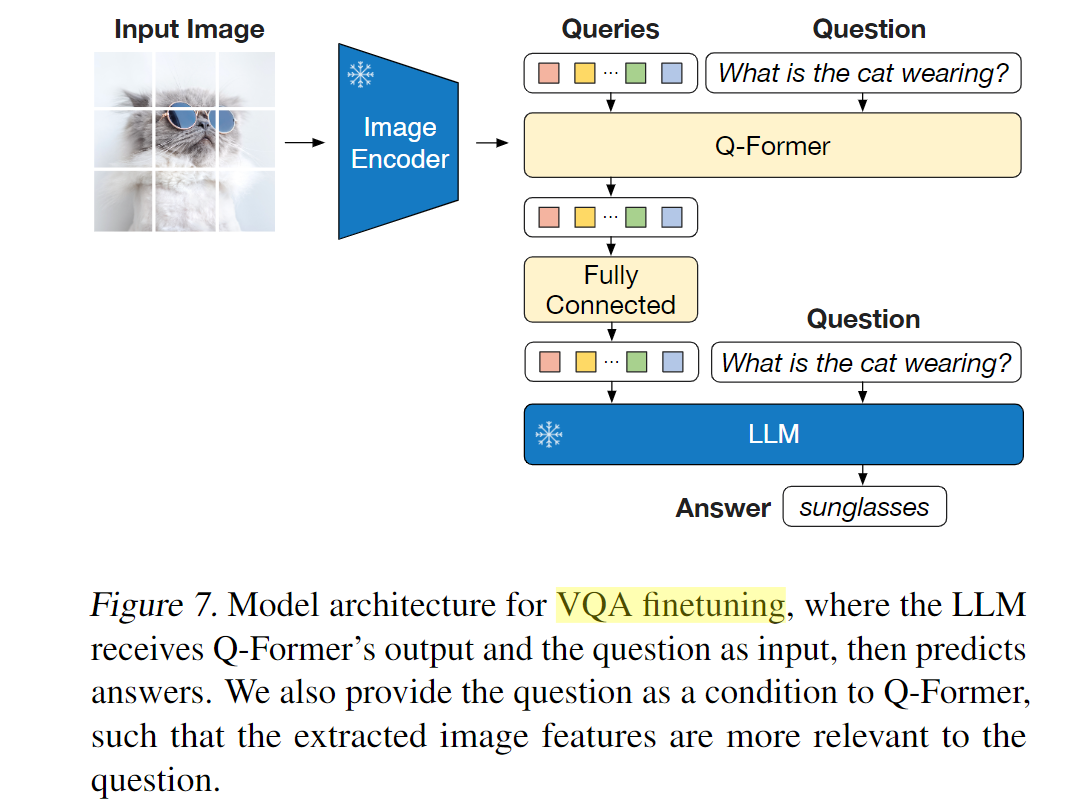
训练过程:
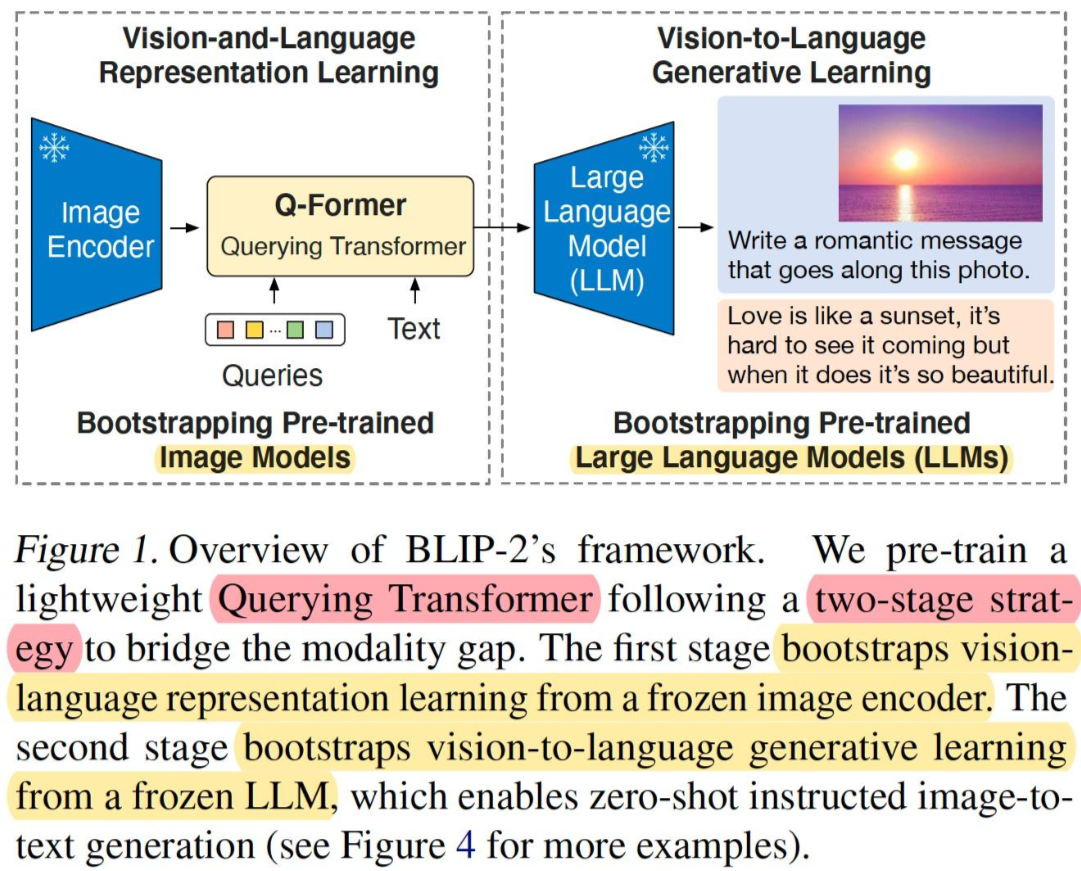
为了减少计算成本并避免灾难性遗忘,BLIP-2 在预训练时冻结预训练图像模型和语言模型,由于简单地冻结预训练模型参数会导致视觉特征和文本特征难以对齐,为此BLIP-2提出两阶段预训练 Q-Former 来弥补modality gap:表示学习阶段和生成学习阶段。
第一个预训练阶段,vision-language表示学习,将 Q-Former 连接到冻结的图像编码器image encoder,目标是Q-Former学习与文本最相关的视觉表示。和BLIP类似,通过联合优化 ITC + ITG + ITM 三个预训练loss,并在Query和Text之间采用不同的注意力掩码策略,从而控制Image Transformer和Text Transformer的交互方式。
- ITC(Image-Text Contrastive Learning):优化目标是对齐图像特征和文本特征,也就是对齐image transformer输出的query representation与来自text transformer输出的text representation。为了避免信息泄漏,ITC采用了单模态自注意掩码,不允许query和text看到对方。计算时先计算每个query与文本embedding之间的相似度,然后选择最高的作为图文相似度。
- ITG(Image-grounded Text Generation):优化目标是给定输入图像作为条件,训练 Q-Former 生成文本,迫使query提取包含所有文本信息的视觉特征。由于 Q-Former 的架构不允许冻结的图像编码器和文本标记之间的直接交互,因此生成文本所需的信息必须首先由query提取,然后通过自注意力层传给text token。ITG采用多模态causal attention mask来控制query和text的交互,query可以相互感知,但不能看见text token,每个text token都可以感知所有query及其前面的text标记【半矩阵,生成式任务的常见做法】。这里将 [CLS] 标记替换为新的 [DEC] 标记,作为第一个文本标记来指示解码任务。
- ITM( Image-Text Matching):优化目标是进行图像和文本表示之间的细粒度对齐,学一个二分类任务,即图像-文本对是正匹配还是负匹配。这里将image transformer输出的每个query嵌入输入到一个二类线性分类器中以获得对应的logit,然后将所有的logit平均,再计算匹配分数。ITM使用双向自注意掩码,所有query和text都可以相互感知。
第二个预训练阶段,vision-to-language生成学习,将 Q-Former 连接到冻结的大语言模型LLM,将 Q-Former 的输出给到冻结的 LLM 来执行视觉到语言的生成学习,目标是训练Q-Former使其输出的视觉表示对LLM可用。
- 使用全连接层将输出的query embedding线性投影到与 LLM 的text embedding相同的维度,然后将投影的query embedding添加到输入text embedding前面。由于 Q-Former 已经过预训练,可以提取包含语言信息的视觉表示,因此它可以有效地充当信息枢纽,将最有用的信息提供给 LLM,同时删除不相关的视觉信息,减轻了 LLM 学习视觉语言对齐的负担【相当于soft visual prompts】。
- 尝试了decoder-based LLM 和 encoder-decoder-based LLM:对于decoder-based LLM,基于language modeling loss进行预训练,用Q-Former提取的视觉表示生成文本描述;对于encoder-decoder-based LLM,基于prefix language modeling loss进行预训练,把前缀和视觉表示一起输入LLM encoder,由LLM decoder生成后续文本。
Flamingo

LLaVA




LLaVA 1.5

miniGPT4


InstructBLIP
mPLUG-owl
CogVLM

下游有监督微调(SFT)
全参数微调(FFT) 对计算资源需求很高,参数高效微调(PEFT)仅微调部分参数 可以在低资源的情况下逼近全参数微调的效果,不仅如此,PEFT还解决了灾难性遗忘问题。由于它不触及原始LLM,模型不会忘记之前学到的信息。
另一种提高模型在各种任务上表现的策略是指令微调(Instruction Tuning)。这涉及到使用示例来训练机器学习模型,展示模型应该如何响应查询。用于微调大型语言模型的数据集必须符合你的指令目的。例如,如果你想提高模型的摘要能力,你应该构建一个包含摘要指令和相关文本的数据集。在翻译任务中,应包含“翻译这段文本”等指令。这些提示有助于让模型以新的专业方式“思考”,并服务于特定任务。
本节主要讲解参数高效微调(PEFT) 的Freeze方法、P-tuning方法、Lora方法、QLora方法。(推荐Lora和QLora)
Freeze方法
Freeze方法指:冻结大部分参数,仅训练少部分参数,这样就可以大大减少显存的占用。
for name, param in model.parameters():
if not any(nd in name for nd in ['layers.27', 'layers.26', 'layers.25']):
param.requires_grad = False
Learnable token方法
-
Perfix-tuning:与Full-finetuning 更新所有参数的方式不同,该方法是在输入 token 之前构造一段任务相关的 learnable virtual tokens 作为 Prefix,然后训练的时候只更新 Prefix 部分的参数,而 Transformer 中的其他部分参数固定。该方法其实和构造 Prompt 类似,只是 Prompt 是人为构造的“显式”的提示,并且无法更新参数,而Prefix 则是可以学习的“隐式”的提示。同时,为了防止直接更新 Prefix 的参数导致训练不稳定的情况,他们在 Prefix 层前面加了 MLP 结构(相当于将Prefix 分解为更小维度的 Input 与 MLP 的组合后输出的结果),训练完成后,只保留 Prefix 的参数。

-
Prompt-tuning:该方法可以看作是 Prefix Tuning 的简化版本,只在输入层加入learnable prompt tokens,每个task单独训练一组prompt tokens,并不需要加入 MLP 进行调整来解决难训练的问题,主要在 T5 预训练模型上做实验。似乎只要预训练模型足够强大,其他的一切都不是问题。作者也做实验说明随着预训练模型参数量的增加,Prompt Tuning的方法会逼近 Fine-tune 的结果。固定预训练参数,为每一个任务额外添加一个或多个 embedding,之后拼接 query 正常输入 LLM,并只训练这些 embedding。左图为单任务全参数微调,右图为 Prompt tuning。

-
P-tuning:P-Tuning 提出将 learnable Prompt tokens 转换为可以learnable的 Embedding 层,对所有task泛化,只是考虑到直接对 Embedding 参数进行优化会存在这样两个挑战:P-Tuning 和 Prefix-Tuning 差不多同时提出,做法其实也有一些相似之处,主要区别在:(1)Prefix Tuning 是将额外的 embedding 加在开头,看起来更像是模仿 Instruction 指令;而 P-Tuning 的位置则不固定。(2)Prefix Tuning 通过在每个 Attention 层都加入 Prefix Embedding 来增加额外的参数,通过 MLP 来初始化;而 P-Tuning 只是在输入的时候加入 Embedding,并通过 LSTM+MLP 来初始化。

-
P-Tuning v2:P-Tuning 的问题是在小参数量模型上表现差。从标题就可以看出,P-Tuning v2 的目标就是要让 Prompt Tuning 能够在不同参数规模的预训练模型、针对不同下游任务的结果上都达到匹敌 全参数Fine-tuning 的结果。相比 Prompt Tuning 和 P-tuning 的方法, P-tuning v2 方法在多层加入了 Prompts tokens 作为输入,带来两个方面的好处:(1)带来更多可学习的参数(从 P-tuning 和 Prompt Tuning 的0.1%增加到0.1%-3%),同时也足够 parameter-efficient。(2)加入到更深层结构中的 Prompt 能给模型预测带来更直接的影响。

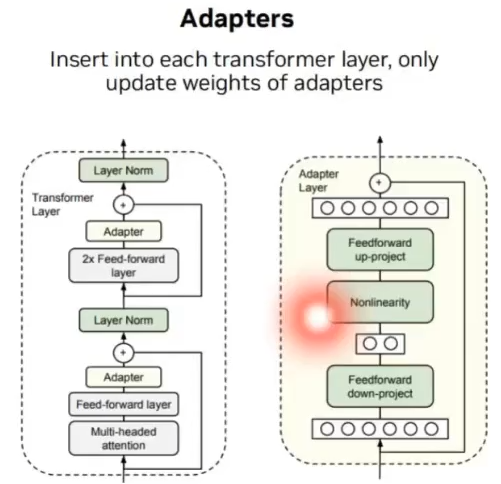
Adapter方法
在Model中插入一些之前没有的layer,即adapter,然后冻结原始model的权重,只微调新加入的layer的权重。
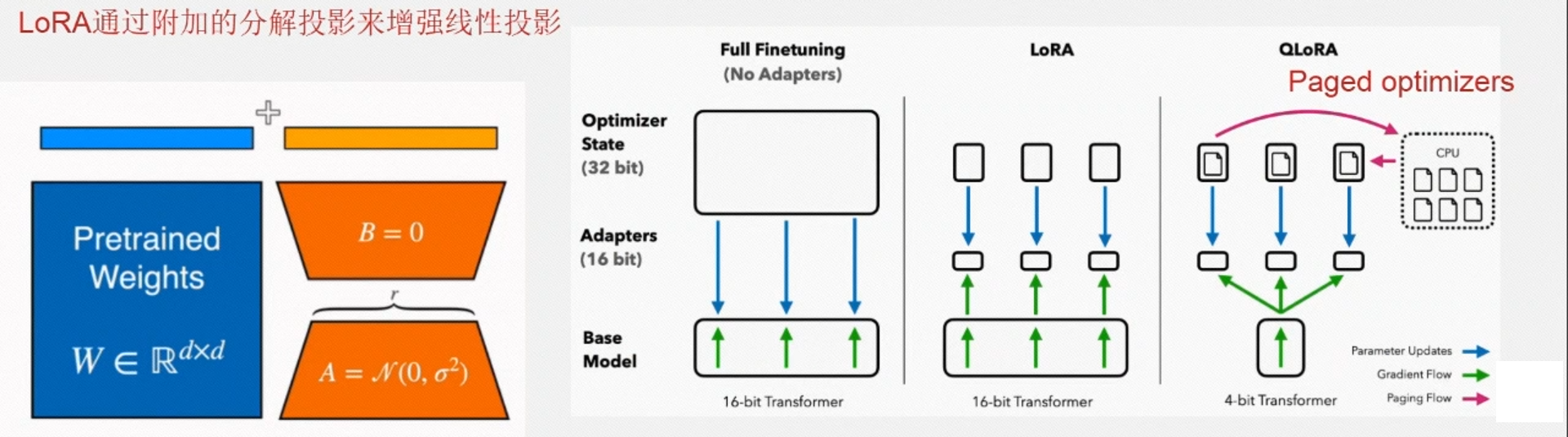
Lora方法
LoRA的本质是在原模型的基础上插入若干的参数,称之为Adapter。在训练时,冻结原始模型的参数,只更新Adapter的参数。对不同的base模型,Adapter的参数量一般是几百万到几千万。
具体来讲,Lora方法指的是在大型语言模型上对指定参数增加额外的低秩矩阵,也就是在原始PLM旁边增加一个旁路,做一个降维再升维的操作。 并在模型训练过程中,固定PLM的参数,只训练降维矩阵A与升维矩阵B,而模型的输入输出维度不变,输出时将BA与PLM的参数叠加,用随机高斯分布初始化A,用0矩阵初始化B,保证训练的开始此旁路矩阵依然是0矩阵。

QLora方法
QLoRA 是由 Tim Dettmers 等人提出的量化 LoRA 的缩写。QLoRA 是一种在微调过程中进一步减少内存占用的技术,原理和Lora类似,只是用了一系列数据压缩的技巧。在反向传播过程中,QLoRA 将预训练的权重量化为 4-bit + 二次量化,并使用分页优化器来处理内存峰值。 使用LoRA时可以节省33%的GPU内存。然而,由于QLoRA中预训练模型权重的额外量化和去量化,训练时间增加了39%。减少数据存储,性能并未下降(对比BF16),NF4存储,BF16计算。
-
4-bit Normal Float:提出一种理论最优的
NF4-bit的量化数据类型,优于当前普遍使用的FP4与Int4。对于正态分布权重而言,一种信息理论上最优的新数据类型,该数据类型对正态分布数据产生比 4 bit整数和 4bit 浮点数更好的实证结果。QLORA包含一种低精度存储数据类型(通常为4-bit)和一种计算数据类型(通常为BFloat16)。在实践中,QLORA权重张量使用时,需要将将张量去量化为BFloat16,然后在16位计算精度下进行矩阵乘法运算。模型本身用4bit加载,训练时把数值反量化到bf16后进行训练。将权重数值映射到以0为中心的[-1,1]正态分布区间的16个数(4位/bit可以代表16个数),即为Normal Float(NF)范围。为什么用0中心的正态分布,因为绝大多数点都接近0。

-
Double Quantization:对第一次量化后的那些常量再进行一次量化,减少存储空间。相比于当前的模型量化方法,更加节省显存空间。每个参数平均节省0.37bit,对于65B的LLaMA模型,大约能节省3GB显存空间。
-
Paged Optimizers:使用NVIDIA统一内存特性,该特性可以在在GPU偶尔OOM的情况下,进行CPU和GPU之间自动分页到分页的传输,以实现无错误的 GPU 处理。该功能的工作方式类似于 CPU 内存和磁盘之间的常规内存分页。使用此功能为优化器状态(Optimizer)分配分页内存,然后在 GPU 内存不足时将其自动卸载到 CPU 内存,并在优化器更新步骤需要时将其加载回 GPU 内存。
-
增加Adapter:4-bit的NormalFloat与Double Quantization,节省了很多空间,但带来了性能损失,作者通过插入更多adapter来弥补这种性能损失。在LoRA中在query和value的全连接层处插入adapter。而QLoRA则在所有全连接层处都插入了adapter,增加了训练参数,弥补精度带来的性能损失。
Lora + MOE方法
由于大模型全量微调时的显存占用过大,LoRA、Adapter、IA
这些参数高效微调(Parameter-Efficient Tuning,简称PEFT)方法便成为了资源有限的机构和研究者微调大模型的标配。PEFT方法的总体思路是冻结住大模型的主干参数,引入一小部分可训练的参数作为适配模块进行训练,以节省模型微调时的显存和参数存储开销。

传统上,LoRA这类适配模块的参数和主干参数一样是稠密的,每个样本上的推理过程都需要用到所有的参数。近来,大模型研究者们为了克服稠密模型的参数效率瓶颈,开始关注以Mistral、DeepSeek MoE为代表的混合专家(Mixure of Experts,简称MoE)模型框架。在该框架下,模型的某个模块(如Transformer的某个FFN层)会存在多组形状相同的权重(称为专家),另外有一个路由模块(Router)接受原始输入、输出各专家的激活权重。
Instruction, In-Context, CoT


普通的Visual Launage Model 和 GPT-4 差在 Instruction Tuning、In-Context Learning、Chain of Thoughts 上:
- VLM 的 Instruction 和LLM类似,只是
input从纯text变为了<image, text>;

- VLM的In-Context上下文示例就是
在原始的LLM示例中插入image;

- VLM的CoT策略是
先人LMM描述image的内容,再让LLM根据text和image生成答案。




















 741
741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











