







1 RNN概述
1.1 需要解决的问题
■对于序列(有序)数据,前面的结果会对后面的状态预测产生影响,顺序不可忽略。
➢时间序列数据:是指在不同时间点上收集到的数据,这类数据反映了某-事物、现象等,随时间的变化状态或程度(百度百科)。
➢其他序列数据:语音、光谱、文字....

传统人工神经网络训练学习只是基于单- -的数据得出结果,没有考虑数据之间的顺序关联。传统神经网络输入和输出都是相互独立,如果针对输入和输出并不独立的问题,如何解决?如何上神经网络也能学习到数据之间的顺序关联呢?

输出的预测结果不只依赖于input ,还依赖于之前的一部分信息,会把它存在memory.

RNN可以看成是,在基础人工神经网络中,对应神经元的输出在下一-时间戳直接作用到自身,即神经元在t时刻的输入,除了该层神经元在该时刻的输出外,还包括其自身王t- 1时刻的输出。
2 RNN基础理论
2.1 RNN的基础结构

基础的神经网络只在层与层之间建立了权连接, RNN最大的不同之处就是在层之间的神经元之间也建立的权连接。
x为输入、为t时刻的状态描述、也是隐层单元、0为输出、y代表样本给出的确定值,L为损失函数
标准RNN的特点:
1、权值共享,图中的W全是相同的, U和V也- -样。
2、每一个输入值都只与它本身的那条路线建立权连接,不会和别的神经元连接。
2.2 RNN的基础结构的变种
双向RNN
- 有些情况下,当前的输出不只依赖之前的序列元素,还可能依赖之后的序列元素。
- 比如完形填空,剔掉部分词,让你补全。
- 直观理解:双向RNN叠加

深层双向RNN
- 和双向RNN的区别是每一步/每 个时间点我们设定多层结构。

2.3 RNN结构类型
( 1)一个输入对应一个输出( each to each )


输入输出是一个等长序列,每一个输入都有一 个对应输出。例如股票预测中的RNN,输入是前N天的24小时的价格走势,输出明天的24小时的股市价格走势。
(2)多输入单输出(manytoone)


输入是一个序列,输出只有一个状态。比如一个人说了一句话,判断这个人说的话带有的感情色彩是积极的还是消极的。
(3)单输入多输出( one to many )


输入只有一个,输出是一个序列。比如图片描述,输入为一-张图片,然后生成对图片描述的一段话或文字。
( 4)多输入多输出( many to many )


输入与输出都是长序列。比如在语言翻译中,给出一-段英文,然后要求其翻译成中文。
(5)单输入单输出(onetoone)


输入与输出都只有一个。比如用于自动美颜的RNN ,输入是一-张图片,输出是一张图片。
2.4 RNN应用
RNN有趣应用
- 语音识别:输入的语音数据,生成相应的语音文本信息。比如微信的语音转文字功能。
- 机器翻译:不同语言之间的相互转换。像有道翻译、腾讯翻译官等。
- 音乐生成:使用RNN网络生成音乐,一般会用到RNN中的LSTM算法(该算法可以解决RNN网络中相距较远的节点梯度消失的问题)。
- 文本生成:利用RNN亦可以生成某种风格的文字。
- 情感分类:输入文本或者语音的评论数据,输出相应的打分数据。
- DNA序列分析:输入的DNA序列,输出蛋白质表达的子序列。
- 视频行为识别:识别输入的视频帧序列中的人物行为。
- 实体名字识别:从文本中识别实体的名字。
3 RNN的工作过程
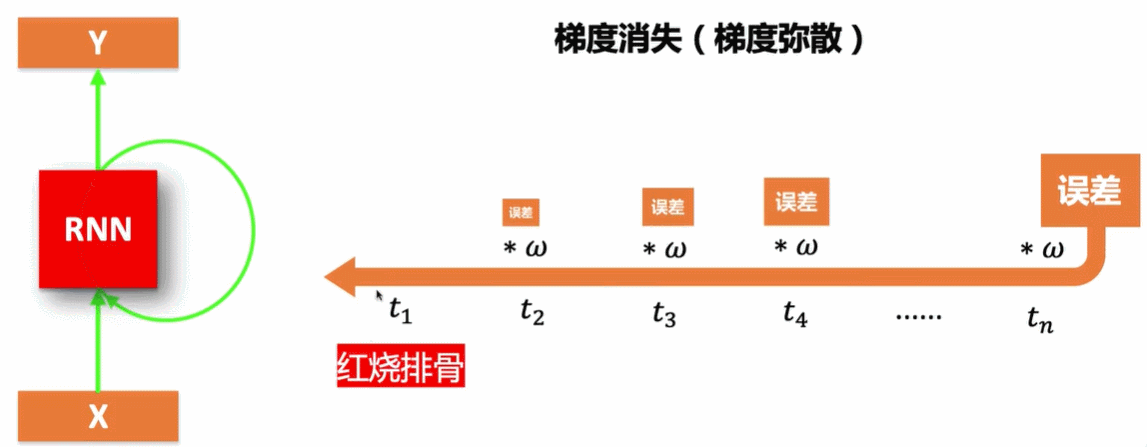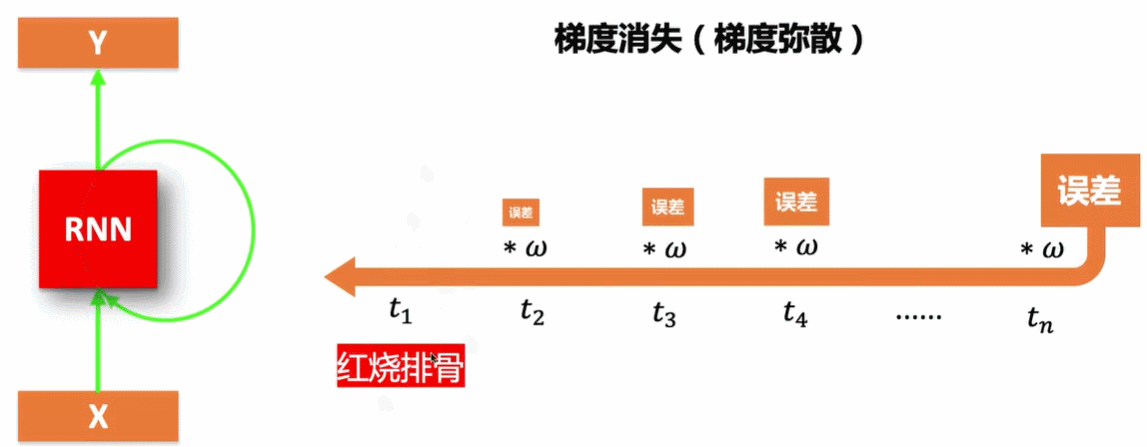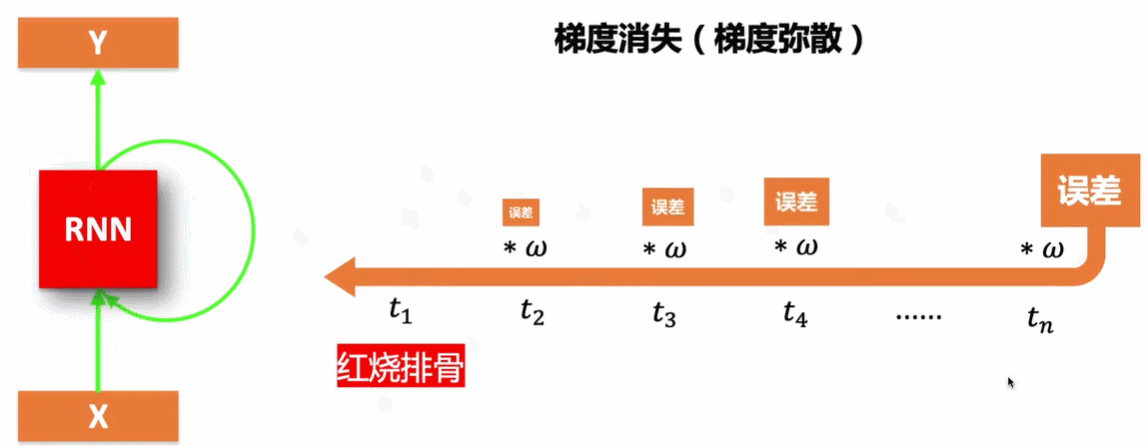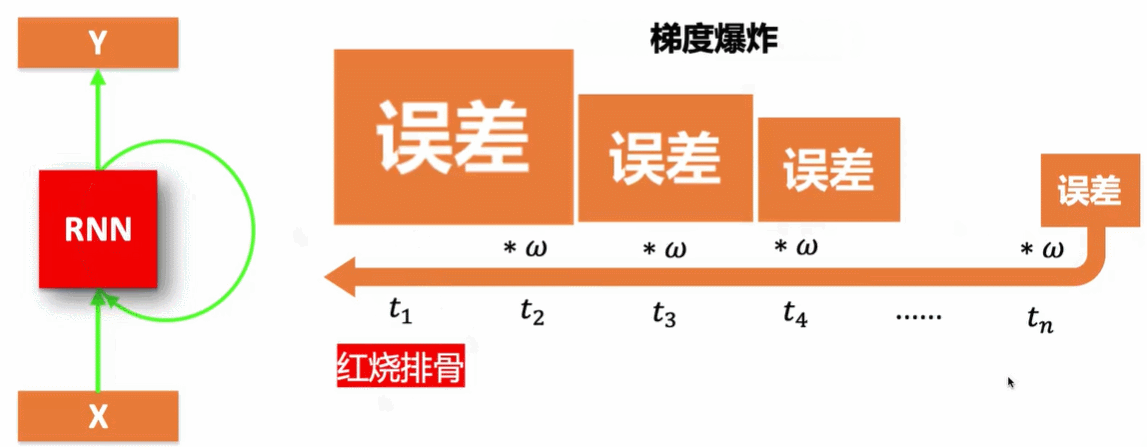
3.1 RNN的弊端——长期依赖问题
RNN网络会出现梯度消散和现误差爆炸,如果通过长序列训练误差是会传递的,若误差是0.9通过相乘误差会接近于0,若误差是1.1,通过相乘误差会很大。
4 长短时记忆网络LSML
4.1 LSML概述
长短时记忆网络(LSTM) ,是- -种RNN特殊的类型,可以学习长期依赖信息。LSTM相比于普通的RNN ,多出了三个控制器:输入控制、输出控制和遗忘控制。



4.2 细胞状态
细胞状态类似于传送带。直接在整个链上运行,只有一-些少量的线性交互。信息在上面流传保持不变会很容易。

- LSTM通过“门”的结构来去除或者增加信息到细胞状态的能力。
- 门是一种让信息选择式通过的方法。他们包含-个sigmoid神经网络层和一个pointwise乘法操作。
- Sigmoid层输出0到1之间的数值描述每 个部分有多少量可以通过。 0代表 "不许任何量通过”, 1就指“充许任意量通过" !
4.3 LSTM的控制门

- 遗忘门( forget gate )决定上一时刻的单元状态Ct-1有多少保留到当前时刻Ct
- 输入门( input gate )决定当前时刻网络的输入x有多少保存到单元状态Ct
- 输出门( output gate )控制单元状态C&有多少输出到LSTM的当前输出值ht
4.4 逐步理解LSTM
- 第1步:决定从"细胞状态”中"遗忘”什么信息一- "遗忘门”
- 比如此时的分线剧情改变了我们对之前剧情的想法,那么遗忘控制就会将之前的某些主线剧情忘记,按-定比例替换成现在的新剧情,主线剧情的更新就取决于输入和遗忘门控制。

- 第2步:决定放什么信息到“细胞状态"中
①sigmoid层称"输入门层” 决定什么值我们将要更新
②tanh层创建一个新的候选值向量
前两步(第1,2步)为“细胞状态”更新做准备

- 第3步:更新“细胞状态”, 即更新
到
①把旧状态与ft相乘,丢弃掉我们确定需要丢弃的信息
②加上,这就是新的候选值,根据我们决定更新每个状态的程度进行变化

- 第4步:基于“细胞状态”得到输出
①首先运行一个sigmiod层来确定细胞状态的哪一 个部分将输出
②接着用tanh处理细胞状态(得到一个在-1到1之间的值 ) , 再将它和sigmoid门的输出相乘,输出我们确定输出的那部分

4.5 LSTM总结

- 遗忘门( forget gate )决定上- -时刻的单元状态Ct- 1有多少保留到当前时刻Ct
- 输入门( input gate )决定当前时刻网络的输入x有多少保存到单元状态Ct
- 输出门( output gate )控制单元状态Ct有多少输出到LSTM的当前输出值ht
4.6 LSTM变种
变种1
➢增加了"peephole connection"窥视孔连接
➢让门层也会接受细胞状态的输入

变种2
➢通过使用coupled忘记和输入门
➢不同于之前是分开确定什么忘记和需要添加什么新的信息,这里是- -同做出决定
变种3——Gated Recurrent Unit (GRU) (由Cho, et al. (2014)提出)
➢将忘记门和输入门J合成了一个单- -的更新门
➢同样还混合了细胞状态和隐藏状态,和其他一-些改动

GRU只有两个门,分别为更新门和重置门,即图中的zt和rt ,更新[ ]用于控制前一-时刻的状态信息被带入到当前状态中的程度,更新]的值越大说明前一-时刻的状态信息带入越少。重置门用于控制忽略前- -时刻的状态信息的程度,重置门]的值越小说明忽略得越多。
LSTM其他变种
➢Yao, et al. (2015)提出的Depth Gated RNN
➢Koutnik, et al. (2014)提出的Clockwork RNN
➢Greff, et al. (2015)给出了流行变体的比较
➢Jozefowicz, et al. (2015)对RNN架构的测试
5 LSTM的Keras实战
时序预测问题的数据(X)和标签( Y )分别是什么?
数据是历史序列v(-n)...v(t-1)
标签是待预测的值v(t)

5.1 实战案例

单步预测:历史序列v(-n....v(t-1)是真实值;待预测的值v(t);逐点推进,每次都是使用真实值
多步预测:历史序列v(t-n)...v(t-1)是真实值;待预测的值v(t) , v(t+ 1)...v(t+ m);预测多步时加入之前的预测值
5.2 准备数据
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
dataSize= 2000; #数据
valSize=200; #测试集个数
testSize=200; #验证集个数
t = np.linspace(0, 100, dataSize) #从0到100中均匀地取100个值
y = np.sin(t)
plt.plot(t[:-valSize-testSize] ,y[:-valSize- -testSize],"b.")
plt. plot(t [-valSize- -testSize:-testSize] ,y [-valSize- -testSize:-testSize],"g.")
plt.plot(t [-testSize:],y[-testSize:],"r.")
plt. show( )结果:

5.2 数据准备——滑动窗口
window_len=10
seq_y=rolling_window(y,window_len) #滑窗函数提取段的值
print(seq_y.shape)
#训练集
trainX=seq_y[:-valSize-testSize--1] #提取测试集数据
trainY=y[window_len:-valSize-testSize] #提取标签
print(trainX.shape)
print(trainY.shape)
#验证集
valX=seq_y[-valSize-testSize-1:-testSize-1]
valY=y[-valSize-testSize:-testSize]
print(valX.shape)
print(valY.shape)
#测试集
testX=seq_y[-testSize-1:-1]
testY=y[-testSize:]
print(testX.shape)
print(testY.shape)5.3 LSTM模型
LSTM输入训练数据shape : [序列数量(样本数量)、序列长度(窗口大小)、特征维度]
#将训练集数据从两个维度变为三个维度
trainX=trainX.reshape(trainX.shape[0],trainX.shape[1],1)
valX=valX.reshape(valX.shape[0],valX.shape[1],1)
testX=testX.reshape(testX.shape[0],testX.shape[1],1)
print(trainX.shape)
print(valX.shape)
print(testX.shape)
from keras.models import Model
from keras.layers import Input, Dense,LSTM
from keras.callbacks import ReduceLROnPlateau,ModelCheckpoint , EarlyStopping
from keras.models import load_model
inp=Input(shape=(trainX.shape[1],trainX.shape[2])) #输入序列长度shape1和特征维度shape2
x=LSTM(50,return_sequences=True)(inp) #50个神经元的LSTM
x=LSTM(100,return_sequences=False)(x) #100个神经元的LSTM,不需要输出隐含层序列:return_sequences=False
x=Dense(1,activation='linear',name='regression')(x) #预测输出只有1个,线性激活函数linear(回归值)
model=Model(inp,x) #定义模型
model.compile(optimizer='rmsprop',loss='mse') #模型编译,使用rmsprop做优化器,用mse做误差值
model.summary()

5.4 模型训练
#=======模型训练========
modelfilepath='model.best.hdf5' #定义最好模型的名字
#定义自动结束
earlyStop=EarlyStopping(monitor='val_loss', #监视误差
patience=20,
verbose=1,
mode='auto')
#保存最好的
checkpoint=ModelCheckpoint(modelfilepath,
monitor='val_loss',
verbose=1,
save_best_only=True,
mode='auto')
#改变学习率
reduce_lr=ReduceLROnPlateau(monitor='val_loss',
factor=0.1,
patience=10,
verbose=1,
mode='auto',
min_delta=0.00001,
c00ldown=0,
min_lr=0)
history=model.fit(trainX,
trainY,
validation_data=(valX,valY),#由于需要预测,我们需要制定验证集
epochs=50, #迭代50次
batch_size=32,
callbacks=[checkpoint,reduce_lr,earlyStop])
#测试
testmodel=load_model(modelfilepath)
result_train=testmodel.predict(trainX)
result_va1=testmodel.predict(valX)
result_test=testmodel.predict(testX)
#显示
t=np.linspace(0,100,dataSize)
y=np.sin(t)
plt.plot(t[:-valSize-testSize],y[:-valSize-testSize],"b")
plt.plot(t[-valSize-testSize:-testSize],y[-valSize-testSize:-testSize,"g")
plt.plot(t[-testSize:],y[-testSize:],"r")
#plt.plot(t[window_len:-valSize-testSize],result_train,"k")#训练集结果
#plt.plot(t[-valSize-testSize:-testSize],result_val,"k") #验证集集结果
#plt.plot(t[-testSize:],result_test,"k") #测试集结果
plt.show()














 5836
5836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









