









Table of Contents
本文是参考腾讯课堂fox老师的课程而写的笔记
一、 Paxos算法
Paxos算法是莱斯利·兰伯特(英语:Leslie Lamport,LaTeX中的“La”)于1990年提出的一种基于消息传递且具有高度容错特性的一致性算法。用于解决在多个节点间确定一个值。
例如这样的场景:
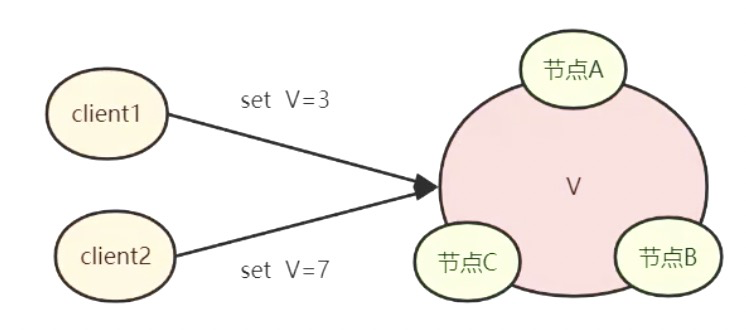
节点A、B、C是如何就V的值达成共识的。
Paxos算法包含2个部分:
- Basic Paxos算法,描述的是多个节点之间如何就某个值(提案value)达成共识。
- Multi-Paxos思想,注意Multi-Paxos是一种思想,而不是一种算法。Multi-Paxos算法是一个统称,它是指基于Multi-Paxos思想,通过执行多个Basic Paxos实例,实现一系列值的共识的算法。
相比而言,Basic Paxos协议更加复杂,且相对效率较低,所以现在所有和paxos有关的协议,一定是基于Multi-paxos来实现的。
名词解释:
提案:可以理解成一个指令,比如set V=3,指令有个版本号,对应提案编号,这个提案编号需要客户端使用一个算法生成。
Paxos算法中的角色:
提议者(Proposer): 提议一个值,用于投票表决
接受者(Acceptor):对每个提议的值进行投票,并存储接收的值
学习者(Leaner) : 被告知投票的结果。接收达成共识的值。存储保存,不参与投票的过程。一般来说,学习者是数据备份的节点,比如Mater-Slave模型中的slave,被动的接收数据,用于存储备份。
Paxos算法达成共识过程:
Paxos算法实现多个节点间达成共识的过程分为两个阶段:准备阶段、接受阶段
准备阶段:
包括 客户端发送"准备请求",接受者响应"准备响应"
1、
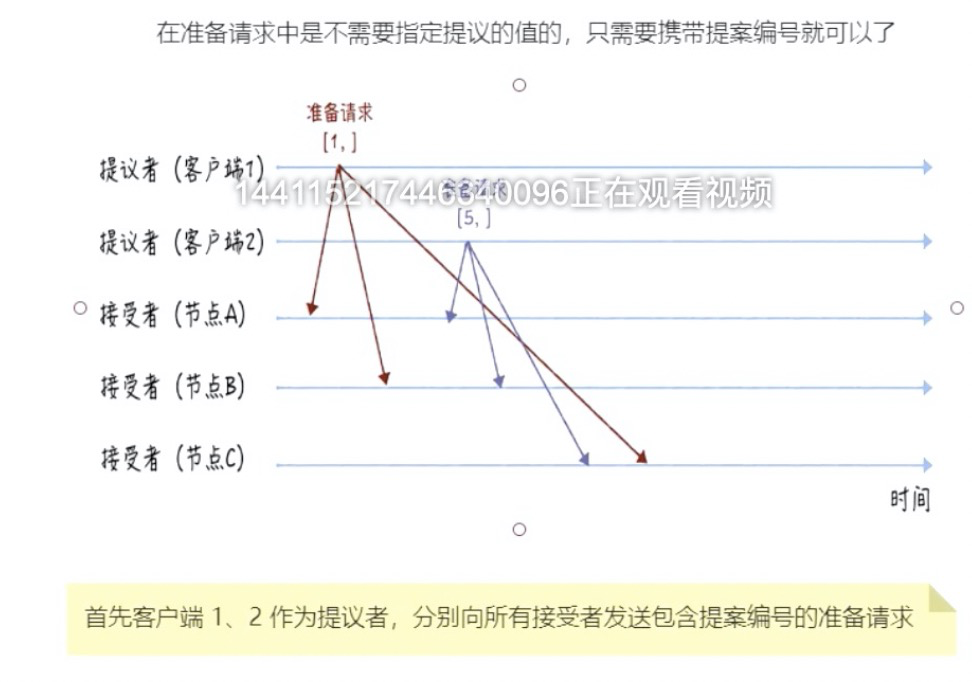
2、

3、

Acceptor的响应规则总结:
- 如果Acceptor之前没有响应任何提案,返回一个尚无提案的响应;如果准备请求的提案编号,小于等于Acceptor已经响应过的准备请求的提案编号,那么将承诺不响应这个准备请求
- 如果接受请求的提案编号,小于Acceptor已经响应的准备请求的提案编号,那么将承诺不通过这个提案
- 如果Acceptor之前有通过提案,那么Acceptor将承诺,会在准备请求的响应中,包含已经通过的最大编号的提案信息。
接受阶段:
包括 客户端发送"接受请求",接受者响应"接受响应"
1、
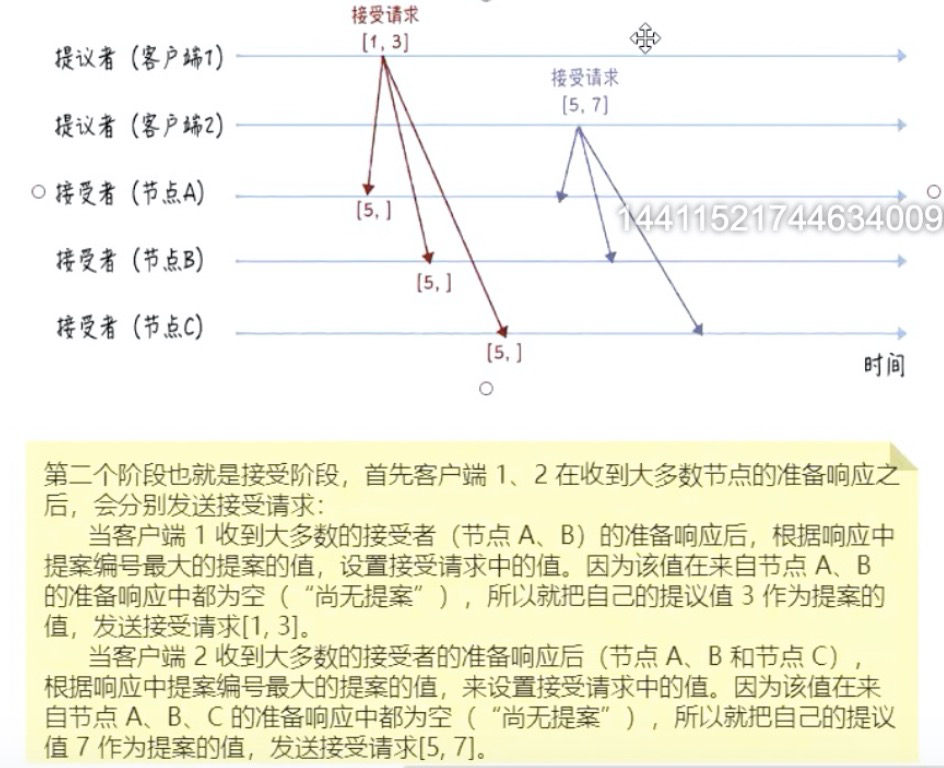
2、

客户端发送"接受请求"的条件:
- client获得大多数(超过半数)节点的准备阶段的响应(只要有响应即可,无论这个响应是否是"尚无提案"的响应)
- 发送的提案的值,如果尚无提案,就是自身的提案值,如果有过提案,提案值是准备阶段的响应返回的最大提案编号的值。
存在问题:
客户端在获得大多数的准备阶段的响应后,才发送"接受请求",存在这样一种情况:有5个节点,3个客户端,3个客户端收到的响应分别为1, 2, 2个,这样每个客户端都无法在发送"接受请求"。这是只能多次执行Basic Paxos实例,来实现一系列值的共识。
但是客户端和接受者之间通讯是一个rpc远程调用,多次的执行Basic Paxos实例,就会导致往返消息多、耗性能、延迟大,延迟一直是分布式的痛点,是需要我们在开发分布式系统中认真考虑的。
那么有没有更好的方式解决这个问题呢?
比如:选择一个leader,来决定共识,于是有了下面Raft算法
二、Raft算法
Raft官网:https://raft.github.io/
http://thesecretlivesofdata.com/raft/
Raft算法是在Multi-Paxos思想的基础上,做了一些简化和限制,比如增加了日志必须是连续的,在理解和算法实现上都相对容易许多。
Raft算法是现在分布式系统开发首选的共识算法。
从本质上说,Raft算法是通过一切以领导者为准的方式,实现一系列值的共识和各节点日志的一致。Raft算法是强领导者模型,集群中只能有一个"霸道总裁"。
Raft算法支持三种状态:
领导者(Leader): 工作内容包括3部分,处理写请求、管理日志复制、不断地发送心跳信息。心跳信息实际上是延迟跟随者的过期时间,从而实现告诉跟随者“我是领导者,我还活着”。
跟随者(Follower): 接收处理来自领导者的消息,当等待领导者心跳信息超时的时候,就主动站出来,推荐自己当候选人
候选人(Candidate): 向其他节点发送请求通票(RequestVote)RPC消息,通知其他节点来投票,如果赢得了大多数选票,就晋升当领导者。
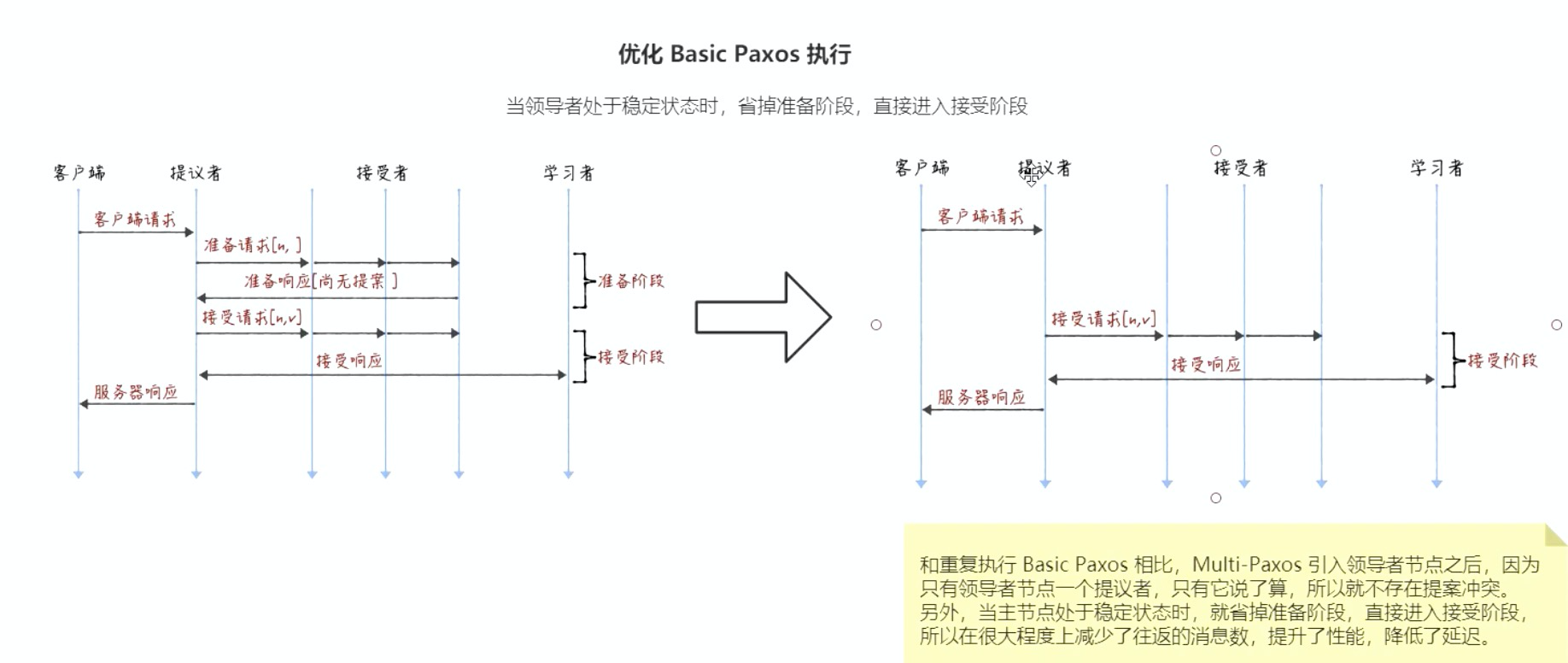
Raft算法优化了Basic Paxos的执行:
当领导者处于稳定状态时,省略掉准备阶段,直接进入接受阶段
选举领导者的过程
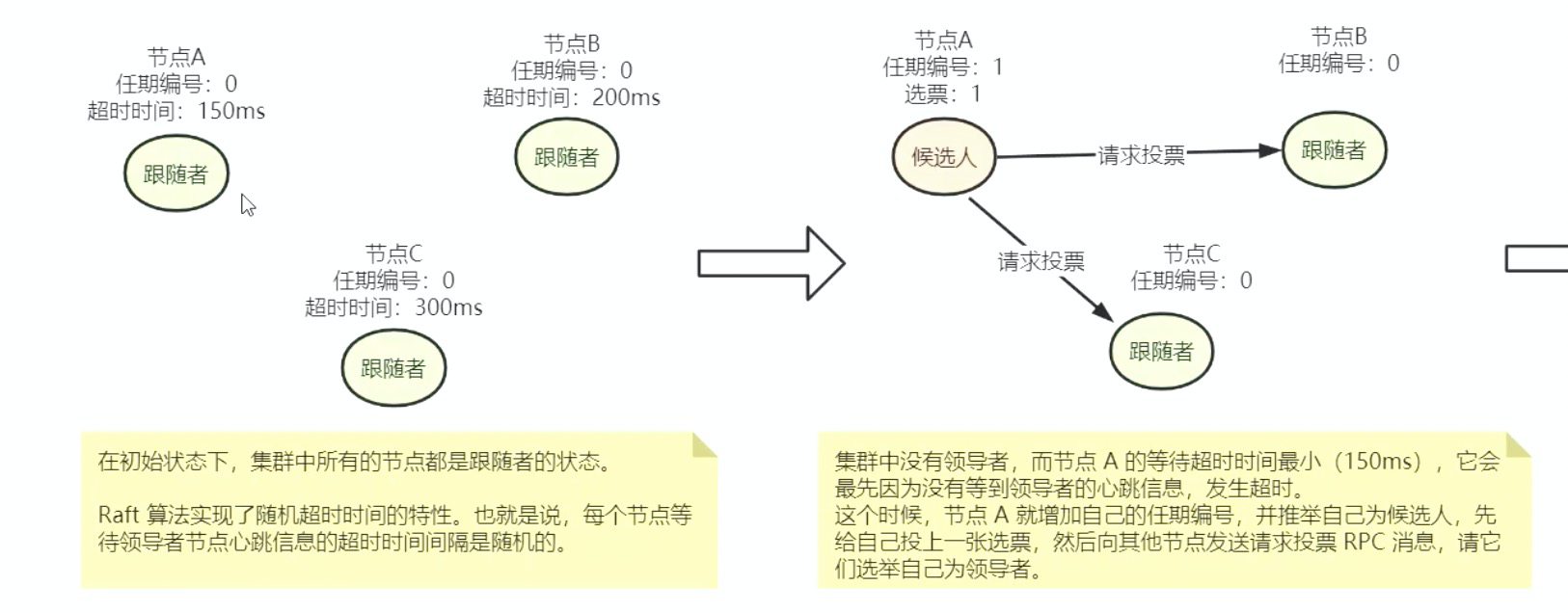
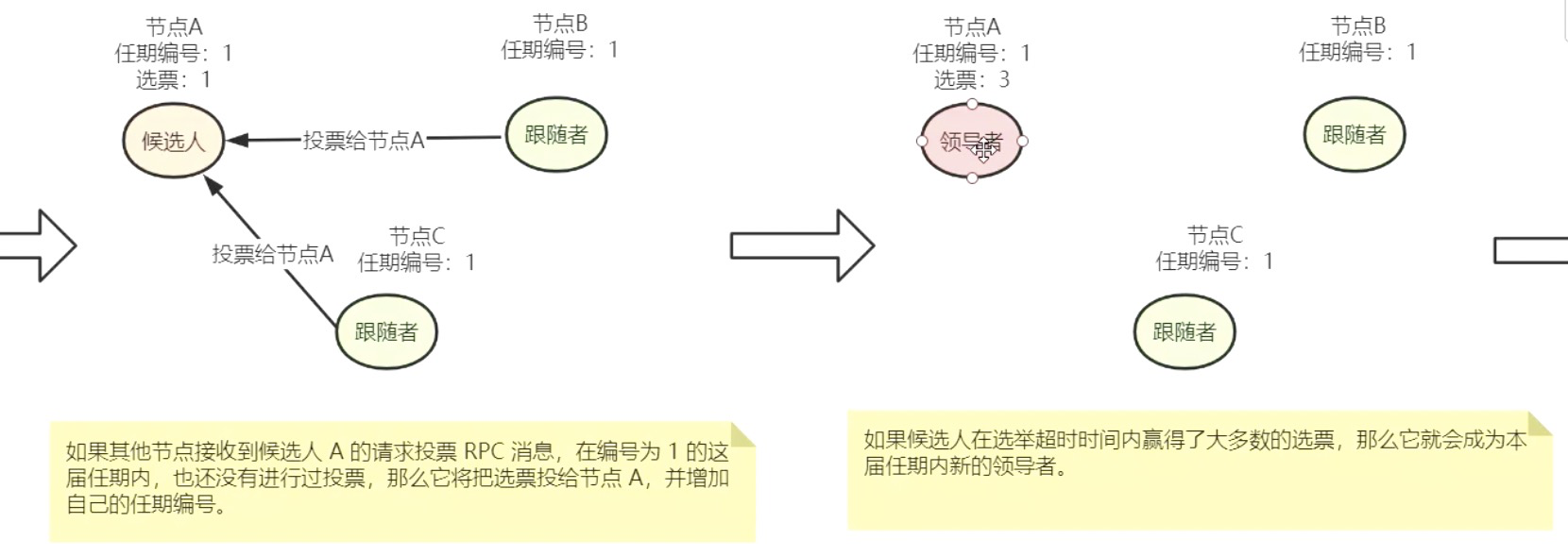
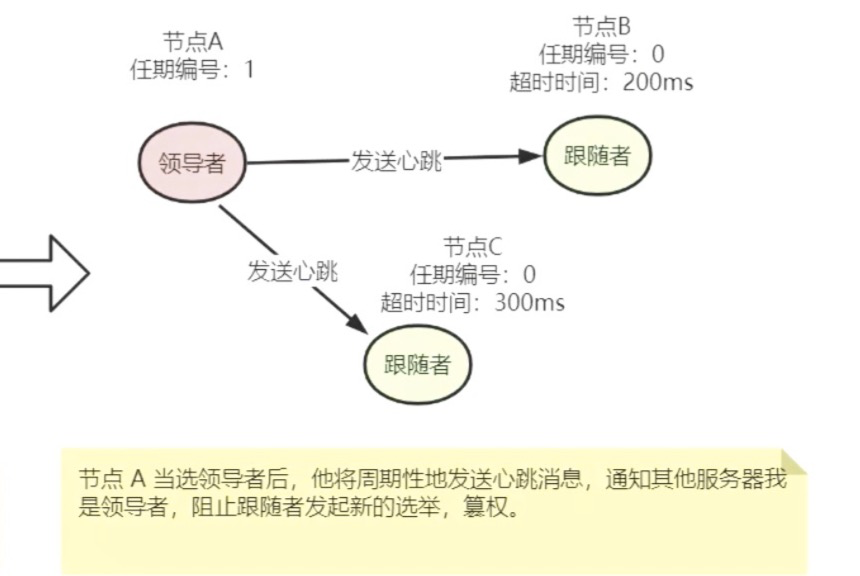
存在问题:如果集群中5个节点只有两个节点alive的状态下,且这2个节点都不是领导者,这时候就无法选择出Leader的。
概念解释
超时时间:
保证不同节点的超时时间不同
节点之间的通讯:
在Raft算法中,服务器节点间的通讯采用RPC, 在领导者选举过程中,需要用到两类的RPC:
- 请求投票(RequestVote)RPC,是由候选人在选举期间发起,通知各节点进行投票
- 日志复制(AppendEntries)RPC,是由领导者发起,用来复制日志和提供心跳消息。
任期编号:
Raft算法中的领导者也是有任期的,每个任期有单调递增的数字(任期编号)标识,比如节点A的任期编号为1,任期编号是随着选举的变化而变化的。
- 跟随者在等待领导者心跳信息超时后,推举自己为候选人,会增加自己的任期号。比如节点A的任期编号为1,在推举自己为候选人时,会将任期编号增加1
- 如果一个服务节点,发现自己的任期编号比其他节点小,就会更新自己的编号到较大的编号值。比如接单B的任期编号为0,当收到节点A的请求投票的RPC消息后,消息会包含A节点的任期编号1, 那么节点B会将自己的认为编号更新为1
任期编号的大小,会影响领导者选举和请求的处理:
- 在Raft算法中约定,如果一个候选者或者领导者,发现自己的任期编号比其他节点小,那么他会立即恢复成跟随者的状态
- 如果一个节点收到一个包含较小任期编号的请求,那么他会直接拒绝这个请求。
投票:
在一次选举中,每个服务器节点最多会对一个任期编号投出一张选票,并且按照“先来先服务”的原则进行投票。















 434
434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









