






第 1 章:绪论
1、分别解释人工智能的三个主要学派的代表人物和主要思想,并给出每个学派的一个实际应用实例。
- 符号主义(Symbolists 或 逻辑主义):
- 代表人物:马文·闵斯基(Marvin Minsky)、约翰·麦卡锡(John McCarthy)。
- 主要思想:符号主义认为智能行为是通过对符号的操作来实现的,这些符号代表了世界的不同方面。符号主义强调使用逻辑和规则系统来模拟人类的思维过程。
- 实际应用实例:专家系统,如IBM的深蓝(Deep Blue)使用符号主义方法来模拟国际象棋大师的决策过程。
- 连接主义(Connectionism):
- 代表人物:弗兰克·罗森布拉特(Frank Rosenblatt)、杰弗里·辛顿(Geoffrey Hinton)。
- 主要思想:连接主义基于人工神经网络,认为智能行为是通过大量简单的计算单元(神经元)和它们之间的连接模式来实现的。这些网络可以通过学习来调整神经元之间的连接权重。
- 实际应用实例:深度学习在图像识别领域的应用,如自动驾驶汽车中使用的计算机视觉系统。
- 行为主义(Behaviorism):
- 代表人物:罗德尼·布鲁克斯(Rodney Brooks)。
- 主要思想:行为主义强调通过感知和行动的直接映射来实现智能行为,而不是通过内部的符号操作。它倾向于使用简单的控制规则和传感器输入来驱动机器人的行为。
- 实际应用实例:家用机器人吸尘器,如Roomba,使用传感器和简单的规则来导航和清洁房间。
第 2 章:状态空间法及其搜索技术
1、什么是盲目式搜索,它在哪些情况下适用?它有哪些缺陷?
盲目式搜索(Blind Search),也称为无信息搜索,是一种在没有关于问题领域任何先验知识的情况下进行的问题解决策略。
特点:
- 无启发式:盲目式搜索不使用任何启发式信息,即它不利用任何关于目标的额外信息来指导搜索过程。
- 系统性:它通过系统性地探索所有可能的候选解来寻找解决方案。
- 完备性:如果搜索空间是有限且可达的,盲目式搜索能够保证找到至少一个解(如果有解的话)。
- 方法:常见的盲目式搜索算法包括深度优先搜索(Depth-First Search, DFS)、广度优先搜索(Breadth-First Search, BFS)和迭代深化深度优先搜索(Iterative Deepening Depth-First Search, IDDFS)。
适用情况:
- 未知领域:在对问题领域一无所知或领域信息不明确时,盲目式搜索可以作为一种通用的解决方案。
- 简单问题:对于结构简单、搜索空间不大的问题,盲目式搜索可以高效地找到解。
- 教育目的:在教学中,盲目式搜索常用来介绍搜索算法的基本概念。
缺陷:
- 效率低下:盲目式搜索可能需要探索大量的节点,特别是当搜索空间很大时,这可能导致效率低下。
- 资源消耗:在大规模搜索空间中,盲目式搜索可能消耗大量的时间和内存资源。
- 不可扩展性:随着问题规模的增长,盲目式搜索的效率急剧下降,对于复杂问题可能不实用。
- 缺乏优化:由于不使用启发式信息,盲目式搜索可能无法快速地收敛到最优解或可行解。
实际应用:
尽管盲目式搜索存在上述缺陷,但在某些情况下它仍然有其应用场景,如:
- 游戏:在一些简单的游戏中,盲目式搜索可以用来找到获胜策略。
- 简单规划问题:在规划问题中,如果问题域不大,盲目式搜索可以用来探索所有可能的行动序列。
2、解释 A*搜索算法的工作原理,并讨论其效率。
A*搜索算法是一种有效的启发式搜索算法,用于在图中找到从起始节点到目标节点的最短路径。其结合了Dijkstra算法(保证找到最短路径)和Best-First Search(BFS)的特点,通过启发式评估来优化搜索过程。
工作原理:
- 启发式函数(Heuristic Function, h):
- A*算法使用一个启发式函数来估计从当前节点到目标节点的距离。这个函数应该是问题特定的,并且满足一致性(或称为单调性)条件,即它不会高估实际成本。
- 代价函数(Cost Function, g):
- 表示从起始节点到当前节点的实际代价。
- 总代价(F):
- 节点的总代价F是实际代价g和启发式估计h的和,即𝐹(𝑛)=𝑔(𝑛)+ℎ(𝑛)F(n)=g(n)+h(n)。F(n)用于评估通过节点n到达目标的代价。
- 优先队列(Open Set):
- A*使用一个优先队列来存储待扩展的节点,节点根据其总代价F进行排序。
- 已访问集合(Closed Set):
- 已访问集合用于记录已经评估过的节点,避免重复处理。
- 搜索过程:
- 从起始节点开始,将其加入优先队列。
- 循环以下步骤直到找到目标节点或队列为空: a. 从优先队列中取出具有最低F值的节点。 b. 如果这个节点是目标节点,则搜索成功,可以重建路径。 c. 否则,将此节点标记为已访问,并将它的邻居节点加入优先队列,如果没有被访问过的话。
- 路径重建:
- 一旦找到目标节点,可以通过回溯每个节点的父节点来重建路径。
效率讨论:
- 优点:
- 优化搜索:启发式函数指导搜索朝着目标方向进行,减少不必要的搜索。
- 完备性:如果启发式函数是一致的,A*算法保证找到最短路径。
- 适用性:适用于各种类型的搜索问题,包括路径规划、游戏AI等。
- 缺点:
- 启发式依赖:算法的效率和准确性很大程度上依赖于启发式函数的选择。
- 内存消耗:需要存储所有生成的节点和它们的F值,对于大规模问题可能消耗大量内存。
- 计算开销:启发式函数的计算可能增加每个节点处理的开销。
- 实际应用:
- A*算法广泛应用于游戏开发、机器人路径规划、交通导航系统等领域。
第 3 章:问题归约表示及其搜索技术
1、解释与或图和与或树在问题求解中的作用。
与或图和与或树是问题求解领域中用于表示问题结构和搜索过程的两种工具,特别是在使用问题归约和启发式搜索时。以下是它们在问题求解中的作用:
与或图:
- 问题表示:与或图是一种用于表示问题状态和状态间关系的图形模型。在这种图中,每个节点代表一个问题的部分状态或子问题。
- 问题分解:与或图中的“与”节点表示需要同时满足多个子条件的状态,而“或”节点表示有多种选择的状态。
- 搜索空间:与或图可以表示问题的整个搜索空间,包括所有可能的状态和状态转换。
- 解决问题:通过与或图,可以识别出问题的关键部分,并尝试分解问题为更小的、更易管理的子问题。
与或树:
- 搜索过程表示:与或树是从初始状态开始,通过搜索算法逐步扩展得到的树状结构。它记录了搜索过程中已经探索的状态。
- 层次化问题分解:与或树的每个“与”节点代表一个待解决的子问题,而“或”节点代表在该子问题中需要考虑的不同选择。
- 避免重复工作:与或树确保每个状态或子问题只被考虑一次,避免了重复计算和探索。
- 启发式搜索:在启发式搜索算法(如A*)中,与或树可以用来应用剪枝技术,通过评估节点的启发式值来决定哪些分支值得扩展。
作用:
- 问题简化:与或图和与或树帮助将复杂问题分解为更简单的子问题,便于求解。
- 搜索空间缩减:通过剪枝技术,可以减少搜索过程中需要探索的状态数量。
- 解决方案发现:它们提供了一种系统性的方法来发现问题的一个或多个解决方案。
- 启发式评估:在启发式搜索中,与或树可以用来评估不同路径的代价,以指导搜索过程。
实际应用:
- 在人工智能领域,与或图和与或树被用于路径规划、游戏AI、自动规划系统等。
- 例如,在游戏AI中,与或树可以用来模拟不同的游戏走法和对手的潜在反应。
第 4 章:谓词逻辑表示与推理技术
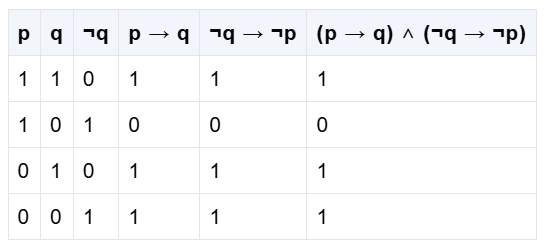
1、对命题逻辑表达式(p → q) ∧ (¬q → ¬p),给出其真值表。
第 5 章:模糊逻辑与模糊推理
1、讨论模糊逻辑在处理不确定性和模糊性问题中的优势。
模糊逻辑(Fuzzy Logic)是一种数学逻辑,它处理真实世界中的不确定性和模糊性问题,与传统的二值逻辑(Boolean Logic)不同,模糊逻辑使用连续的值范围(通常是0到1)来表示可能性或真值程度。以下是模糊逻辑在处理不确定性和模糊性问题中的优势:
- 处理模糊性:模糊逻辑允许表示模糊概念,如“温暖”、“高”或“年轻”,这些概念在传统逻辑中很难精确定义。
- 灵活性:它提供了一种灵活的推理方法,可以处理不精确或不完全信息,而不会像传统逻辑那样导致无效的结论。
- 更好的符合人类直觉:模糊逻辑更接近人类的决策过程,人类在处理模糊或不清晰的信息时,往往能够做出合理的判断。
- 处理不确定性:在现实世界中,很多情况下我们无法获得精确的数据,模糊逻辑可以处理这种不确定性,并提供合理的解决方案。
- 增强的表达能力:模糊逻辑通过使用模糊集合和模糊规则,可以更精确地表达复杂的系统和过程。
- 控制应用:在自动控制领域,模糊逻辑控制器可以处理复杂的非线性系统,实现更精细的控制。
- 决策支持:在需要考虑多个因素和条件的决策问题中,模糊逻辑可以提供更加全面和平衡的决策支持。
- 数据预处理:模糊逻辑可以用于数据预处理,帮助识别和处理异常值或噪声数据。
- 模式识别:在模式识别领域,模糊逻辑可以处理数据中的模糊边界,提高分类和识别的准确性。
- 优化问题:模糊逻辑可以用于优化问题,通过考虑多个目标和约束条件的模糊优先级来找到解决方案。
- 人工智能:在人工智能领域,模糊逻辑被用于创建更加智能和适应性强的系统,如模糊神经网络。
- 鲁棒性:模糊逻辑系统通常具有良好的鲁棒性,即使在输入数据存在变化或扰动时也能保持稳定。
第 6 章:遗传算法
1、解释遗传算法中的选择、交叉和变异操作。
遗传算法是一种模拟自然选择和遗传学原理的搜索算法,用于解决优化和搜索问题。它们通过模拟自然进化过程来迭代地改进候选解。以下是遗传算法中三个核心操作的解释:
- 选择(Selection):
- 选择操作的目的是将更好的候选解(个体)从当前种群中挑选出来,以便它们可以参与到下一代的创建中。这个过程通常基于个体的适应度(Fitness),适应度是根据个体与问题目标的接近程度来评估的。
- 常见的选择方法包括轮盘赌选择(Roulette Wheel Selection)、锦标赛选择(Tournament Selection)和精英选择(Elitism)等。
- 交叉(Crossover, 也称杂交):
- 交叉操作用于组合两个父代个体的遗传信息,产生新的后代个体。这是遗传算法中探索新解空间的主要机制。
- 在执行交叉时,会随机选择父代个体的某一部分基因序列,并与另一个个体的相应部分交换,从而形成两个新的个体。
- 交叉操作可以是单点交叉、双点交叉或均匀交叉等,具体方法取决于问题的性质和基因序列的结构。
- 变异(Mutation):
- 变异操作是在后代个体的基因序列中引入小的随机变化,以维持种群的多样性并防止算法过早收敛到局部最优解。
- 变异通过随机改变个体的某些基因来实现,这种变化通常以很低的概率发生,以保持种群的整体稳定性。
- 变异操作可以是点变异、交换变异或插入变异等,具体取决于基因序列的特点。
遗传算法的基本步骤:
- 初始化:随机生成初始种群。
- 评估:计算种群中每个个体的适应度。
- 选择:根据适应度从当前种群中选择个体。
- 交叉:通过交叉操作在选中的个体间交换遗传信息,产生新的后代。
- 变异:对新生成的后代以一定概率应用变异操作。
- 新一代:形成新的种群,并重复步骤2到5,直到满足停止条件。
优势和应用:
- 遗传算法的优势在于它们不需要问题的具体信息,只需要适应度函数来评估解的质量。
- 它们适用于搜索空间大、非线性、多峰值或复杂的问题。
- 应用领域包括工程优化、调度问题、神经网络训练、游戏AI等。
遗传算法是一种启发式搜索方法,通过模拟自然进化过程来找到问题的近似最优解。
第 7 章:群智能算法
1、比较粒子群算法和蚁群算法的相似之处和不同之处。
粒子群优化算法(Particle Swarm Optimization, PSO)和蚁群算法(Ant Colony Optimization, ACO)都是基于自然现象的启发式搜索算法,用于解决优化问题。它们各自模拟了鸟群或鱼群的行为以及蚂蚁寻找食物的路径选择过程。以下是它们的相似之处和不同之处:
相似之处:
- 启发式搜索:两者都是启发式搜索算法,用于解决复杂的优化问题,尤其是那些传统算法难以解决的问题。
- 种群搜索:PSO和ACO都使用种群的概念,其中每个个体代表问题的潜在解。
- 迭代过程:两种算法都通过迭代过程逐步改进解,每次迭代都更新种群中的个体。
- 信息利用:PSO和ACO在搜索过程中都利用个体的信息来指导搜索方向。
- 随机性:两种算法在搜索过程中都引入了随机性,以探索解空间。
- 适应度评价:个体的更新都依赖于适应度评价,以确定解的质量。
不同之处:
- 模拟现象:PSO模拟鸟群或鱼群的社会行为,而ACO模拟蚂蚁寻找食物的路径选择过程。
- 个体更新机制:在PSO中,个体(粒子)根据个体最佳位置和全局最佳位置来更新;而在ACO中,个体(蚂蚁)根据信息素浓度来选择路径。
- 信息素和启发式信息:ACO特有的信息素更新机制,蚂蚁在行走过程中释放信息素,信息素浓度随着时间衰减并受到蚂蚁行走的增强。PSO没有信息素的概念。
- 搜索策略:PSO侧重于利用个体历史信息和全局信息来指导搜索,而ACO侧重于通过信息素的正反馈机制来增强优秀解的搜索。
- 应用领域:PSO由于其简单性和高效性,常用于连续空间的优化问题;ACO则常用于解决组合优化问题,如旅行商问题(TSP)和车辆路径问题(VRP)。
- 算法参数:PSO的主要参数包括粒子速度、个体和全局最佳位置;ACO的主要参数包括信息素浓度、启发式信息和信息素的衰减率。
- 收敛性:PSO可能在某些情况下容易陷入局部最优,而ACO通过信息素的正反馈机制有助于全局搜索。
- 多样性保持:ACO通过信息素的多样性和蚂蚁的随机选择来保持种群多样性;PSO则可能需要额外的策略来避免早熟收敛。
第 8 章:机器学习
1、针对“垃圾邮件过滤”这个机器学习算法的应用实例,查阅资料,解释其工作原理。
垃圾邮件过滤是机器学习算法在实际应用中的一个典型例子,其工作原理主要包括以下几个步骤:
- 数据收集和准备:首先需要收集大量的电子邮件数据,这些数据已经被标记为垃圾邮件或非垃圾邮件。数据可以来自公开的数据集或实际邮件流。
- 预处理:对收集到的邮件数据进行预处理,包括去除HTML标签、提取文本内容、分词等,以便于处理文本数据。
- 特征提取:从每封邮件中提取有代表性的特征,如词频(Term Frequency)、逆文档频率(Inverse Document Frequency)、字符n-grams等。这些特征将文本数据转换为数值表示形式,以便于机器学习模型处理。
- 数据向量化:使用词袋模型(Bag-of-Words Model)或TF-IDF等方法将邮件数据转换为数值矩阵,为输入到机器学习模型做准备。
- 模型选择和训练:选择合适的机器学习算法,如朴素贝叶斯分类器、支持向量机(SVM)、随机森林等。将标记好的训练数据输入模型进行训练,使模型学习垃圾邮件和非垃圾邮件的特征和模式。
- 模型评估:使用测试数据集评估训练好的模型的性能,通常使用准确率、召回率和F1分数等指标。
- 邮件分类:使用训练好的模型对新的邮件进行分类预测。将待分类的邮件转换为特征向量,并通过模型进行预测,根据模型输出的概率或阈值判断,将邮件标记为垃圾邮件或非垃圾邮件。
- 持续优化:根据模型在实际应用中的表现,不断收集反馈,调整模型参数,优化特征提取方法,以提高过滤的准确性和效率。
垃圾邮件过滤系统通常需要平衡过滤的敏感度和特异性,避免误判正常邮件为垃圾邮件(误杀)或漏判垃圾邮件(漏报)。随着垃圾邮件发送者不断变化策略,过滤系统也需要不断更新以应对新的挑战。在一些实现中,也可能结合深度学习模型来提高过滤的准确性和适应性。
第 9 章:人工神经网络及深度学习
1、画出人工神经网络的基本组成单元——神经元的结构图,并解释其工作原理。
工作原理:
- 输入端:神经元接收来自其他神经元或环境的多个输入信号。
- 加权:每个输入信号都有一个权重(Weight),权重决定了输入信号对最终输出的影响程度。
- 加权求和:神经元将所有加权输入信号求和,可能还会加上一个偏置项(Bias),偏置项也是一个可调节的参数。
- 激活函数:
- 求和的结果被送入一个激活函数(Activation Function),如Sigmoid、Tanh或ReLU等。
- 激活函数的作用是为神经元的输出引入非线性,使得神经网络能够学习和执行更复杂的任务。
- 输出端:激活函数的输出就是神经元的最终输出,这个输出可以作为其他神经元的输入,或者作为神经网络的最终结果。
数学表达:
假设一个神经元有 𝑛 个输入 𝑥1,𝑥2,...,𝑥𝑛 和相应的权重 𝑤1,𝑤2,...,𝑤𝑛,偏置为 𝑏,则神经元的输出 𝑦 可以通过以下公式计算:
𝑧=𝑤1𝑥1+𝑤2𝑥2+...+𝑤𝑛𝑥𝑛+𝑏
𝑦=𝑓(𝑧)
其中 𝑓 是激活函数。
学习过程:
在训练神经网络时,通过前向传播计算输出,然后与期望输出比较计算误差。误差通过反向传播算法传递回网络,调整权重和偏置以减少误差。这个过程通常涉及梯度下降或其变体。
神经元的这种结构和工作原理使得人工神经网络能够模拟人脑处理信息的方式,处理复杂的数据模式和执行各种机器学习任务。

















 9296
9296











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









