








1. Classification
2. Hypothesis Representation
- Logistic Regression Model
- Interpretation of Hypothesis output
estimated probability thaton input
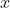
3. Decision Boundary
4. Cost function
5. Simplified cost function and gradient descent
logistic regression cost function
To fit parameters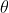
To make a new prediction given new
Gradient descent
algorithm looks identical to linear regression, why??
Q:Suppose you are running gradient descent to fit a logistic regression model with parameter θ∈Rn+1 . Which of the following is a reasonable way to make sure the learning rate α is set properly and that gradient descent is running correctly?
A:Plotas a function of the number of iterations and make sure
6. Advanced optimization
optimization algorithms:
- Gradient descent
- Conjugate gradient
- BFGS
- L-BFGS
the last three algorithms have the following advantages:
- no need to manually pick
- often faster than gradient descent
disadvantages:
- more complex
7. Multi-class classification: one-vs-all
- train a logistic regression classifier for each class to predict the probability
- on a new input
that maximizes

8. The problem of overfitting
- if we have too many features, the learned hypothesis may fit the training set very well, but fail to generate to new examples.
- the solutions for overfitting
- reduce number of features
- manually select which features to keep
- model selection algorithm
- regularization
- keep all the features, but reduce magnitude/value of parameters
- works well when we have a lot of features, each of which contributes a bit to predicting
- reduce number of features
9. Cost function
- Regularization
- small values for parameters
- "simpler" hypothesis
- less prone to overfitting
- small values for parameters
10. Regularized linear regression
- in the above function,
is regularization term
is regularization parameter, it does the following trade off
- it helps the first term to fit training set
- it helps to reduce the value of the parameters
- Gradient descent
- Normal equation
the matrix in the above equation is a(n+1)-by-(n+1) matrix
may be non-invertible/singular, but
may be invertible
11. Regularized logistic regression
- cost function
- gradient descent
From: http://blog.csdn.net/abcjennifer/article/details/7716281















 19万+
19万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









