







很多研究需要爬取社交平台上评论区的数据,而大众点评的评论区的数据具有评价对象清晰、评论内容更有价值等优点。下面,小编就手把手教你如何爬取大众点评评论区的数据。(完整代码附在最后了,需要的请自取)
1.了解大众点评的link的结构
Step 1:登录大众点评,任意搜索一个你感兴趣的评论区,比如“宽窄巷子”。
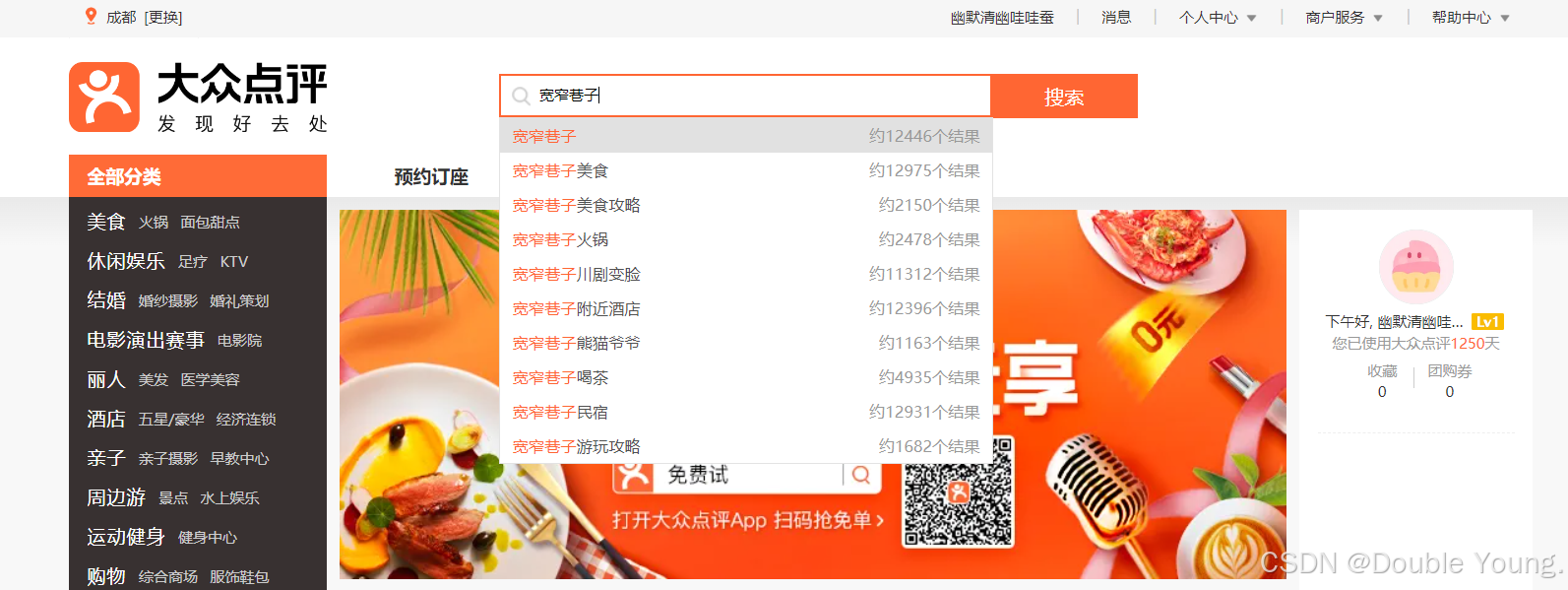
Step 2:点击进入宽窄巷子的评论区。
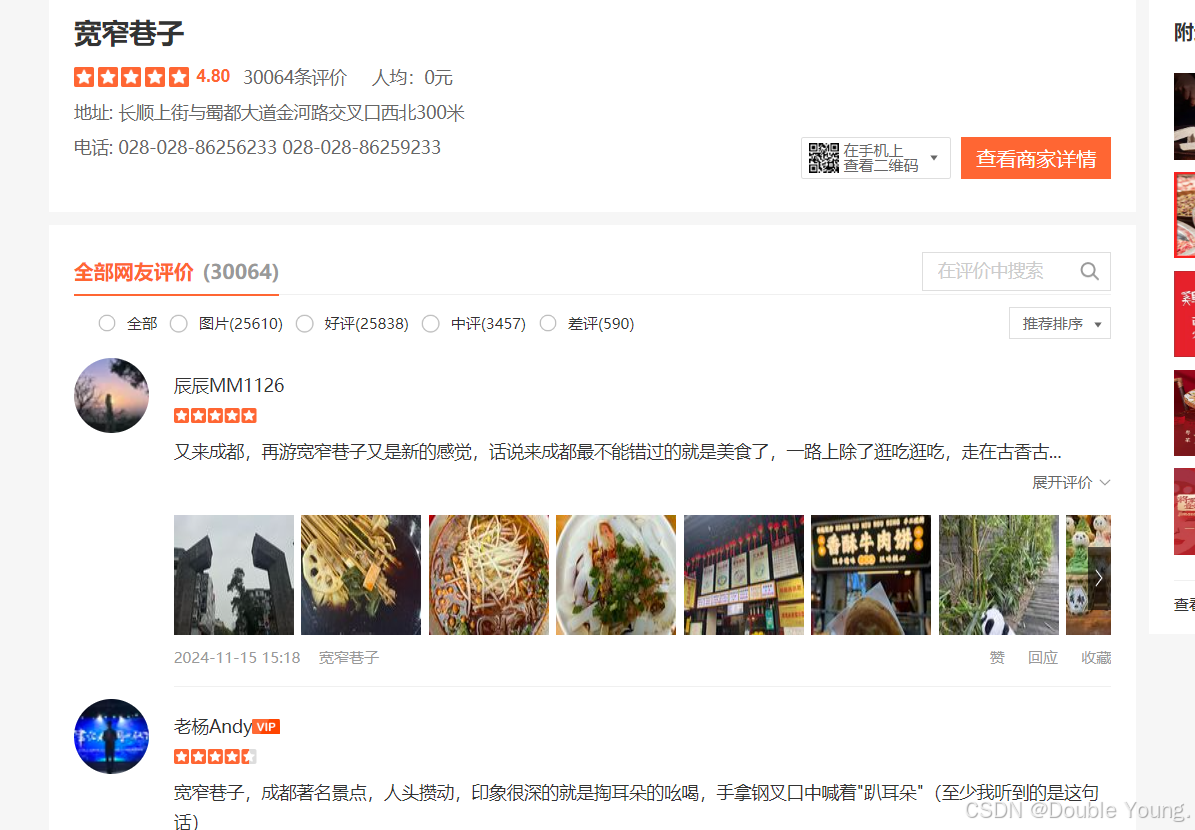
Step 3:点击F12查看抓包工具。如果没有在右边的抓包工具页面没有看到东西的话,点击F5刷新就可以了。然后在右边的搜索框中任意搜索一条评论中的关键词,输入完回车就行。
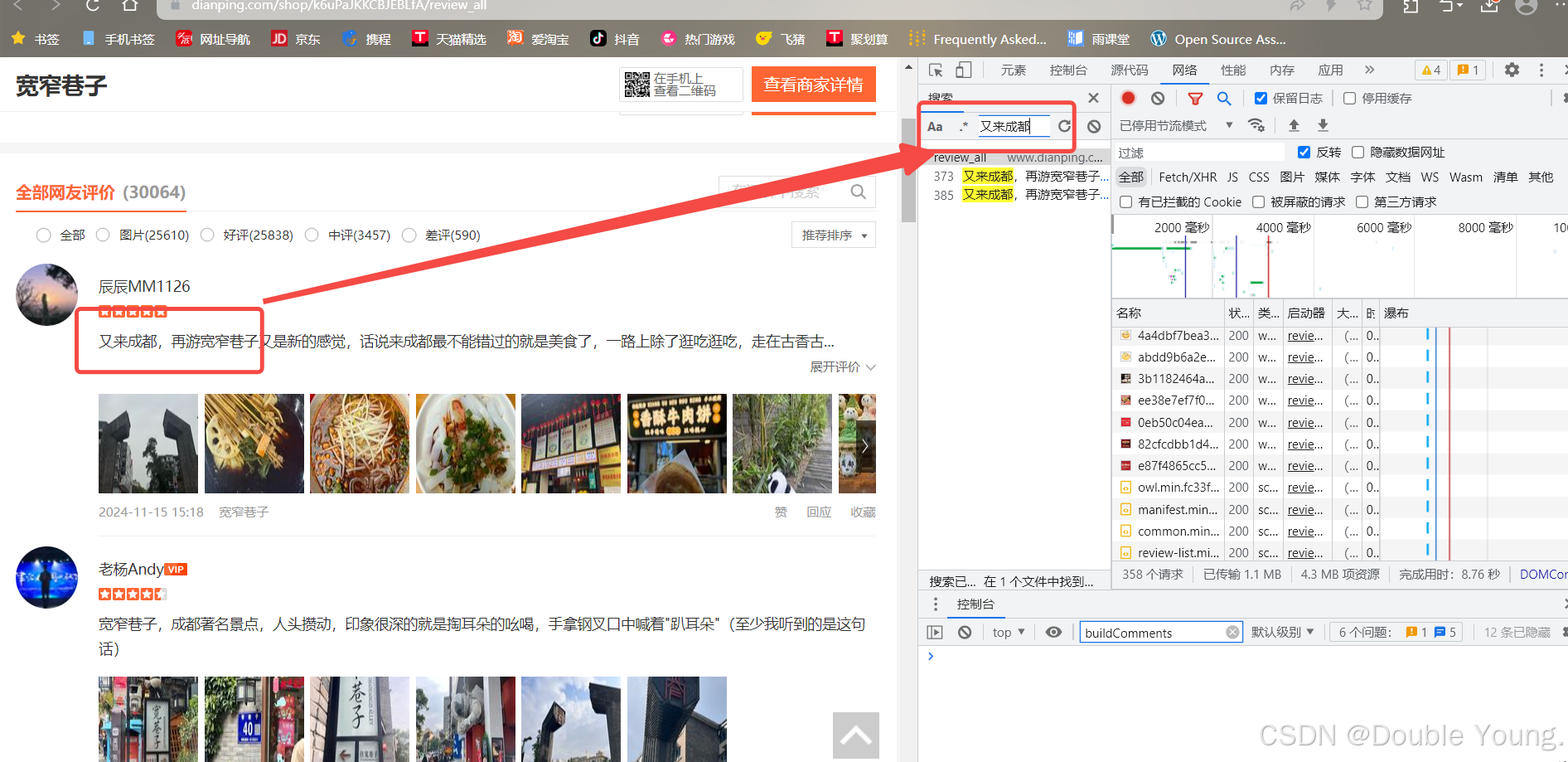
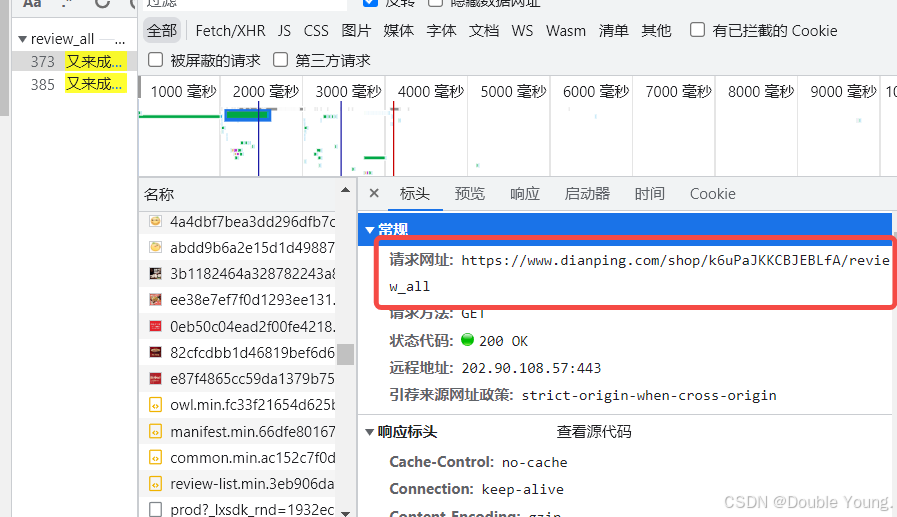
Step 4:点击右边搜索出来的内容,然后点击标头,可以看到其页面链接是:
https://www.dianping.com/shop/k6uPaJKKCBJEBLfA/review_all
Step 5:继续查看第二页评论和第三页评论的代码。下拉之后,点击评论的第2页、第3页,然后重复Step3-Step4就可以得到链接为:
第2页评论的链接:https://www.dianping.com/shop/k6uPaJKKCBJEBLfA/review_all/p2
第3页评论的链接:https://www.dianping.com/shop/k6uPaJKKCBJEBLfA/review_all/p3
再来看一下第1页评论的链接:
https://www.dianping.com/shop/k6uPaJKKCBJEBLfA/review_all
观察上面的几页评论,不难发现,这几个评论的链接只有最后几个不一样,其实对于第一页的评论,你使用这个link:https://www.dianping.com/shop/k6uPaJKKCBJEBLfA/review_all/p1
你会发现也可以到达评论的页面。所以,你要是想爬取大众点评的关于“宽窄巷子”的评论,你只需要通过修改链接p+number就可以了。对于这件事,只需要创建一个循环for p in range(0, max_num),然后拼接前面的一部分link就可以直接实现了。类似于以下的代码(实际还无法获取页面,因为需要你的cookie才行。不要着急,后面会介绍如何获取cookie的)
import requests
part_url = https://www.dianping.com/shop/k6uPaJKKCBJEBLfA/review_all/p
for i in range(0, 50):
url = requests.get(f"{part_url}{i}")
print(url)Step 6:进一步观察link的相同点。我们继续查看“太古里”的评论链接。
第1页评论的链接:https://www.dianping.com/shop/l93VqJ8r2j4HARZ9/review_all
第2页评论的链接:https://www.dianping.com/shop/l93VqJ8r2j4HARZ9/review_all/p2
第3页评论的链接:https://www.dianping.com/shop/l93VqJ8r2j4HARZ9/review_all/p3
与上述的“宽窄巷子”的链接对比,你会发现不同之处只有中间的:
宽窄巷子:k6uPaJKKCBJEBLfA
太古里:l93VqJ8r2j4HARZ9
我们把这个称为ID,每个对象的ID是固定的,并且ID和评价对象是一一对应的。
所以我们可以总结出页面的link为:
https://www/dianping.com/shop/{ID}/review_all/p{page_num}
Step 7:思考代码编写思路。
现在我们知道了评论页面的链接的规律,我们就可以思考如何循环爬取页面了。由于link中只有两个变化的量:ID和page_num。对于这两个可变的量,我们直接把这个两个变量作为程序的输入就可以了!
2.了解大众点评的页面结构
再次回到上一个Step 3的页面中,点击“响应”。
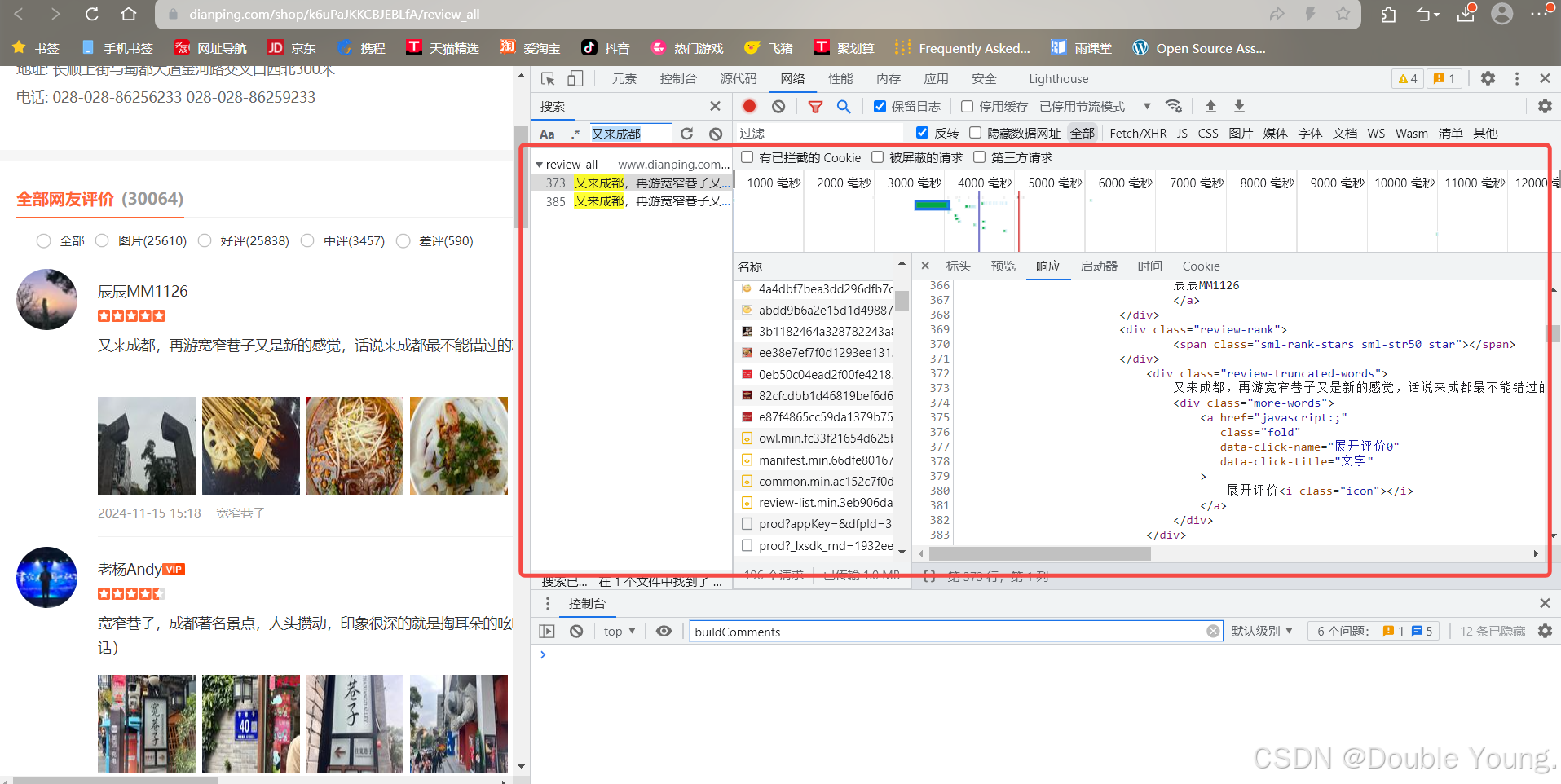
在大众点评中,评论分类两类,一类是内容较多被折叠的评论,一类内容较少不被折叠的评论。
对于第一类被折叠评论:在<div class="review-truncated-words"></div>中的是被折叠的,就是带省略号的,而在<div class="review-words Hide"></div>中的是不带省略号。显然我们需要的是后者。所以,我们需要使用下面的正则表达式提取评论的内容:
re_1_comment = re.compile(r'<div class="review-words Hide">(?P<comment>.*?)<div class="less-words">', re.S)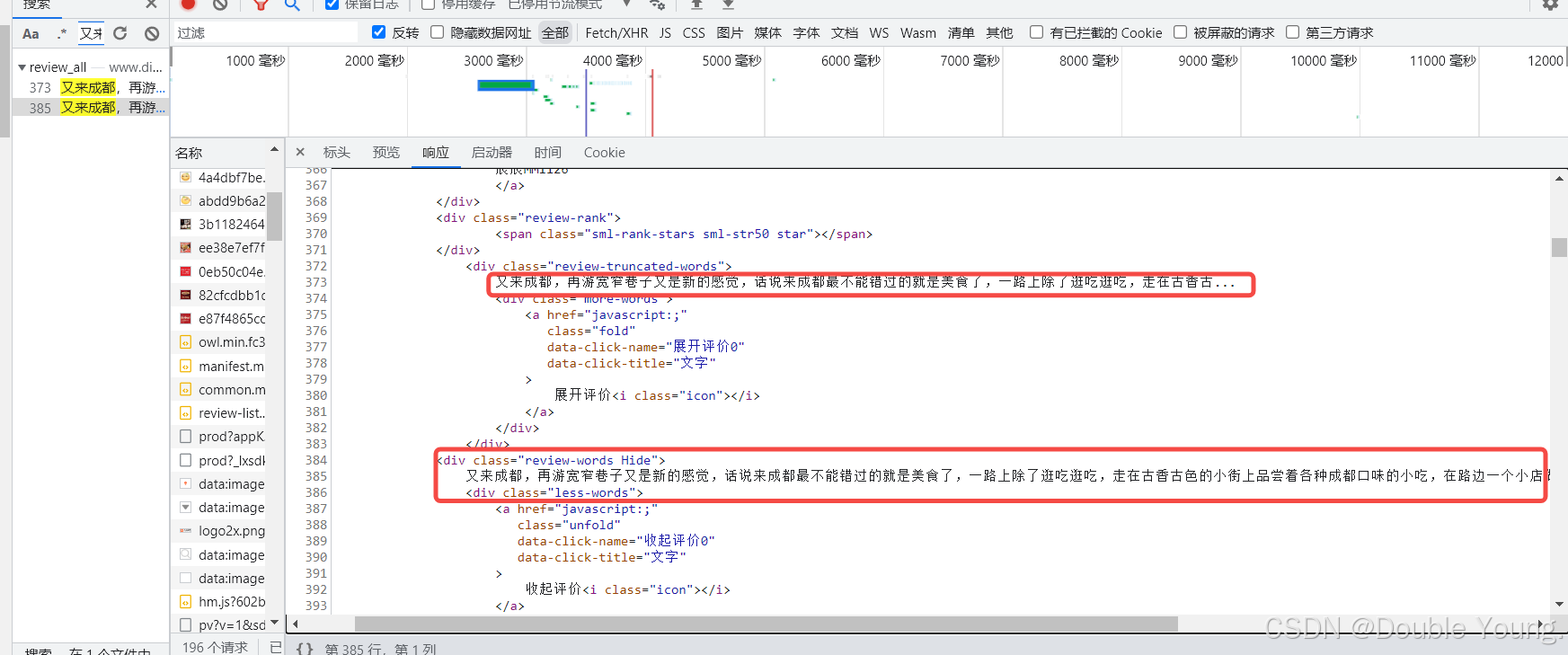
对于第二类不被折叠的评论:这类评论的内容在<div class="review-words"></div>中,因此我们需要换一个正则表达式才能提取评论的内容。
re_2_comment = re.compile(r'<div class="review-words">(?P<comment>.*?)</div>', re.S)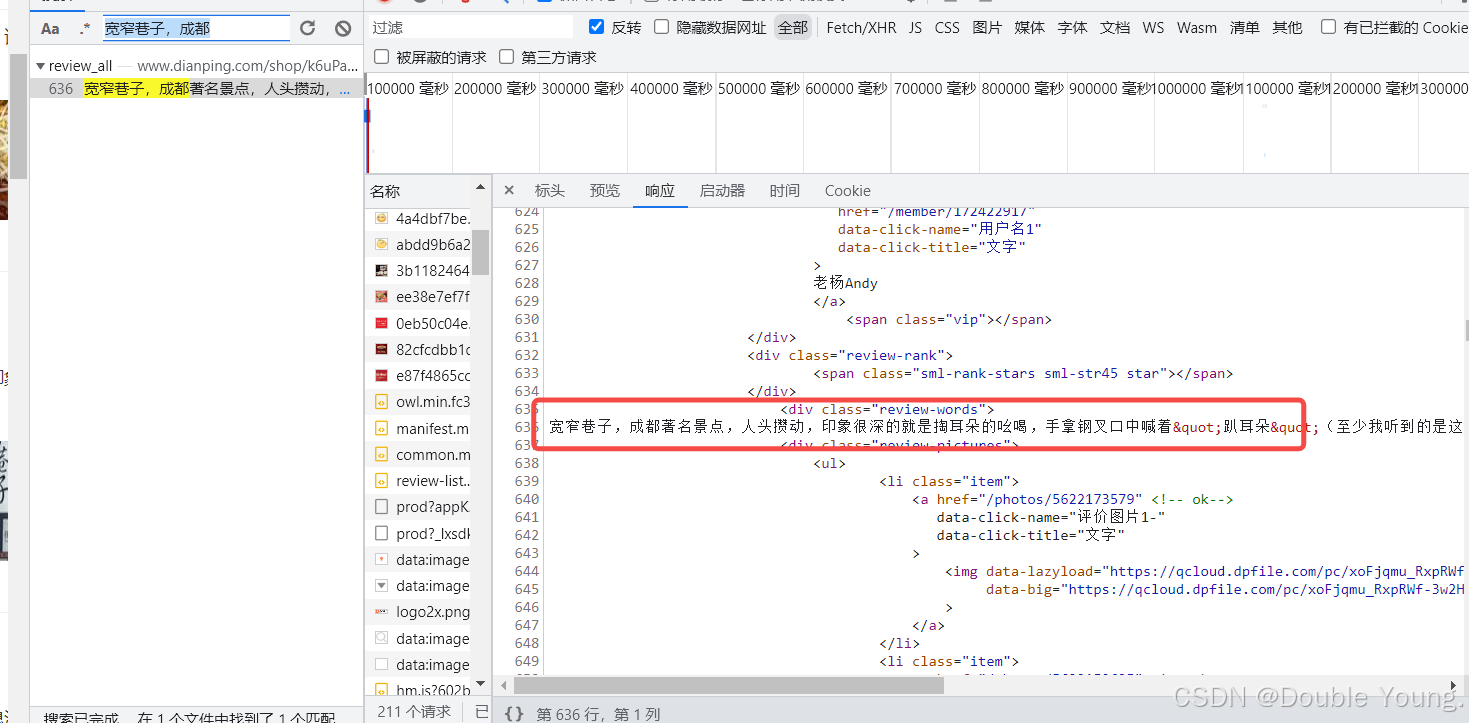
所以,通过上述正则表达式,就可以提取html页面中需要的评论的内容了。
3.完整代码
以下是完整代码,只需要6个输入参数就行:
(1)user_agent:具体获取方法可以查看文章简单!直接copy代码就可运行!爬虫获取知乎评论!!!_python爬取知乎评论-CSDN博客
(2)cookie:具体获取方法可以查看文章
简单!直接copy代码就可运行!爬虫获取知乎评论!!!_python爬取知乎评论-CSDN博客
(3)评价对象:“宽窄巷子”,“太古里”等
(4)code:上述的页面ID
(5)min_num:评论区的最小页码,0,1,2,3等
(6)max_num:评论区的最大页码,10,11,12等
import requests
import csv
from bs4 import BeautifulSoup
import re
from tqdm import tqdm
import time
from fake_useragent import UserAgent
# 随机生成 useragent
def get_random_useragent():
ua = UserAgent()
return ua.random
# 用于更新 headers
def update_headers(user_agent, cookie):
headers = {
"User-Agent": get_random_useragent(),
"Cookie": cookie
}
return headers
# 获取评论
def get_comment(contents, re_, comment_list):
comments = re_.finditer(contents)
for comment_ in comments:
raw_data = comment_.group("comment").strip()
processed_data = re.sub(r"
| |<img.*?/>", "", raw_data)
comment_list.append(processed_data)
return comment_list
# 转换时间
def get_time(contents, re_, time_list):
times = re_.finditer(contents)
for time_ in times:
raw_data = time_.group("time").strip()
processed_data = re.sub(".*?更新于|' '", "", raw_data, flags=re.S)
time_list.append(processed_data)
return time_list
def load_comments(contents, re_1, re_2, re_3, re_4, csv_writer, key_word):
# Step 1:获取评论内容的部分
comment_list = []
time_list = []
# Step 2:获取 hide 的评论
comment_list = get_comment(contents, re_1, comment_list)
time_list = get_time(contents, re_2, time_list)
# Step 3:获取未 hide 的评论
comment_list = get_comment(contents, re_3, comment_list)
time_list = get_time(contents, re_4, time_list)
print(time_list)
for comment_, time_ in zip(comment_list, time_list):
csv_writer.writerow([key_word, time_, comment_])
time.sleep(5)
return True
if __name__ == '__main__':
# 定义参数
user_agent = input("请输入user_agent:")
cookie = input("请输入cookie:")
key_word = input("请输入评价的对象:")
code = input("请输入code:")
min_num = int(input("请输入最小页码:"))
max_num = int(input("请输入最大页码:"))
headers = update_headers(user_agent, cookie)
# 打开文件
# TODO:修改成自己的文件地址
f = open("../final_comments_data/comments_dzdp.csv", mode="a", encoding="utf-8")
csv_writer = csv.writer(f)
# 加载正则表达式,用于提取需要的信息
re_1_comment = re.compile(r'<div class="review-words Hide">(?P<comment>.*?)<div class="less-words">', re.S)
re_1_time = re.compile(r'<div class="review-words Hide">.*?<span class="time">(?P<time>.*?)</span>', re.S)
re_2_comment = re.compile(r'<div class="review-words">(?P<comment>.*?)</div>', re.S)
re_2_time = re.compile(r'<div class="review-words">.*?<span class="time">(?P<time>.*?)</span>', re.S)
for i in tqdm(range(min_num, max_num)):
resp = requests.get(f"https://www.dianping.com/shop/{code}/review_all/p{i}", headers=headers)
resp.encoding = "utf-8"
contents = resp.text
# store what I fetched
load_comments(contents,
re_1=re_1_comment,
re_2=re_1_time,
re_3=re_2_comment,
re_4=re_2_time,
csv_writer=csv_writer,
key_word=key_word)
f.close()
















 774
774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









