







本文作者系360奇舞团前端开发工程师
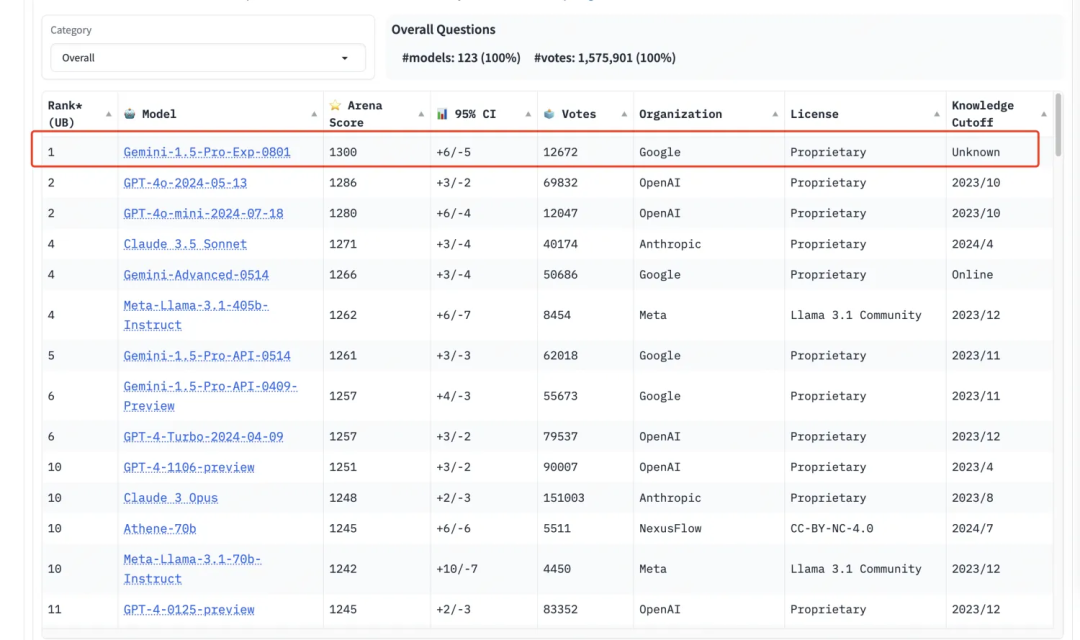
2023-2024年是AI领域蓬勃发展的时期,各家科技巨头纷纷推出自家的大模型,竞争激烈。谷歌在AI领域持续深耕,并于2024年8月1日发布了Gemini 1.5 Pro(0801),其卓越的性能超越了ChatGPT-4,使得谷歌夺得lmsys竞技场第一,中文任务也位列榜首。本文将深入探讨Google的AI大模型发展历程,并以实际案例展示Gemini的强大功能。
什么是Gemini?
Gemini 是 Google 推出的多模态 AI 模型,旨在超越 OpenAI 的 ChatGPT 4.0。它不仅拥有强大的文本理解和生成能力,还能处理图像、视频等多模态数据,并进行更深层次的推理和理解,为用户带来更智能、更人性化的交互体验。
Gemini核心特点:
多模态能力:Gemini能够处理文本、图像、音频、视频和代码等多种数据类型,使其在信息处理的广度和深度上超越了ChatGPT-4.0,能够更好地理解和响应用户的需求。
更强的推理能力:Gemini拥有强大的上下文理解能力,能够处理长文本和复杂代码,进行深入的推理和分析,从而提供更精准、更全面的答案。
高效性和适应性: Gemini设计高效,能够在各种平台上运行,从大型数据中心到移动设备,都能提供稳定的性能,满足不同场景下的应用需求。
增强AI助手:凭借其先进的功能,Gemini显著增强了AI助手的有效性和可靠性。它支持复杂任务的执行,为用户提供更智能和直观的互动。无论是协助编写代码、生成详细报告,还是创建多媒体内容,Gemini都提升了AI助手的标准。
Gemeni模型家族
为了迎战 ChatGPT,谷歌于 2023 年 3 月推出聊天机器人 Bard,但它的最初产品能力并不足够好、甚至在现场演示时回答出错, 导致股价暴跌。
为了在竞争激烈的AI领域保持领先地位,谷歌不断迭代更新其AI模型。从最初的LaMDA模型,到功能更强大的PaLM模型,再到如今的Gemini模型,谷歌的AI技术一直在不断进步。
模型发展历程:
2023年3月: 谷歌推出聊天机器人Bard,最初基于LaMDA模型。
2023年12月: Gemini 发布,Bard 宣布将运行在 Gemini Pro 上。
2024年2月: 推出 Gemini Pro、Gemini Advanced,Bard 改名为 Gemini,并推出 Gemini 的 Android 和 iOS 应用。
2024年5月: 推出 Gemini Pro 1.5、Gemini 1.5 Flash。
2024年8月1日: 推出 Gemini Pro 1.5(0801),性能超越 ChatGPT-4。
Gemini模型家族的主要成员及其特点:
| 模型 | 主要特点 | 应用场景 |
|---|---|---|
| Gemini Nano | 轻量级模型,适用于设备端,如内置在移动端、PC端、Mac端,做一些无需强大计算的场景,为用户提供更便捷、实时快速的AI体验。 | 设备端应用,如实时翻译、语音识别等。 |
| Gemini Pro | 强大的通用模型,适用于各种文本处理任务 | 问答、摘要、翻译、代码生成。 |
| Gemini Pro 1.5 | 在 Gemini Pro 的基础上进行改进,性能更强,推理能力更出色 | 更加复杂的文本处理任务,例如长文本理解、代码分析、专业领域的知识问答 |
| Gemini Flash | 在Gemini Ultra和Gemini Pro之间的一个平衡点,兼具能力和效率。能够处理各种各样的任务,从简单的问答到复杂的推理。 | 多种任务,如对话、摘要、翻译等。 |
| Gemini Advanced | 基于 Google 最强大的 AI 模型 Gemini Ultra 1.0,提供更高级的功能和更强大的性能 | 专业的AI应用,例如科学研究、艺术创作、复杂的数据分析 |
| Gemini Ultra | 最强大、最通用的模型,能够处理高度复杂的任务,在许多基准测试中,Gemini Ultra的表现都超越了其他大型语言模型。 | 通用型AI,适用于各种复杂任务。如科学研究、艺术创作等。它能够理解和生成各种形式的内容,包括文本、代码、图像等。 |
此部分相关链接
模型种类介绍:https://deepmind.google/technologies/gemini/
模型进化:https://gemini.google.com/updates
各模型收费信息: https://ai.google.dev/pricing?hl=zh-cn
内置Chrome AI
Gemini Nano模型 将内置到 Chrome 中,供大家免费使用,为用户提供更便捷的AI体验。
使用 chrome 本地模型的好处:
本地处理敏感数据:设备端 AI 可以改进您的隐私保护。例如,如果您处理敏感数据,则可以通过端到端加密为用户提供 AI 功能。
流畅的用户体验:无需网络请求,响应速度更快。
更好地利用 AI:降低服务器负载,用户的设备可以承担一些处理负载,以换取对功能的更多访问权限。例如,如果您提供高级 AI 功能,则可以使用设备端 AI 来预览这些功能,以便潜在客户可以看到您产品的优势,而无需支付额外费用。这种混合方法还可以帮助您管理推断费用,尤其是针对常用用户流的推断费用。
离线使用 AI :即使没有互联网连接,您的用户也可以使用 AI 功能。
使用 chrome 本地模型的缺点:
模型下载需求:目前模型1.2G,需要手动打开浏览器配置下载,占用一定存储空间。
硬件限制:设备性能差异使得不能保证所有设备都能高效运行复杂的AI模型。
前置条件
准备好梯子,使用 VPN 连接到支持 Gemini 的国家。
申请加入体验计划,在
Chrome for developer官网(developer.chrome.com/docs/ai/bui…)点击“加入我们的早期预览版计划”。
下载安装最新的 Chrome Canary版 或Chrome Dev版,并确认你的版本等于或高于 128.0.6545.0,请在这个页面找到适合自己电脑的版本https://www.chromium.org/getting-involved/dev-channel/
检查你的设备是否满足要求。
要确保你至少有 22 GB 的可用存储空间。
如果下载后可用存储空间低于 10 GB,模型将会被删除。请注意,有些操作系统可能会不同地报告实际的可用磁盘空间,例如,是否包括垃圾箱中占用的磁盘空间。在 macOS 上&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1452
1452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









