







第三章
第三章介绍了线性模型,包括基本形式、线性回归、对数几率回归、线性判别分析、多分类学习以及类别不平衡问题。其中类别不平衡问题是在实际中经常遇到的问题,其中给出的方法:1.对样例多的类别欠采样,这种在目标检测领域是这样做的:图像上一般会把大图裁剪为包含物体的小图,这样在遍历框时包含类别的几率就会升高;2.对样例少的类别过采样,在目标检测的分类过程会通过旋转平移扩增数据来增加样例,提升精度;3.再缩放,这中方法就包括在目标检测领域大名鼎鼎的Focal Loss[2],Focal Loss相当于提高了难分样本在损失函数里的权重,使得损失函数倾向于难分类的样本,有助于提高难分类样本(一般来说样本少的物体分类难度高)的准确度。
下面简单介绍一下Focal Loss:
L C = − ∑ c = 1 M y c ( 1 − p c ) γ log ( p c ) L_{C}=-\sum_{c=1}^{M} y_{c} \left(1-p_{c}\right)^{\gamma} \log \left(p_{c}\right) LC=−∑c=1Myc(1−pc)γlog(pc)
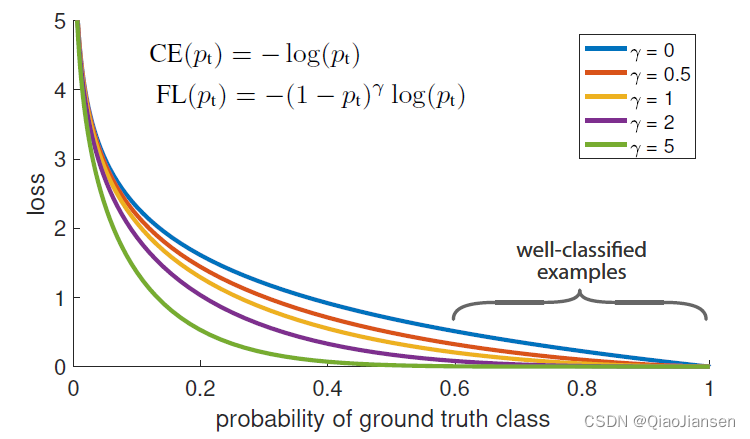
其中 y c y_{c} yc表示符号函数。如果样本的真实类别等于 c c c,则取1;否则,取0。 p c p_{c} pc是分类网络的输出,它表示观察到的样本属于类别 c c c的预测概率。 M M M是类别的数量 γ \gamma γ是一个超参数。设置 γ > 0 \gamma>0 γ>0可以减少分类良好的示例的相对损失( p c > 0.5 p_{c}>0.5 pc>0.5),这会使得网络更多地关注难以分类的示例。当一个例子被错误分类并且 p c p_{c} pc很小时,调节因子接近1并且损失不受影响。作为 p c p_{c} pc → \rightarrow → 1,因子变为0,分类良好的示例的损失函数被向下加权,也就是变小。这也就意味着增加了难分类样本在损失函数的权重,使得损失函数倾向于难分类的样本,有助于提高难分类样本(一般来说样本少的物体分类难度高)的准确度。
致谢
[1] 周志华. 《机器学习》[J]. 中国民商, 2016, 03(No.21):93-93.
[2] Lin T Y , Goyal P , Girshick R , et al. Focal Loss for Dense Object Detection[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, PP(99):2999-3007.















 118
118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









