






用leaning to rank做广告重点词——工作学习中的一点体会
最近需要一个query中的重点词,这里分享一下开发的过程和心得
导读:
一、先贴结果
二、我们可以有那些特征
三、leaning to rank
四、怎么改进?
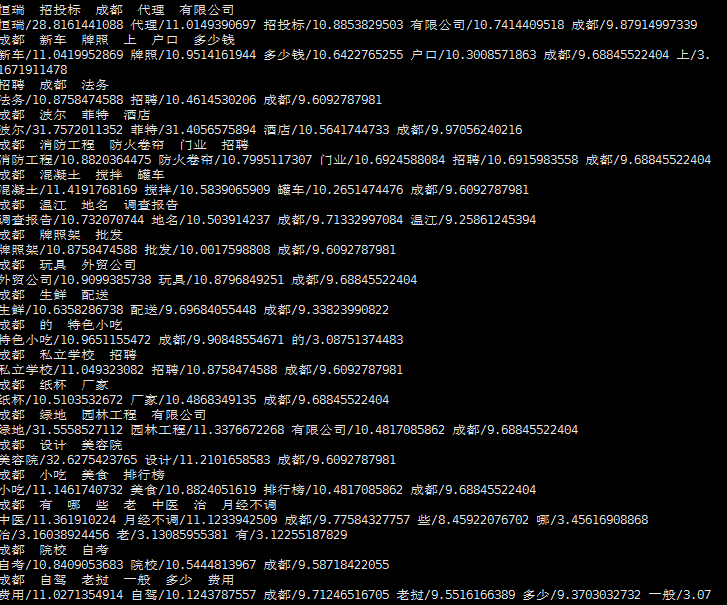
一、先贴结果
第一行是分词后的query
第二行是重点词排序的结果
二、我们可以有那些特征
1、 词的tfidf
2、 词在用户历史点击session中被替换的次数(subtfidf)
3、 词性
4、 前后词性(这个其实步长可以多几位,比如前前的词性,前前前的词性,实践中每多增加一种指标都会有提高,还是挺好用的)
5、 [词的熵值](一个term单独出现的频次越高,而且和其他term搭配出现的机会越少,那么我们可以肯定,这个term表达意图的能力越强,越重要)(https://www.zhihu.com/question/21104071/answer/36529209)
熵怎么使用可以参看:
http://blog.csdn.net/qjzcy/article/details/51728581
6、crf训练的词的重要度(主要考虑是crf能很好的考虑前后词之间的关系)
http://qtanalyzer.codeplex.com/
7、 是否停用词
8、 是否数字
9、 词在句子中的位置
10、 词长
11、 词是否前后缀词
三、leaning to rank
有了这些特征后需要对这些特征做一个整体的融合,于是rank又派上用场了
1、rank对我们来说很重要的一点是样本数据怎么来
我们发现在广告历史点击中,用session被替换的subtfidf来判断词的重要度比直接用tfidf要靠谱
原始数据:
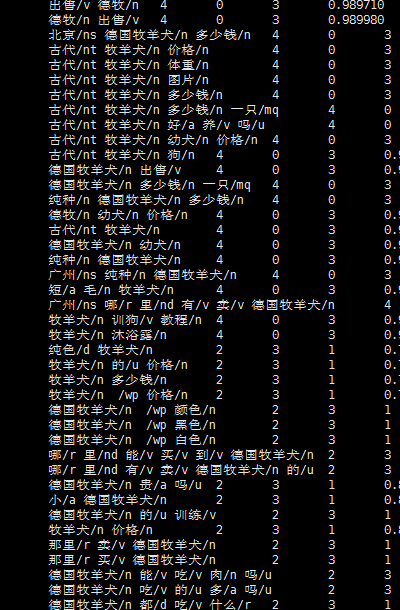
统计后的数据
中间(/t)分割左边是分词后的结果,右边是被替换次数排序的结果。右边小块格式:词/词性(被替换次数)

这时候再配上简单词性规则和人工筛选,这样可以得到一版样本集
四、怎么改进?
有没有更好的办法呢?
1、我感觉深度学习应该是一个方向,比如LSTM模型能很好结合前后文之间的关系,改天实验一版
2、特征可以再做一些组合
3、词性是个大制约因素,应该可以可以做的更细致一点
引用:
http://qtanalyzer.codeplex.com/
https://www.zhihu.com/question/21104071/answer/36529209















 193
193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









