









前些天 google 开源了 TensorFLow Lite,并且在 Android 8.1 版本上为 DSP、GPU、和神经网络芯片等硬件加速器支持了神经网络 API,为了在 Android 移动设备上全面支持 AI 做足了准备。下面是我根据官方的文章做了翻译,并且加入个人的一些理解,来介绍一下何为 NNAPI。另外神经网络的介绍可参考如下链接
神经网络 API
注意:Neural Networks API 只能在 Android 8.1 以及更高版本的系统中可用,其头文件同样只包含在最新的 NDK 版本中。
Android Neural Networks API (NNAPI) 是一个基于 Android 系统的用于可在移动设备上运行与机器学习相关的计算密集型操作的 C 语言 API,NNAPI 将为更高层次的可构建和训练神经网络的机器学习框架(如 TensorFLow Lite, Caffe2, 等等)提供底层支持。这些 API 将会集成到所有的 Android 8.1 (以及更高版本)设备上。
NNAPI 可支持一些在 Android 设备上已有的推理应用,以及开发者自定义的模型。这些推理应用例如图像分类,预测用户行为,和偏向性的关键字搜索。
AI 应用的本地化,即把 AI 运算直接在移动设备上执行,不需要通过网络与云端交互的好处有以下几点:
低延时: 你不再需要通过网络与云端交互,并且等待服务器响应。这对于需要成功地实时地从相机获得连续帧的视频应用来说是至关重要的。
有效性: 应用也可在网络覆盖不到的地方使用。
快: 相比只用 cpu 作为处理器来说,一些新的硬件加速器,如神经网络处理器可以提供更快的运行速度。
私密性: 这些数据只存在于本地设备上。
低成本: 当所有的 AI 运算都在本地设备上执行时,将不再需要服务器群组。
同样,也需要开发者折中考虑以下几点:
系统使用率: 神经网络将会牵涉到大量的计算量,这会消耗一些电池电量。你可以在你的app 中考虑监控电池状态,由其在长时间的计算情况下。
应用大小: 必须注意你的模型大小。模型可能会消耗非常多的存储空间。如果你的 APK 中存放了大型模型,这将会影响你的用户体验,你可以考虑在 app 安装之后再把模型下载下来,或者使用小型模型,再或者把你的 AI 运算放到云端。NNAPI 是不支持云端运行模型的。
了解神经网络API 运行时
NNAPI 基本就是提供给机器学习库和机器学习框架在 Android 设备上调用的。App 不能直接使用 NNAPI,但可通过更高级别的机器学习框架间接地使用。这些机器学习框架可通过 NNAPI 使用指定的硬件加速器。
基于 app 的需求和移动设备上的硬件能力,Android 的神经网络运行时能很好地根据给定的硬件分配各自的计算量,包括专用的神经网络硬件,图像处理单元(GPU),以及数字信号处理器(DSP)。
在一些没有硬件加速器的设备上,NNAPI 运行时会以优化代码的方式把这些 AI 运算放到 CPU 上运行。
下图描述了一个 NNAPI 高层级的系统架构
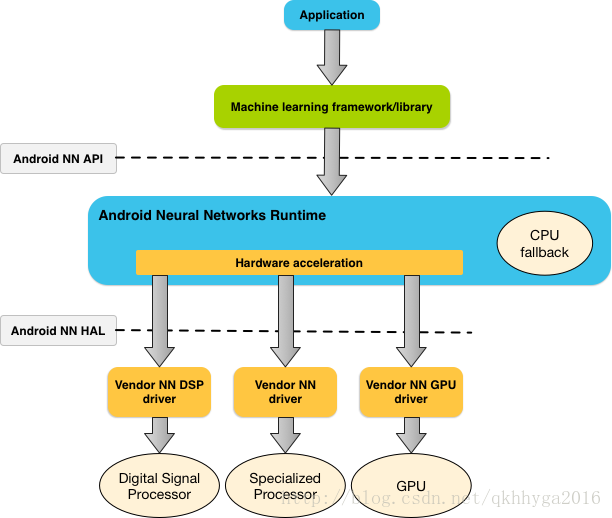
神经网络 API 编程模型
用 NNAPI 去做一些运算时,首先需要构建一个定义了具体运算的定向图(directed graph)。这个定向图将连接你的输入数据(例如,从机器学习框架中传下来的权重和偏移量),然后形成为 NNAPI 运行时的模型。
NNAPI 使用了以下 4 个主要的抽象概念:
模型: 是一个包含了数学运算和已训练好的数据的计算图。这些都是神经网络相关运算,包括 2 维卷积,逻辑(Sigmoid)激活,修正线性激活(ReLU),等等。创建模型是一个同步操作,一旦创建成功,模型将可以跨线程和跨编译器使用。在 NNAPI 中,模型可被描述为一个 ANeuralNetworksModel 实例。
编译器: 是一个用于把 NNAPI 模型编译成机器码的配置。创建编译器是一个同步操作,一旦创建成功,将可以跨线程和跨执行器使用。在 NNAPI 中,每个编译器都可被描述为 ANeuralNetworksCompilation 实例。
内存缓冲区: 是一个共享内存,文件映射内存,或者普通的内存缓冲区。使用内存缓冲区来让 NNAPI 运行时与驱动进行数据交互是很高效的。通常在 app 中创建一个模型同时需要创建一个包含了每个张量数组的共享内存缓冲区。除些之外,你同样可以使用内存缓冲区去保存执行器实例所需的输入和输出数据。在NNAPI 中,每个内存缓冲区都可被描述为一个 ANeuralNetworksMemory 实例。
- 执行器:是一个把 NNAPI 模型应用到输入数据集并得出结果的接口。它是一个异步操作,多线程都能等待相同的执行器,当执行器完成工作,所有线程将会被释放等待。在 NNAPI 中,每个执行器都可被描述为 ANeuralNetworksExecution 实例。
下图所示的是基本的编程流程
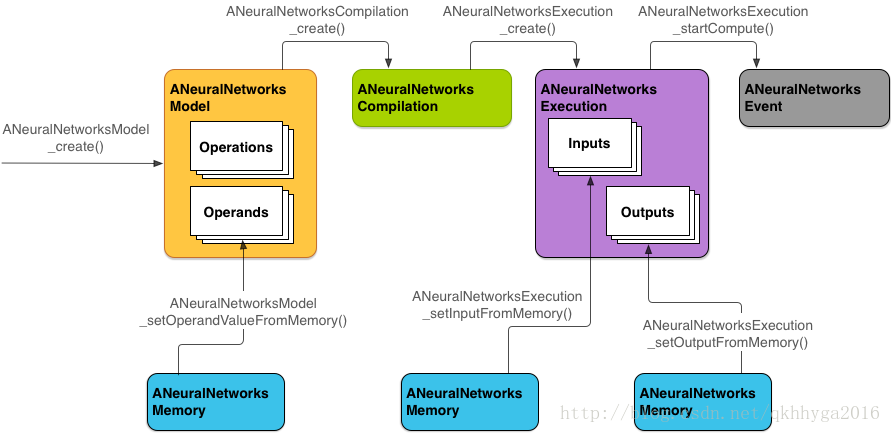
以下是按照该编程流程一步步地实现 NNAPI 模型运算,创建模型,编译模型,和执行已经编译的模型。
提供一组可访问的训练数据
已经训练好的权重和偏置项都可存放在文件中,然后通过 ANeuralNetworksMemory_createFromFd() 函数创建 ANeuralNetworksMemory 实例并为 NNAPI 运行时提供这些数据,在函数中传入文件描述符即可。
// Create a memory buffer from the file that contains the trained data.
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);在例子中虽然只用了一个 ANeuralNetworksMemory 实例,其实在实际运用中可以通过多个文件来创建多个实例。
模型
模型是 NNAPI 计算的基本单位,一个模型是由一个或者多个操作数和运算来定义的。
操作数
操作数是指在运算图中的数据对象。包括模型的输入输出数据,和从一个运算流向另一运算过程中包含的中间数据。在 NNAPI 模型中的操作数有两种类型:标量和张量(简单来说就是单一常量和n维数组)
标量代表着一个单一的数字。NNAPI 支持的标量类型有32位浮点,32位整型,32位无符号整型。
大多数的 NNAPI 操作数都涉及到张量,张量是一个 n 维数组。NNAPI 支持的张量类型有32位整形,32位浮点,和8位量化值。
以下举例说明一下,下图所示为一个完整的模型,其中有两个运算,一个是加法,随后是乘法,其中包括了模型的输入张量和输出张量。
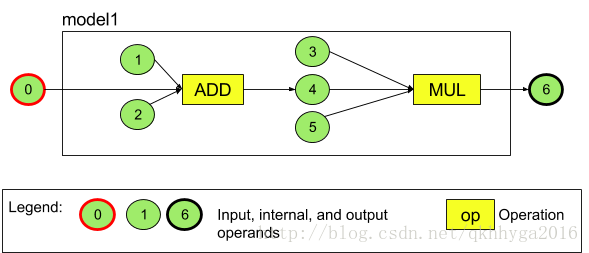
以上模型中有 7 个操作数(绿色圆圈代表一个操作数),这 7 个操作数是以加入该模型中的顺序进行编号的,如第一个加入该模型的操作数被标为 0 ,第二个加入模型的操作数被标为 1,如此类推。
操作数是有类型的。它们在被添加到模型中时指定。一个操作数不能同时用作模型的输入和输出。
更多关于使用操作数的话题可参考下面更多关于操作数一节。
运算
一个运算指定了具体的运算规则,运算包括以下几个元素:
- 一个运算类型(如:加法,乘法,卷积)
- 一组用于该运算的输入数据的操作数编号
- 一组用于存储该运算后输出数据的操作数编号
这一组操作数编号的顺序是很重要的,更多关于运算类型可参考 NNAPI API reference。
在把运算加入到模型中之前必须指明该运算的输入和输出的操作数。
加入到模型中的顺序是跟模型执行运算的顺序没关系的,因为 NNAPI 可以根据这个运算图来决定操作的执行顺序。
NNAPI 可支持的运算总结到如下表, 具体的运算说明可参考链接
| Category | Operations |
|---|---|
| Element-wise mathematical operations | ANEURALNETWORKS_ADD ANEURALNETWORKS_MUL ANEURALNETWORKS_FLOOR |
| Array operations | ANEURALNETWORKS_CONCATENATION ANEURALNETWORKS_DEPTH_TO_SPACE ANEURALNETWORKS_DEQUANTIZE ANEURALNETWOKRS_RESHAPE ANEURALNETWORKS_SPACE_TO_DEPTH |
| Image operations | ANEURALNETWORKS_RESIZE_BILINEAR |
| Lookup operations | ANEURALNETWORKS_HASHTABLE_LOOKUP ANEURALNETWORKS_EMBEDDING_LOOKUP |
| Normalization operations | ANEURALNETWORKS_L2_NORMALIZATION ANEURALNETWORKS_LOCAL_RESPONSE_NORMALIZATION |
| Convolution operations | ANEURALNETWORKS_CONV_2D ANEURALNETWORKS_DEPTHWISE_CONV_2D |
| Pooling operations | ANEURALNETWORKS_AVERAGE_POOL_2D ANEURALNETWORKS_L2_POOL_2D ANEURALNETWORKS_MAX_POOL_2D |
| Pooling operations | ANEURALNETWORKS_AVERAGE_POOL_2D ANEURALNETWORKS_L2_POOL_2D ANEURALNETWORKS_MAX_POOL_2D |
| Activation operations | ANEURALNETWORKS_LOGISTIC ANEURALNETWORKS_RELU ANEURALNETWORKS_RELU1 ANUERALNETWORKS_RELU6 ANEURALNETOWORKS_SOFTMAX ANEURALNETWORKS_TANH |
| Other operations | ANEURALNETWORKS_FULLY_CONNECTED ANEURALNETWORKS_LSH_PROJECTION ANEURALNETWORKS_LSTM ANEURALNETWORKS_RNN ANEURALNETWORKS_SVDF |
构建模型
以下是构建一个模型的步骤
调用 ANeuralNetworksModel_create() 函数构建一个空的模型
以上图所示的模型为例,构建一个 NNAPI 模型。ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);调用 ANeuralNetworks_addOperand() 函数在已经构建的模型中增加操作数,操作数的数据类型可参考 ANeuralNetworksOperandType
// In our example, all our tensors are matrices of dimension [3, 4]. ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are useful for quantized tensors. tensor3x4Type.zeroPoint = 0; // These fields are useful for quantized tensors. tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims; // We also specify operands that are activation function specifiers. ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL; // Now we add the seven operands, in the same order defined in the diagram. ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6调用 ANeuralNetworks_setOperandValue() 和 ANeuralNetworks_setOperandValuesFromMemory() 函数把已经训练好的权重和偏置项加载到操作数中。
在下面的代码中,mem1 为上面使用内存缓冲区装载的训练好数据。// In our example, operands 1 and 3 are constant tensors whose value was // established during the training process. const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize. ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor); // We set the values of the activation operands, in our example operands 2 and 5. int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));调用 ANeuralNetworks_addOperation() 函数在模型中增加运算
调用该函数时需要传入以下参数- 运算类型
- 输入操作数的个数
- 一个存放了输入操作数编号的数组
- 输出操作数的个数
- 一个存放了输出操作数编号的数组
请注意,一个操作数不能既作为输入又作为输出。
// We have two operations in our example. // The first consumes operands 1, 0, 2, and produces operand 4. uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes); // The second consumes operands 3, 4, 5, and produces operand 6. uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);调用 ANeuralNetworksModel_identifyInputsAndOutputs() 函数指定哪些操作数是整个模型的输入和输出。
// Our model has one input (0) and one output (6). uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);调用 ANeuralNetworksModel_finish() 函数来结束模型的构建,如果成功构建将返回 ANEURALNETWORKS_NO_ERROR 值。
ANeuralNetworksModel_finish(model);一次成功构建的模型可供编译和执行多次
编译
对模型进行编译是取决于你的模型运行于哪种硬件加速器上,当一个模型构建完后,需要为其进行编译才能真正跑在硬件加速器上,最终会生成对应硬件加速器的机器码,并告知硬件加速器的驱动将要执行该模型。
编译模型需要以下几个步骤:
调用 ANeuralNetworksCompilation_create() 函数创建新的编译器实例
// Compile the model. ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);可以调用 ANeuralNetworksCompilation_setPreference() 函数来支配运行时的功耗和性能
// Ask to optimize for low power consumption. ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);- ANEURALNETWORKS_PREFER_LOW_POWER: 节能,往往运用于在长时间的执行情况下。
- ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER:尽可能以最快速度执行,不管电池电量的消耗。
- ANEURALNETWORKS_PREFER_SUSTAINED_SPEED:以最大化吞吐量执行,比如处理相机的连续帧的情况下。
最后调用 ANeuralNetworksCompilation_finish() 函数结束编译器定义,成功将返回ANEURALNETWORKS_NO_ERROR。
ANeuralNetworksCompilation_finish(compilation);
执行
在执行模型时,需要给定输入数据集合,以及用于存放输出数据的内存缓冲区,这些都需要 app 去创建。
以下是执行的步骤:
调用 ANeuralNetworksExecution_create() 创建新的执行器实例。
// Run the compiled model against a set of inputs. ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);调用 ANeuralNetworksExecution_setInput() 或者 ANeuralNetworksExecution_setInputFromMemory() 函数来设置输入 数据集合
重要:在你调用 ANeuralNetworksModel_identifyInputsAndOutputs() 函数为模型指定输入和输出的操作数时已经指定了哪些操作数编号是输入,哪些操作数编号是输出,在为这些输入操作数设置数据时不要混淆了这些编号。
// Set the single input to our sample model. Since it is small, we won’t use a memory buffer. float32 myInput[3, 4] = { ..the data.. }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));调用 ANeuralNetworksExecution_setOutput() 或者 ANeuralNetworksExecution_setOutputFromMemory() 函数来指定模型输出的数据集合存入的内存缓冲区。
// Set the output. float32 myOutput[3, 4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));调用 ANeuralNetworksExecution_startCompute() 函数启动执行,成功则返回 ANEURALNETWORKS_NO_ERROR。
// Starts the work. The work proceeds asynchronously. ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);调用 ANeuralNetworksEvent_wait() 函数等待硬件执行结束,成功则返回 ANEURALNETWORKS_NO_ERROR,前面提到了,执行操作是异步操作,所以多线程可同时调用该函数等待执行结束。
// For our example, we have no other work to do and will just wait for the completion. ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1);前面提到的,当一个模型创建完成后,可供不同线程使用该编译好的模型,只需要给定不同的输入数据集合以及创建新的 ANeuralNetworksExecution 实例。
// Apply the compiled model to a different set of inputs. ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);清除
释放所有用于模型运算的资源,如下:
// Cleanup
ANeuralNetworksCompilation_free(compilation);
ANeuralNetworksModel_free(model);
ANeuralNetworksMemory_free(mem1);更多关于操作数
以下章节是关于操作数的更高级应用。
Quantized tensors
这个名词不清楚其中文的专业术语是什么,量化数组?所以只能用英文来描述,它是一个描述 n 维浮点形数组的简单描述方式。
NNAPI 支持 8 位非对称量化数组,里面每一个元素都是 8 位整数,其实代表的是 8 位浮点数,与这些量化数组相关的有刻度(scale)和零点值(zero point value),这些是用来把 8 位整数变换为 8 位浮点数。
其公式如下:
(cellValue - zeroPoint) * scalezeroPoint value 是一个32位整形数,也是一个刻度 32 位浮点数的值。
对比 32 位浮点张量(其实就是32位浮点形的数组),8 位 quantized tensors(其实就是 8 位整形的数组)有以下几点优势:
- 你的应用占用的空间会更小,用作表示已经训练好的权重的话,可以节约四分之3的存储空间。
- 运算更快,由于从内存中取出更少的数据和这些数据在处理器执行更有效率,如 DSP 更适合处理整形数。
虽然可以将浮点模型转换为量化模型,但我们的经验表明,通过直接训练量化模型(quantized model)可以获得更好的结果。实际上,神经网络会补偿每个值的增加粒度。针对每一个quantized tensors,刻度(scale)和零点值(zero point value)是在训练过程中确定。
在 NNAPI 中,可以通过在定义操作数数据类型时指定 ANeuralNetworksOperandType 结构体中的 type 变量为 ANEURALNETWORKS_TENSOR_QUANT8_ASYMM 来定义量化数组类型,同时也必须设置刻度(scale)和零点值(zeroPoint)。















 325
325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









