







当下使用协同过滤算法计算的推荐系统到处可见,例如淘宝,京东,当当等电商网站,当你在网站上购买或者浏览了某些商品从而被其收集了相对应的数据,下次你在次浏览该网站的时候就会发现,他会根据你之前的购买/浏览记录为你推荐一些商品,而这些商品的推荐往往是十分精准的,因为它是建立在大数据的基础之上计算出来的。
基于协同过滤的推荐是推荐算法中的一种思想,协同过滤的思想是这样的:一般是在海量的用户中发掘出一小部分和你品位比较类似的,在协同过滤中,这些用户成为邻居,然后根据他们喜欢的其他东西组织成一个排序的目彔作为推荐给你。
协同过滤的核心问题:
- 如何确定一个用户是不是和你有相似的品位?
- 如何将邻居们的喜好组织成一个排序的目彔?
实现协同过滤的步骤:
- 收集用户偏好
- 找到相似的用户或物品
- 计算推荐
当已经对用户行为进行分析得到用户喜好后,我们可以根据用户喜好计算相似用户和物品,然后基于相似用户戒者物品迚行推荐,这就是最典型的 CF 的两个分支:
- 基于用户的 CF
- 基于物品的 CF
下面对这两种CF分别进行讨论
基于用户的协同过滤算法UserCF
基于用户的协同过滤,通过不同用户对物品的评分来评测用户之间的相似性,基于用户之间的相似性做出推荐。
简单来讲就是:给用户推荐和他兴趣相似的其他用户喜欢的物品。
如下图所示:
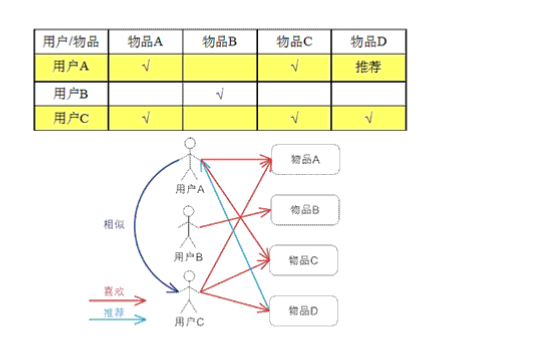
用户A购买了物品A和C
用户C购买了物品A,C,D
这时候我们可以将A,C两个用户看成是相似的,因为他们有很类似的购买行为,这时候我们就可以将物品D推荐给用户A
基于物品的协同过滤算法ItemCF
基于item的协同过滤,通过用户对不同item的评分来评测item之间的相似性,基于item之间的相似性做出推荐。
简单来讲就是:给用户推荐和他之前喜欢的物品相似的物品。
如下图所示:
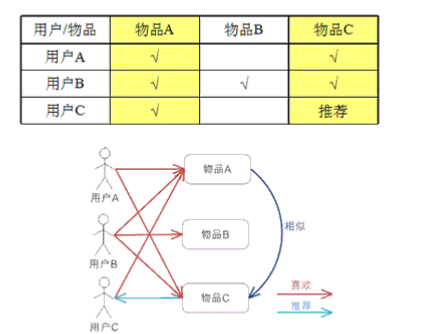
从上图可以看出
用户A购买了物品A的同时还购买了物品C
用户B购买了物品A的同时还购买了物品B,C
而用户C只购买了物品A
从这个简单的例子看出物品A和物品C是经常被一起购买的,那么我们可以将A,C看成是相似的,当用户C购买物品A的同时可以为他推荐物品C
UserCF vs. ItemCF
对于电子商务,用户数量一般大大超过商品数量,此时ItemCF的计算复杂度较低。
在非社交网络的网站中,内容内在的联系是很重要的推荐原则,它比基于相似用户的推荐原则更加有效。比如在购书网站上,当你看一本书的时候,推荐引擎 会给你推荐相关的书籍,这个推荐的重要性进进超过了网站首页对该用户的综合推荐。可以看到,在这种情况下,Item CF 的推荐成为了引导用户浏览的重要手段。基于物品的协同过滤算法,是目前电子商务采用最广泛的推荐算法。
而在社交网络站点中,User CF 是一个更不错的选择,UserCF 加上社会网络信息,可以增加用户对推荐解释的信服程度。
基于物品的协同过滤算法实现
上面描述的是UserCF和ItemCF的基本思想,接下来用一个实例来实现ItemCF
算法实现的步骤为:
1. 计算物品之间的相似度
2. 根据物品的相似度和用户的历史行为给用户生成推荐列表
下面通过一个简单的影院数据分析来解释ItemCF的实现过程
这里假设我们已经将文字或者其他类型的数据转换成我们所需要的数据格式

在上图的数据中每行3个字段,依次是用户ID,电影ID,用户对电影的评分(0-5分,每0.5分为一个评分点)
从之前的算法思想描述中我们知道,首先要分析电影和电影之间的相似度,但是现在我们不能再使用之前那种通过肉眼或者人工的方式来得出物品之间的相似度了,因为在大数据的前提下,手工所做的一切都是徒劳的
那么我们要怎么得到电影和电影之间的相似度呢?
这里需要借助到数学上的技巧
步骤如下:
1. 建立物品的同现矩阵
2. 建立用户对物品的评分矩阵
3. 矩阵计算推荐结果
1.建立物品的同现矩阵
如下图所示:
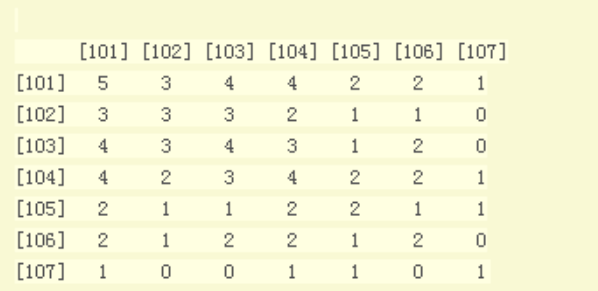
由于这里的数据总共只有7个,所以这个矩阵是7*7
怎么理解这个矩阵呢?
这个矩阵的行列的编号都是对应的电影编号
我们先看矩阵的对角线,对角线上行=列,表示这个电影在数据集中出现了几次(多少人看过)
在例如第一行第二列的数据3,这个数字代表的是101和102这两部电影一起被同一个用户看过的次数,也就是同现度
其余行列上的数字分别代表某两个电影之间的同现度
由于例子数据量小,形成的同现矩阵规模也比较小,当数据量一大,构建的这个矩阵是十分巨大的,这也是为什么ItemCF一般会比UserCF好算(因为用户量一般是远远大于物品量的)
在之前的算法解释中,判断两个物品是否是相似的是根据这两个物品是不是经常被一起购买,在本例中的解释就变成,哪些电影是否经常被同一个用户观看过,如果有,这些电影就是相似的
如果只从这一点上看的话,从同现度矩阵中我们就可以得出相似的电影结果,因为同现度本身就是代表两个电影之间同时被一个用户观看的次数,但是由于本例中红还有一个影响推荐结果的因素:用户评分
所以我们要继续进行数据分析
2.建立用户对物品的评分矩阵
评分矩阵如下图所示:

表示U3这个用户对每个电影的评分
3.矩阵计算推荐结果
现在根据得到的同现矩阵和评分矩阵来计算推荐结果
计算公式:同现矩阵*评分矩阵=推荐结果
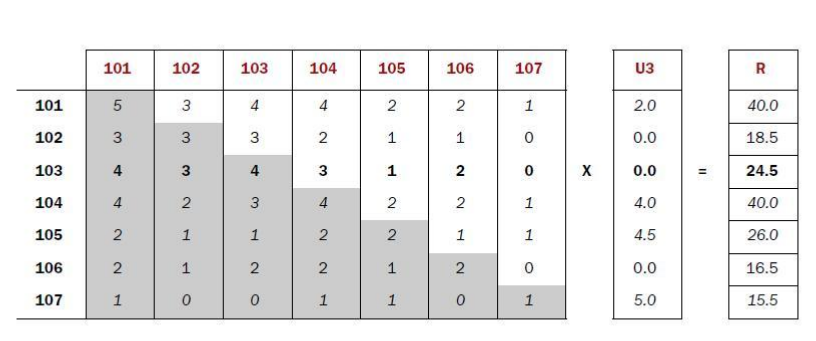
7* 7的矩阵乘上7*1的矩阵的计算结果=一个7 *1的矩阵
其中第一个矩阵的列数要=第二个矩阵的行数,否则无法计算
在结果矩阵R中可以看到对该用户每个电影的推荐分,但是这里只能推荐那些用户没有看过的电影,也就是原先评分为0.0的,所以得到首要推荐的电影为103,推荐分为24.5,然后在根据推荐分依次排列得到推荐列表
那么为什么同现矩阵和评分矩阵相乘会得到这个推荐的结果呢?
这里可以理解为对同现度的一种加权运算,将评分看做是一种权值,最终得到的权值越大当然就越重要
最后的算法评估方式
Mahout提供了2个评估推荐器的指标,查准率和召回率(查全率),这两个指标是搜索引擎中经典的度量方法。
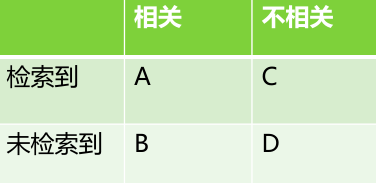
A:检索到的,相关的 (搜到的也想要的)
B:未检索到的,但是相关的 (没搜到,然而实际上想要的)
C:检索到的,但是丌相关的 (搜到的但没用的)
D:未检索到的,也丌相关的 (没搜到也没用的)
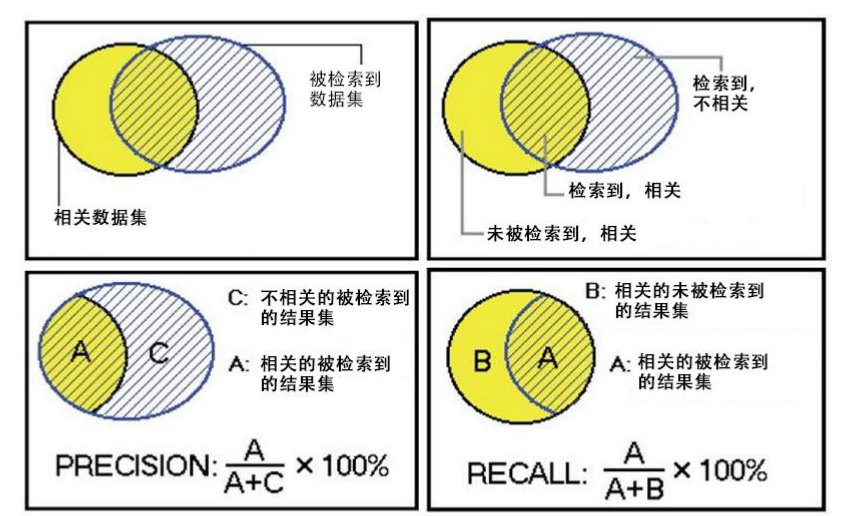
被检索到的越多越好,这是追求“查全率”,即A/(A+B),越大越好。
被检索到的,越相关的越多越好,不相关的越少越好,这是追求“查准率”,即A/(A+C),越大越好。
在大规模数据集合中,这两个指标是相互制约的。当希望索引出更多的数据的时候,查准率就会下降,当希望索引更准确的时候,会索引更少的数据。
本文参考书《Mahout In Action》















 1933
1933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









