






P-tuning论文概述
GPT Understands, Too
前言
近年来,预训练语言模型取得了巨大成功,不仅能够学习上下文表示,还能够掌握语法、句法等知识。根据训练目标,语言模型主要分为三类:单向语言模型(如GPT)常用于自然语言生成,双向语言模型(如Bert)则广泛应用于自然语言理解,而混合语言模型(如XLNet)则综合了两者。
传统观念认为,像GPT这样的单向语言模型不适用于自然语言理解任务,但是GPT-3在手工prompt的情况下展现出惊人的性能,特别是在少样本和零样本情境下。这证明了在适当的prompt下,超大规模的单向语言模型在自然语言理解任务上同样表现出色。然而,手工设计prompt会耗费大量人力和实验成本,并且如果prompt设计不当,可能导致显著的性能下降。此外,由于神经网络的连续性特性,离散的prompt并非最佳选择。
最近的研究提出通过挖掘训练语料库(Jiang等人,2020b)、基于梯度的搜索(Shin等人,2020)和使用预训练生成模型(Gao等人,2020)来自动化离散提示的搜索过程。然而,这些工作旨在寻找性能更好的提示,但不改变离散提示的不稳定性。
为了解决这些问题,作者提出了P-tuning方法,旨在自动搜索连续的prompt,以便将GPT有效应用于自然语言理解任务。
摘要
用自然语言模式提示预训练的语言模型已被证明对自然语言理解 (NLU) 有效。
然而,我们的初步研究表明,手动离散提示通常会导致性能不稳定。例如,在提示中更改单个单词可能会导致性能大幅下降。
我们提出了一种新方法 P-Tuning,它在与离散提示连接中使用可训练的连续提示嵌入。根据经验,P-Tuning 不仅通过最小化各种离散提示之间的差距来稳定训练,而且还在广泛的 NLU 任务(包括 LAMA 和 SuperGLUE)上以相当大的优势提高了性能。
在完全监督和少镜头设置下,P-Tuning对于冻结和调优的语言模型通常都是有效的。

论文十问
- 论文试图解决什么问题?
手动离散提示会倒置性能不稳定(更改一个单词就会造成性能的下降),P-Tuning大大减少了不同离散提示之间的性能差距,从而提高了语言模型适应的稳定性。
- 这是否是一个新的问题?
这是一个新的问题,之前的研究考虑的是提高prompt性能,而不是稳定性。
- 这篇文章要验证一个什么科学假设?
这篇文章主要验证连续的prompt可以提高性能和稳定性。
- 有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
相关研究包括discrete prompt搜索方法(如AutoPrompt,LPAQA等)。值得关注的研究员有Zhilin Yang, Jie Tang等。
- 论文中提到的解决方案之关键是什么?
关键解决方案是提出了P-Tuning,使用连续的prompt嵌入与离散prompt拼接,使prompt可微分优化。
- 论文中的实验是如何设计的?
实验设计了在LAMA知识检索和SuperGLUE完全监督/少样本学习三个设置下比较P-Tuning与多个baseline。
- 用于定量评估的数据集是什么?代码有没有开源?
使用的数据集有LAMA、SuperGLUE。代码已经开源
- 论文中的实验及结果有没有很好地支持需要验证的科学假设?
实验结果很好地支持了P-Tuning可以同时提高性能并增强稳定性的假设。
- 这篇论文到底有什么贡献?
主要贡献是提出P-Tuning方法,并在多个NLP基准任务上验证了其效果。
- 下一步呢?有什么工作可以继续深入?
下一步可以研究不同类型的prompt编码器,在更多下游任务中应用P-Tuning,或与其他prompt优化方法集成。
离散提示和P-tuning
离散提示:
- 依赖自然语言模式作为额外输入,用于适应下游任务。
- 手动写作的离散提示在不同的任务上表现可能不稳定。
- 在冻结的语言模型中,改变提示中的单个词可能导致性能显著下降。
P-Tuning:
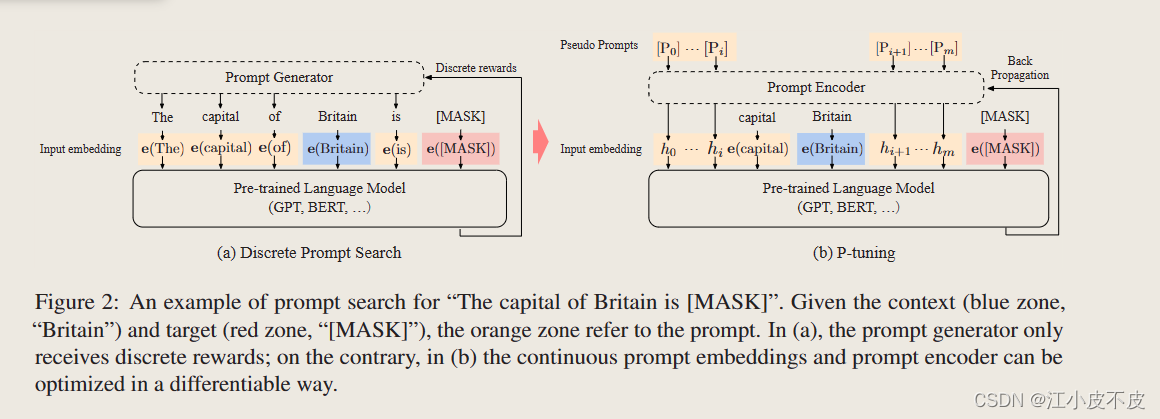
- 使用可训练的连续提示嵌入与离散提示相结合。
- 通过反向传播更新连续提示以优化任务目标。
- 可以在冻结和微调的语言模型中更好地稳定性能。
- 可以提高在不同离散提示之间的性能差距,从而改善语言模型适应的稳定性。
如下图所示,P-tuning通过一个函数将离散的提示映射为连续的提示(通过LSTM、MLP构建编码器进行离散映射)。
实验
知识探测
知识探测,或称为事实检索,评估语言模型从预训练中获得了多少真实世界的知识。
数据集
LAMA-TREx 数据集
评估方法
三元组创建的完形测试
方法:
-
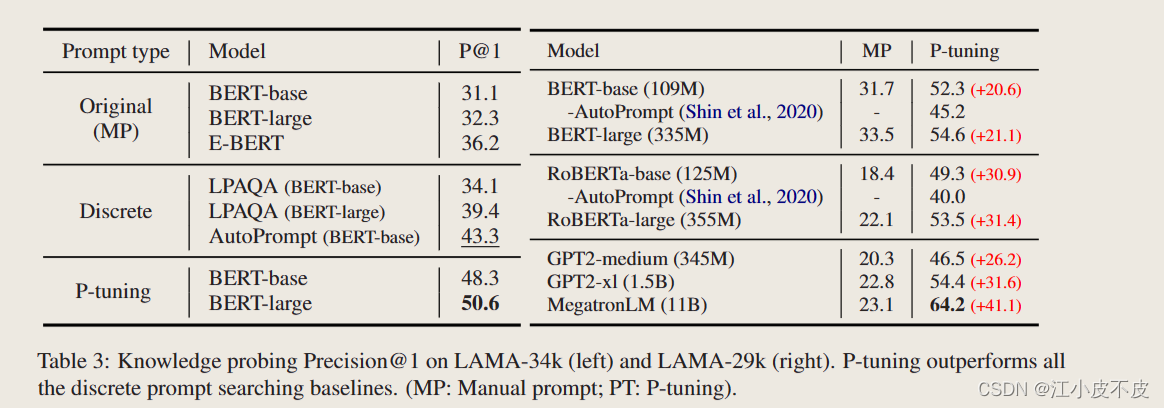
MP: Manual prompt 手动提示
-
Discrete 离散提示
-
PT: P-tuning
模型
Bert、GPT2等
实验结论
P-tuning 在 LAMA-34k 上显着提高了知识探测的最佳结果,在 LAMA-29k 上从 43.3% 提高到 50.6%,在 LAMA-29k 上从 45.2% 提高到 64.2%。
全监督学习
模型
-
BERT-Base
-
BERT-Large
-
GPT2-Base
-
GPT-medium.
数据集
SuperGLUE
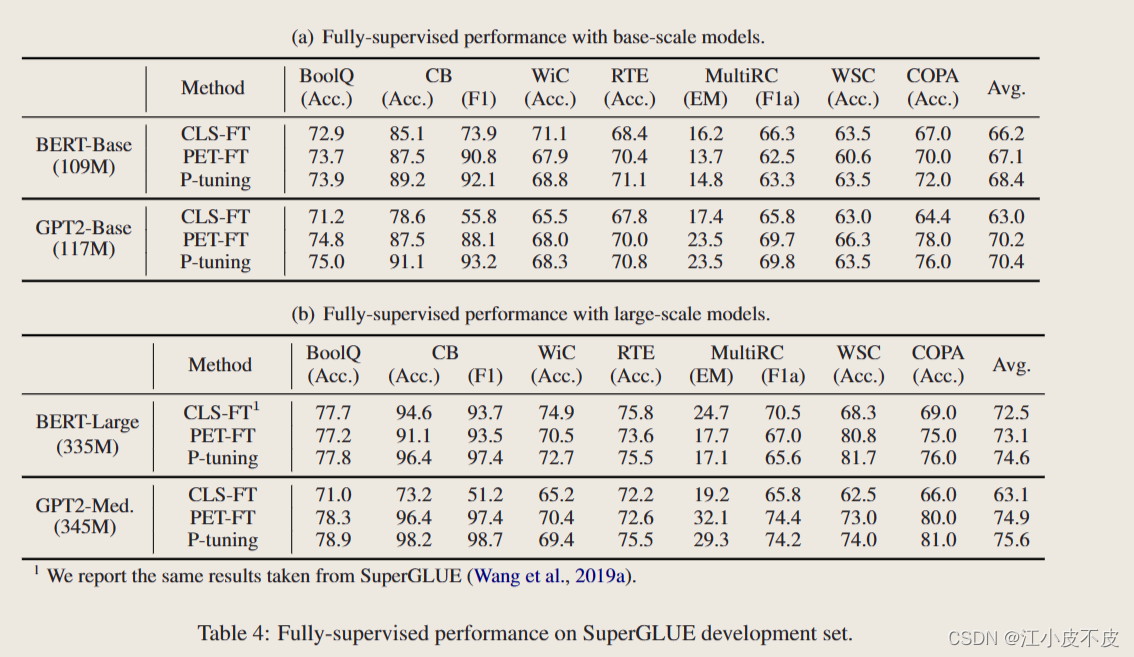
任务类型:问答(BoolQ 和 MultiRC)文本蕴涵(CB 和 RTE)共指解析(WiC)因果推理(COPA)词义消歧(WSC)
方法
比较的方法:分类微调、手动离散提示、P-tuning
实验结论
p-Tuning 方法在全监督学习任务上对 BERT 和 GPT 模型均有改进,特别是在低资源任务上。在高资源任务上,P-Tuning 的优势相对较小。
少量样本学习
数据集
SuperGLUE
评估方法
FewNLU评估方法:我们使用随机数据拆分仅在一个小的标记集上执行模型选择,以防止过度拟合大型开发集。
模型
ALBERTxxLarge
实验结论
我们发现,在 ALBERT 上,P-tuning 平均始终优于 PET 超过 1 个点。它的性能比 PromptTuning 高出 13 分以上。它证明,通过自动学习连续提示标记,预训练模型可以在 NLU 任务上取得更好性能。

提示的位置和数量
连续提示的位置和数量的选择如下:
- 位置:连续提示最好放在不切断句子的位置。例如,在句首或句尾,而不是在句内。此外,在输入的边缘和中间没有特殊偏好。
- 数量:连续提示的数量对模型性能有很大影响。但并不是提示数量越多越好。实际上,在有限的训练数据下,过多地增加连续提示数量可能会导致学习参数变得困难。因此,在实践中,应通过模型选择搜索最佳提示数量。
对模型性能的影响:
- P-Tuning(连续提示与离散提示的结合)在多个设置下都可以提高模型性能。
- P-Tuning 可以显著提高最差表现模式的性能,并在多个模式之间减小标准差,增加模型适应性的稳定性。
- 连续提示在冻结和调整语言模型的情况下,以及在少样本和全监督设置下,可以提高性能和稳定训练。这是与现有的基于离散提示的方法相比,P-Tuning所具有的优势。

提示编码器消融实验
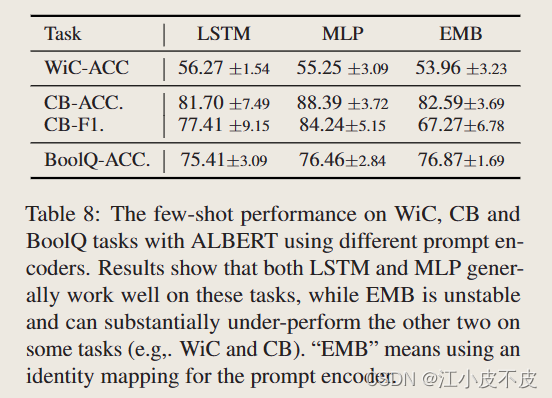
使用不同的提示编码器的ALBERT在WiC, CB和BoolQ任务上的少数镜头性能。
结果表明,LSTM和MLP在这些任务上都能很好地工作,而EMB则不稳定,在某些任务上的表现明显低于其他两者(例如:WiC和CB)。
结论
在本文中,我们提出了一种使用连续提示与离散提示串联的P-Tuning方法。p调优提高了性能并稳定了预训练语言模型适应的训练。P-Tuning在少镜头和完全监督的设置下对调优和冻结的语言模型都有效。
局限性
p-Tuning 方法在全监督学习任务上对 BERT 和 GPT 模型均有改进,特别是在低资源任务上。在高资源任务上,P-Tuning 的优势相对较小。
















 267
267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











