






P-Tuning : GPT Understands,Too 论文笔记
Introduction
LLM目前可以分为三类,Decoder-Only如GPT,Encoder-Only如BERT,还有Encoder- Decoder如T5、BART。
作者认为GPT在NLU任务fine-tune的表现不好,因此认为它不适合NLU的任务。然而GPT-3的横空出世,通过prompt的形式在当时摘下了许多任务的sota,但是找到一个好的prompt犹如大海捞针,甚至还可能会导致性能下降,作者任务离散的prompt可能不是最好的结果。
在这篇文章中,作者提出了一种新的方法:P- tuning,一种自动寻找最优的prompt的方法,它可以弥补GPT在NLU任务的差距。P- tuning用free parameters 作为LLM的输入,然后通过gradient decent优化这组参数来找找到最优的prompt。
这篇文章的主要贡献有一下两点:
- 通过P- tuning方法,作者证明GPT序列模型在NLU领域被低估了。
- 作者提出了一种新的通用微调方法P- tuning,并取得了当时的Sota。
Method:P-tuning
结构
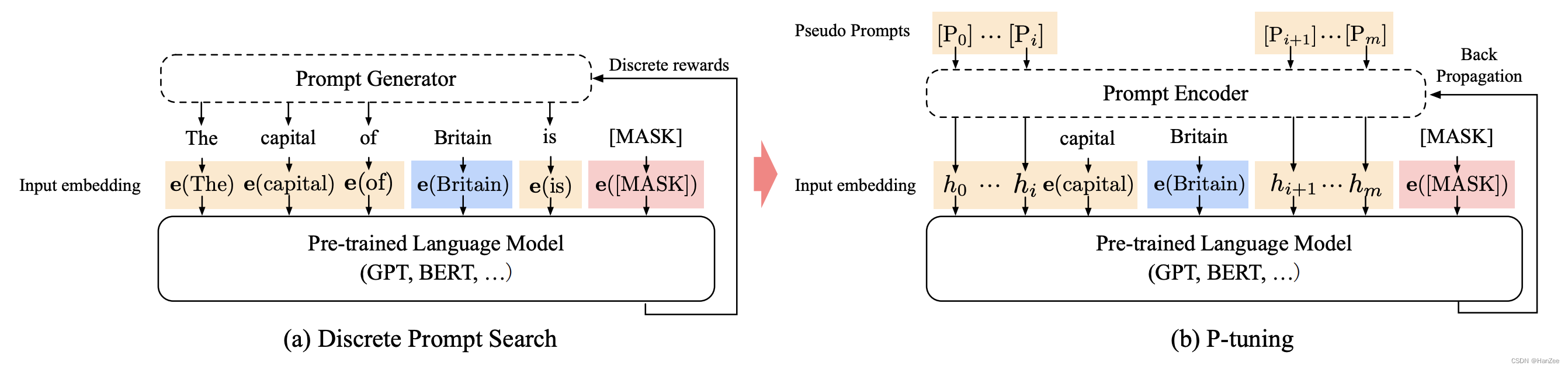
上图,其中黄色部分(The capital of…is…)为Prompt,蓝色部分为input x ,也叫做context,红色部分为我们想要的结果y,在上图中用MASK表示,这三个组成了输入的模版,如上图a部分。
作者把离散prompt换成了 pseudo token,相当于以前从来没见过token,定义为Pi,模版就变成了:
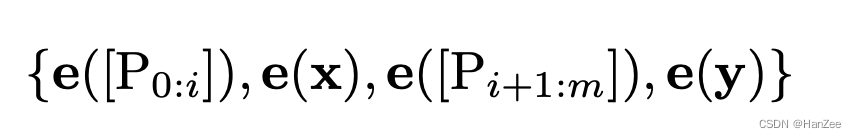
然后把Prompt embedding 后的结果定义为hi:
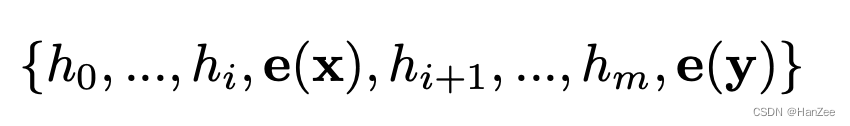
其中hi为可训练的tensor,然后通过特定的下游数据,冻结LLM参数,只训练hi,然后就得到了在特定任务下的最优的prompt,实验也证明了要比离散的prompt效果要好。
优化方法
如果下游数据量比较少,使用几个token,如果数据量足够,采取完全微调的方法。
issue
在论文中作者不是随机初始化,而是采用LSTM,为了让各个token相关。
代码
class PtuningEmbedding(Embedding):
"""新定义Embedding层,只优化部分Token
"""
def call(self, inputs, mode='embedding'):
embeddings = self.embeddings
embeddings_sg = K.stop_gradient(embeddings)
mask = np.zeros((K.int_shape(embeddings)[0], 1))
mask[1:9] += 1 # 只优化id为1~8的token
self.embeddings = embeddings * mask + embeddings_sg * (1 - mask)
return super(PtuningEmbedding, self).call(inputs, mode)
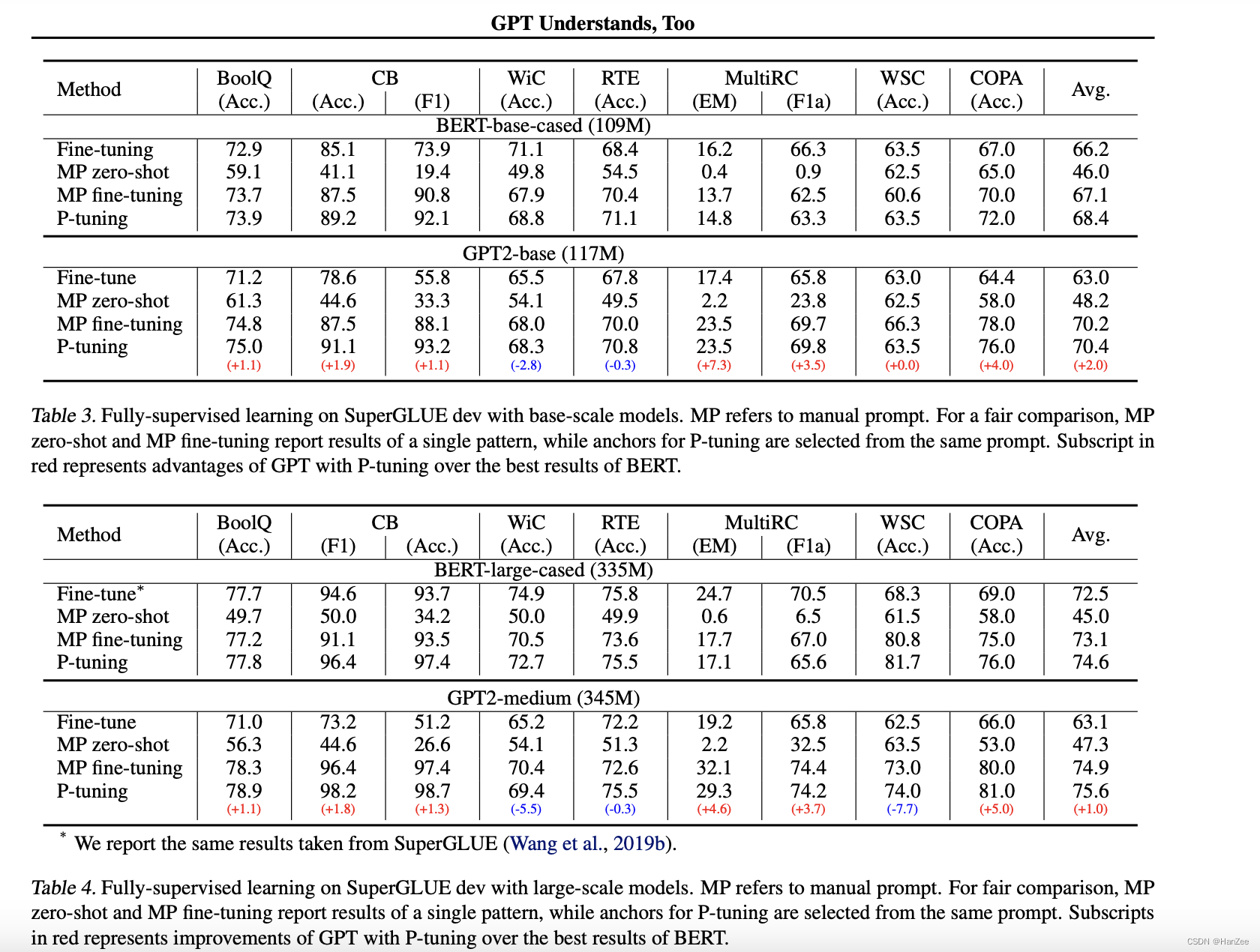
实验



















 2477
2477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











