







论文阅读笔记
Motivation
- 新兴的 GPT-3 及其在使用手工prompt模板在few-shot和zero-shot学习方面的成功表明,使用prompt learning的方案可以使大规模自回归预训练模型适用于自然语言理解;
- 过去的prompt learning方案过度依赖手工设计,针对一些较复杂任务不好设计,且人力成本高,让模型自己学习模板能够在效率和准确性两个维度上给这个任务带来提升。
Method
Architecture
P-tuning模型学习的目标是得到能最大化提示预训练模型根据给定输入 x x x预测标签 y y y的前缀模板 { p 1 , . . . , p m } \{p_1,...,p_m\} {
p1,...,pm}。
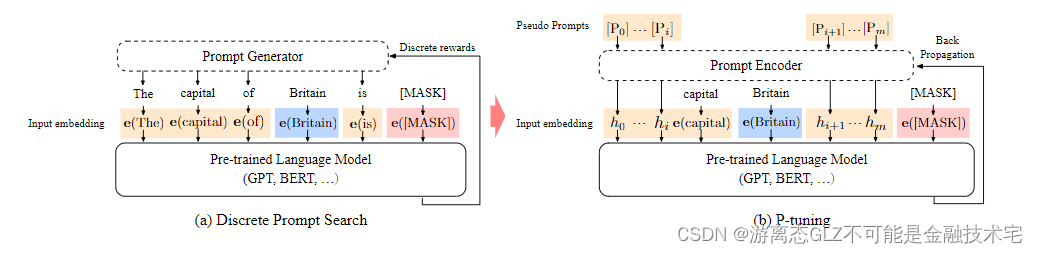
为此,模型首先构造这个前缀模板,论文中将输入x插入前缀模板内部,得到 { p 1 , . . . , p i , x , p i + 1 , . . . p m } \{p_1,...,p_i,x,p_{i+1},...p_m\} {
p1,...,pi,x,pi+1,...pm}。我认为可以根据需要组合提示模板,输入和输出的位置(注:根据苏剑林大佬的试验前缀效果最优 [ 2 ] ^{[2]} [2])。
而后通过embedding层和预训练模型映射得到隐向量:
e ( [ P 0 : i ] ) , e ( x ) , e ( [ P i +
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1033
1033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









