






VLLM + one-api + next-chat:打造私有化的聊天大模型
前言
本文讨论了如何使用 VLLM、OneAPI 和 ChatGPT-Next-Web 打造私有化的聊天大模型。首先介绍了 VLLM 的关键技术和部署方法,包括内存优化、推理加速、模型量化等,以及通过 docker 镜像进行部署和启动服务。接着阐述了 OneAPI 的概述、部署过程,包括启动镜像、登录、添加 API、测试渠道、添加令牌和使用服务等步骤。最后说明了 ChatGPT-Next-Web 的概述、特点和部署方法,包括拉取镜像、启动镜像和使用服务。
关键要点包括:
- VLLM:专门为大型语言模型推理和部署服务设计的高效库,关键技术有内存优化等,可通过 pip 或 docker 镜像部署。
- OneAPI:开放的接口管理和分发系统,支持多种大模型,能统一管理多个 API 并封装成一个。
- ChatGPT-Next-Web:开源聊天应用程序,自去年 ChatGPT 开始火爆以来,因其支持多端、功能强大、多种类型接口、内置多种角色等特点而备受关注。
项目地址
vLLM:https://github.com/songquanpeng/one-api
OneAPI:https://github.com/vllm-project/vllm?tab=readme-ov-file
ChatGPT-Next-Web:https://github.com/ChatGPTNextWeb/ChatGPT-Next-Web
vLLM
概述
vLLM 框架的关键技术包括内存优化、推理加速、模型量化等,这些技术共同作用,提升了大模型的运行效率。
- 服务吞吐量
- 使用PagedAttention高效管理注意力键和值内存
- 持续批处理传入请求
- 使用 CUDA/HIP 图快速执行模型
- 量化:GPTQ、AWQ、INT4、INT8 和 FP8。
- 优化的 CUDA 内核,包括与 FlashAttention 和 FlashInfer 的集成。
- 推测解码
- 分块预填充
部署
vLLM可以直接通过pip进行安装,但是可能会存在第三方库的冲突。
pip install vllm
推荐采用官方的docker镜像直接进行部署,这样能够保证开箱即用
docker pull vllm/vllm-openai:latest
docker pull vllm/vllm-openai:v0.6.2
如果无法通过dockerhub拉取镜像的话,可以通过国内的镜像源拉取
docker pull http://swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/vllm/vllm-openai:v0.6.1.post2
docker tag http://swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/vllm/vllm-openai:v0.6.1.post2 vllm-openai:v0.6.1.post2
服务启动
1. 启动docker并挂载你的大模型存储路径
docker run -itd --gpus all --name vllm-openai --net=host --rm -v /data/llm_models:/workspace/llm_models --shm-size=10.24gb --entrypoint /bin/bash vllm/vllm-openai:v0.6.2
2. 进入docker
docker exec -it 73cad70bb3ab4 bash
3. 启动vLLM大模型服务
在这里我启动了三个大模型推理服务:
- Llama-3.1-70B-Instruct-GPTQ-INT4:70B 量化 int4 的模型大概需要 45G 的显存。
- Qwen2-72B-Instruct-GPTQ-Int4:72B 量化 int4 的模型大概需要 48G 的显存大小。
- Qwen2___5-Coder-32B-Instruct-GPTQ-Int8 :32B 量化 int8 的模型大概需要 40G 的显存大小。
#Llama-3.1-70B-Instruct-GPTQ-INT4
$ nohup bash -c "CUDA_VISIBLE_DEVICES=2 python3 -m vllm.entrypoints.openai.api_server --model /workspace/llm_models/Llama-3.1-70B-Instruct-GPTQ-INT4 --dtype auto --host 0.0.0.0 --port 8012 --trust-remote-code --max-model-len 7000 --max-num-seqs 40 --tensor-parallel-size 1 --gpu-memory-utilization 0.96 --served-model-name llama --disable-log-requests" > llama72B.log 2>&1 &
#Qwen2-72B-Instruct-GPTQ-Int4
$ nohup bash -c "CUDA_VISIBLE_DEVICES=0,1 python3 -m vllm.entrypoints.openai.api_server --model /workspace/llm_models/Qwen2___5-72B-Instruct-GPTQ-Int4 --dtype auto --host 0.0.0.0 --port 7003 --trust-remote-code --max-model-len 10000 --max-num-seqs 60 --tensor-parallel-size 2 --gpu-memory-utilization 0.6 --served-model-name qwen --disable-log-requests" > qwen72B.log 2>&1 &
#Qwen2___5-Coder-32B-Instruct-GPTQ-Int8
$ nohup bash -c "CUDA_VISIBLE_DEVICES=3,4 python3 -m vllm.entrypoints.openai.api_server --model /workspace/llm_models/Qwen2___5-Coder-32B-Instruct-GPTQ-Int8 --dtype auto --host 0.0.0.0 --port 8011 --trust-remote-code --max-model-len 10000 --max-num-seqs 60 --tensor-parallel-size 2 --gpu-memory-utilization 0.49 --served-model-name qwen --disable-log-requests" > codeqwen32B.log 2>&1 &
对应的API分别是:
- base_url = http://192.168.1.1:8011 model=qwen
- base_url = http://192.168.1.1:8012 model=llama
- base_url = http://192.168.1.1:7003 model=qwen
4. 参数说明
- –model:模型路径
- –dtype:auto,half,float16,bfloat16,float,float32
- –api-key:用于openai调用
- –max-model-len:最长上下文
- –tensor-parallel-size:模型分块加载到不同GPU上
- –gpu-memory-utilization:限制GPU使用率
- –served-model-name:openai格式调用需要
- –max-num-seqs: 批量推理
- –disable-log-requests:禁用多余的日志
- –quantization:aqlm,awq,deepspeedfp,fp8,marlin,gptq_marlin_24,gptq_marlin,gptq,squeezellm,compressed-tensors,bitsandbytes,None
更多参数和api参考官方文档:
https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html
服务调用
1. 通过python进行调用
from openai import OpenAI
MAX_HISTORY_LEN=50
openai_api_key = "token-abc123"
openai_api_base = "http://x.x.x.x:7003/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
print(model)
for chunk in client.chat.completions.create(
messages=[
{"role": "user", "content": "你好"}
],
model=model,
stream=True
):
if hasattr(chunk.choices[0].delta, "content"):
print(chunk.choices[0].delta.content, end="", flush=True)
2. 通过api的方式进行调用
curl -X POST "http://x.x.x.x:7003/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer token-abc123" \
-d '{
"model": "qwen",
"messages": [
{
"role": "user",
"content": "你好"
}
],
"stream": false
}'
返回
{"id":"cmpl-df754762a6f14a0ba68ed4ce28ea8ee5","object":"chat.completion","created":1718072632,"model":"qwen","choices":[{"index":0,"message":{"role":"assistant","content":"你好!很高兴能为你提供帮助。有什么问题或需要解答的吗?"},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":20,"total_tokens":37,"completion_tokens":17}}
OneAPI
概述
OneAPI 是 OpenAI 的接口管理和分发系统,能够通过标准的 OpenAI API 格式访问所有大模型,支持智谱 ChatGLM、百度文心一言、讯飞星火认知、阿里通义千问、腾讯混元等国内大模型。
通过下图可以看出,OneAPI 能够将多个来源的 API 进行统一。在上文中,我们通过 vLLM 部署了 3 个模型,此时会生成 3 个 API 地址,这时就可以用 OneAPI 进行统一管理,封装成一个 API。
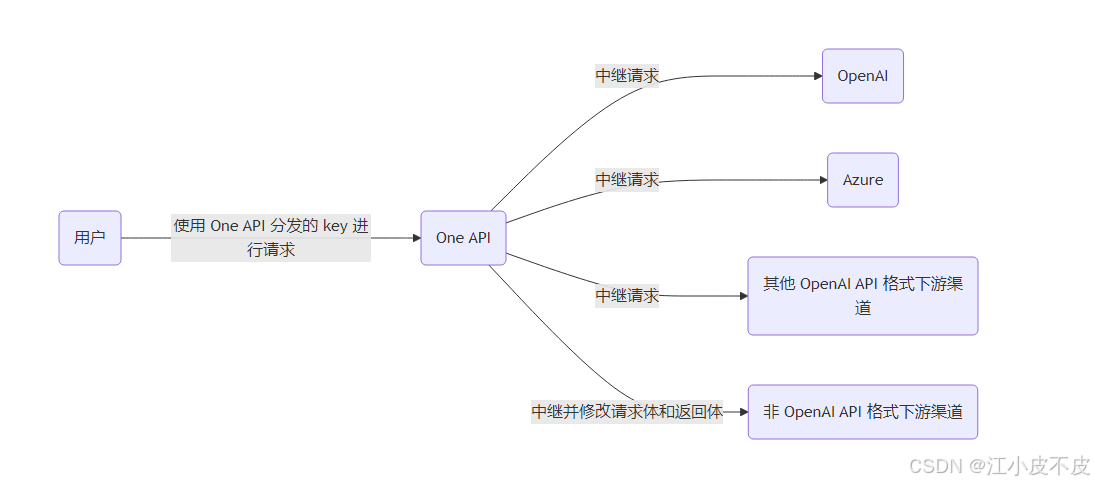
部署
1. 启动镜像
#拉取镜像
docker pull justsong/one-api:latest
#启动镜像
docker run --name one-api -d --restart always -p 7000:3000 -e TZ=Asia/Shanghai -v /data/lmaoni/one_api:/data justsong/one-api
2. 登录
输入ip + 端口进行登录,如:http://0.0.0.0:7000/login
初始账号密码是 root 123456
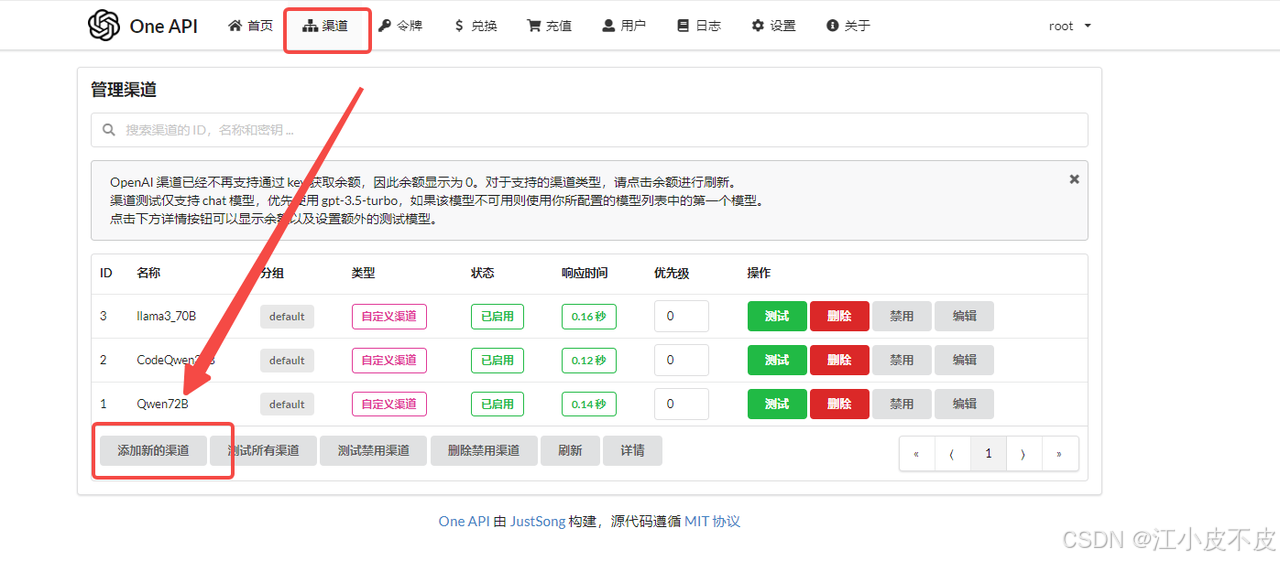
3. 添加API
登录完成后,点击渠道,进行添加新的渠道(API)
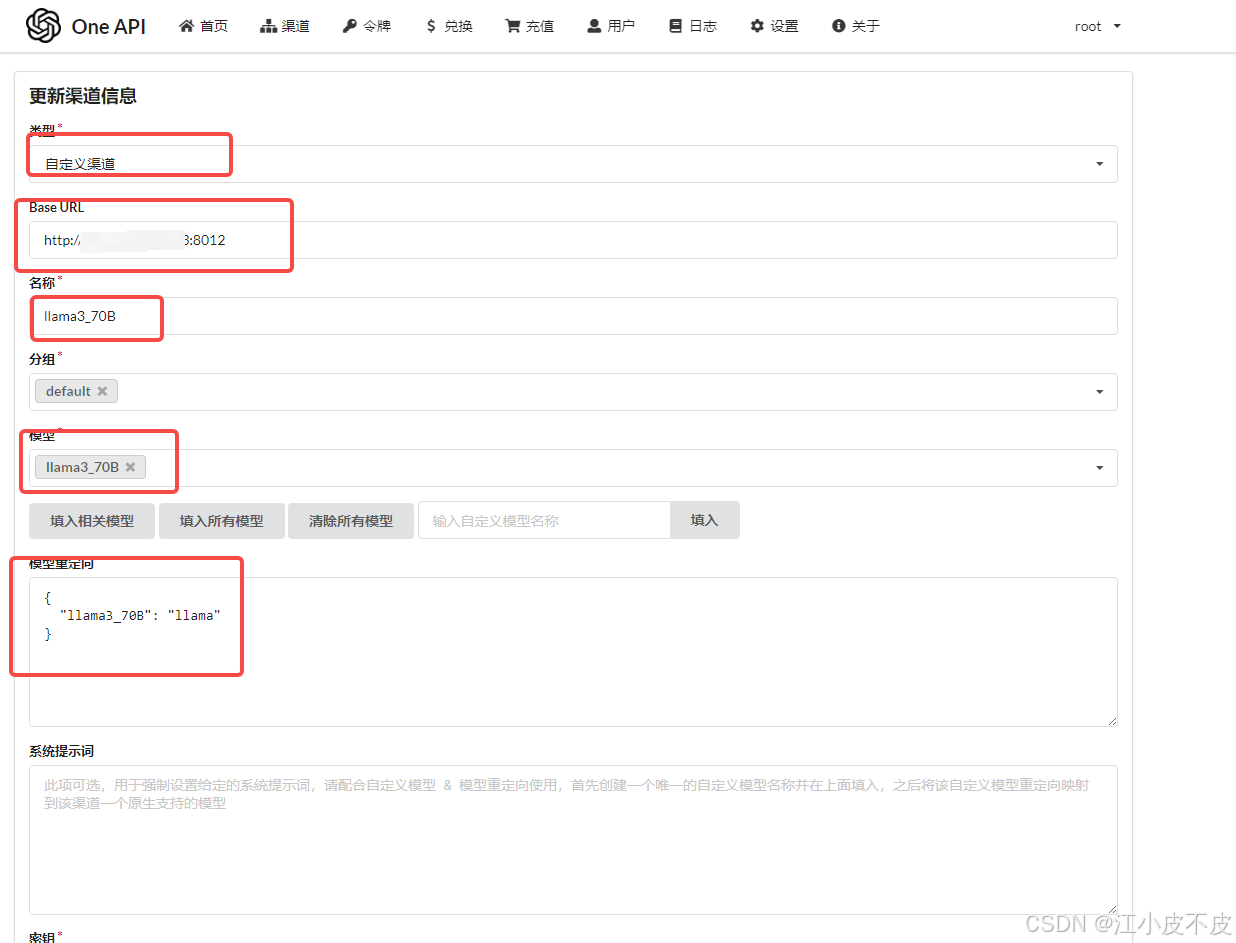
- 选择自定义渠道
- 输入 base_url(上文提到的用 vLLM 部署的)
- 输入名称(尽量和模型名保持一致)
- 输入自定义模型名称
- 自定义模型名称重定向到 vLLM 部署定义的模型名
- 填入密钥(如果 vLLM 启动的时候没有定义,就随便填一个 None)
- 点击提交完成
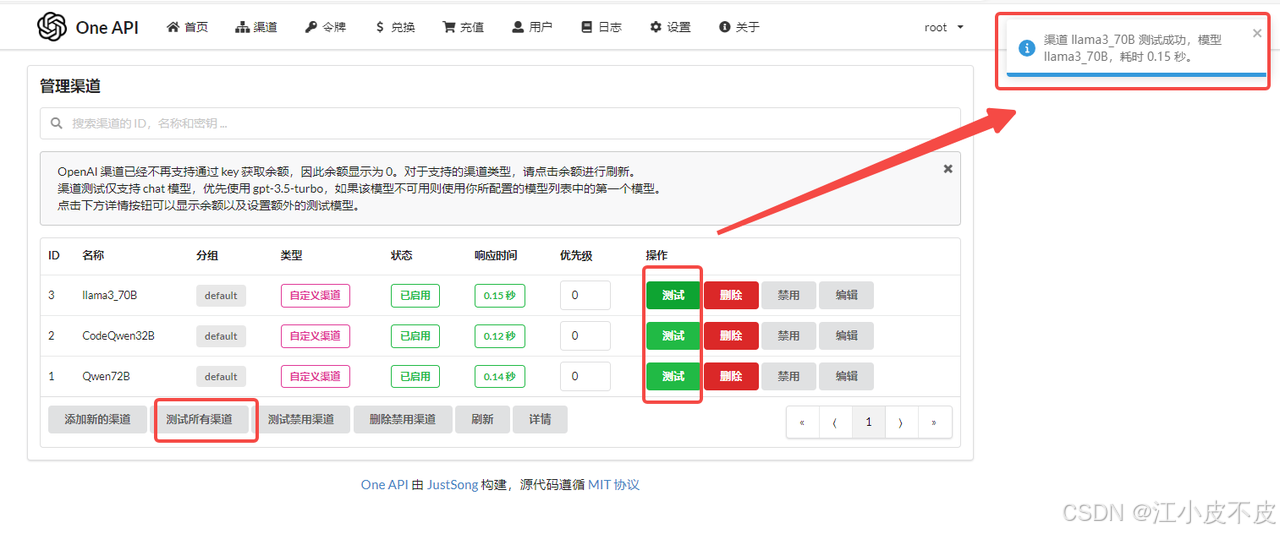
4. 测试渠道
如下图所示,我们已将 3 个模型添加进渠道。点击测试按钮或者下方的“测试所有渠道”,即可测试连通性。成功时右侧会有提示,失败时也会显示失败原因。
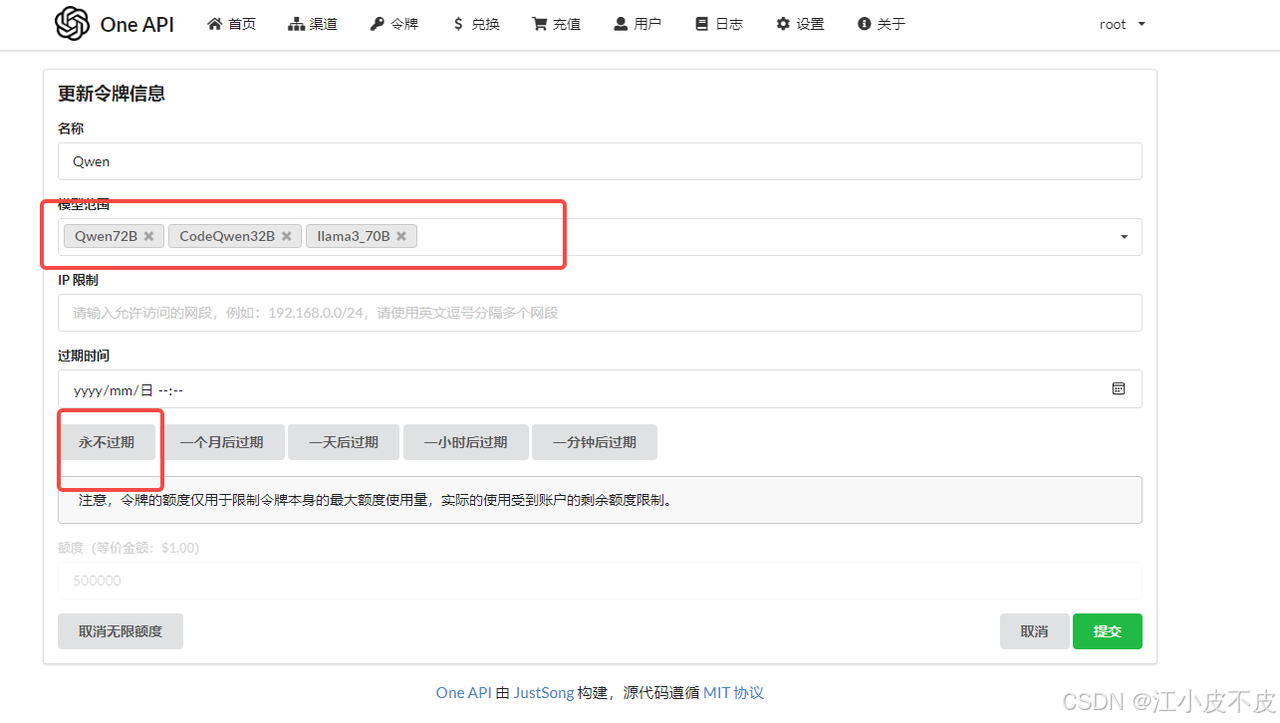
5. 添加令牌
- 点击令牌处,添加新的令牌。
- 输入模型名称(随意)
- 选择模型范围,这里选择了上一步中设置的3个渠道
- 设置过期时间
- 点击提交
- 点击复制即可得到API key
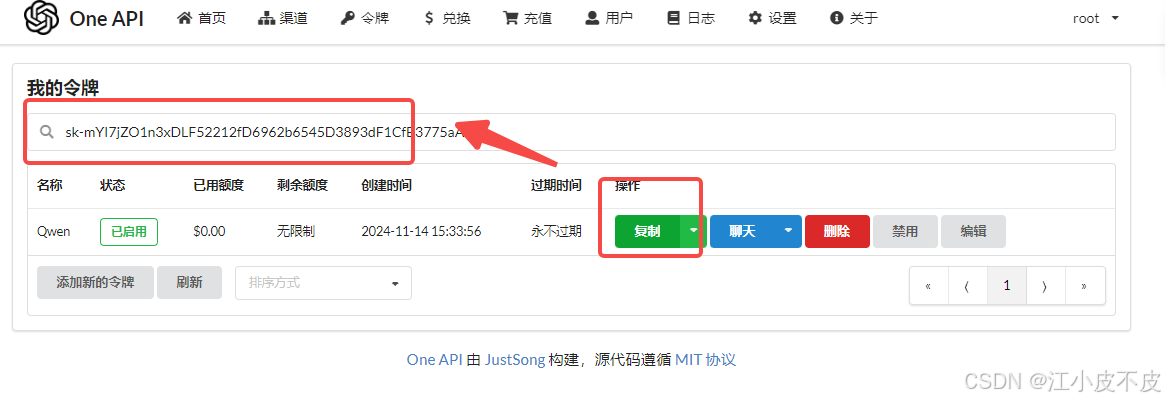
6. 使用服务
添加完成令牌后,上文中的三个模型已经统一成 OpenAI 的格式了。
- base_url =ip+ 端口 (第二步中的登录地址,如:http://0.0.0.0:7000/)
- OPENAI_API_KEY = “” (上一步中得到的令牌)
- model_name = “”(上一步中的模型范围中的模型)
ChatGPT-Next-Web
概述
ChatGPT Next Web(现称为 NextChat)是一个开源的聊天应用程序,旨在提供比传统 ChatGPT 更加灵活和可定制的用户体验。
主要特点
- 多模型支持:NextChat 能够访问多种语言模型,例如 OpenAI 的 GPT-4 和 GPT-3.5 以及 Google 的 Gemini-Pro。这样一来,用户能够依照需求选取不同的模型展开交互。
- 用户隐私:此应用程序会把所有数据在浏览器中进行本地存储,保证用户的敏感信息不会被传送到外部服务器或者第三方服务,加强了隐私保护。
- 自定义功能:用户能够通过提供上下文以及调整模型的超参数来定制聊天响应,满足诸如聊天机器人、内容生成以及代码生成等不同应用场景的需求。
- 轻量级设计:NextChat 客户端大概为 5MB,适用于 Linux、Windows 和 MacOS 等多个操作系统,便于用户迅速下载和安装。
- Markdown 支持:该应用支持 Markdown 格式,让用户能够创建在视觉上具有吸引力的消息内容。
- 响应式设计与暗模式:NextChat 提供响应式设计,适应不同的屏幕尺寸,并且包含暗模式选项,以契合用户的偏好。
部署
1. 拉取镜像
docker pull yidadaa/chatgpt-next-web
2. 启动镜像
docker run -itd -p 8011:3000 -e BASE_URL=http://X.X.X.X:7000/ -e OPENAI_API_KEY=sk-mYI7jZO1n3xDLF52212fD6962b6545D3893dF1CfB3775aA6 -e CUSTOM_MODELS='-all,+CodeQwen32B@OpenAI,Qwen72B@OpenAI,llama3_70B@OpenAI' --restart always --name chatgpt-next-web yidadaa/chatgpt-next-web:latest
参数解释:
- BASE_URL:上文通过 OneAPI 部署的服务地址
- OPENAI_API_KEY:上文通过 OneAPI 部署的令牌
- CUSTOM_MODELS:
- -all表示去掉内置的所有模型(如 gpt4o 等,太多了,建议去掉)
- +CodeQwen32B@OpenAI :表示模型名称和遵守 OpenAI 格式(上文通过 OneAPI 部署的渠道)
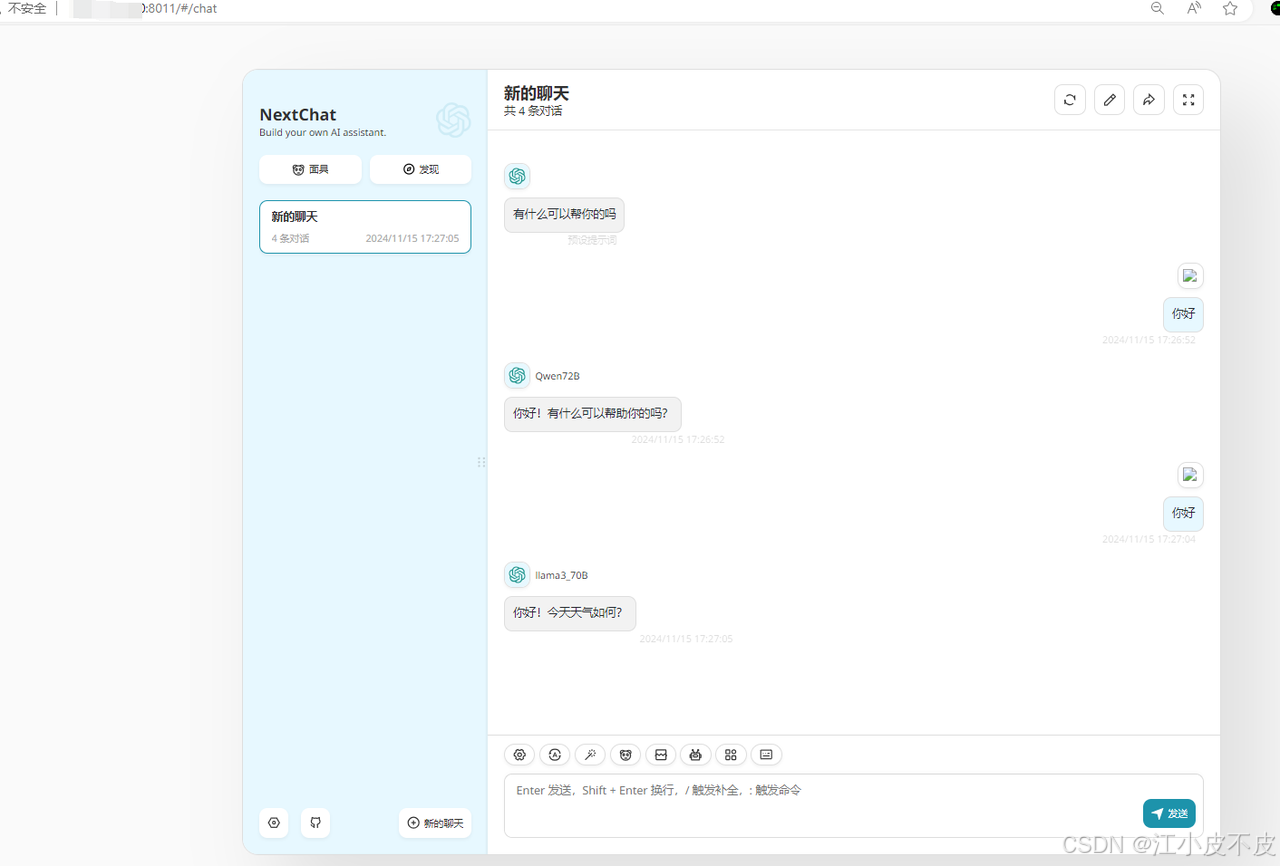
3. 使用服务
访问IP+端口 即可打开Chat界面,如:http://X.X.X.X:8011/


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











