






LLM推进网络安全漏洞评估ChatNVD
LLM推进网络安全漏洞评估ChatNVD
概述
本研究提出了基于大语言模型 (LLMs) 的网络安全漏洞评估工具 ChatNVD,通过整合 NVD 数据库与先进的模型嵌入技术,为安全从业者提供了一种高效且可操作的解决方案。实验结果表明,GPT-4o mini 在处理漏洞信息查询任务时表现最佳,准确率达到 1.0。研究同时指出了模型在长上下文处理、成本控制和幻觉问题方面的挑战,并为未来的模型优化和改进提供了方向。
1. 论文地址
题目:ChatNVD: Advancing Cybersecurity Vulnerability Assessment with Large Language Models
作者:澳大利亚阿德莱德大学
发表日期:2024 年 12 月 6 日
论文链接:https://arxiv.org/html/2412.04756?_immersive_translate_auto_translate=1
项目地址:https://github.com/Shivansh1313/ChatNVD-Research
2. 背景与目的
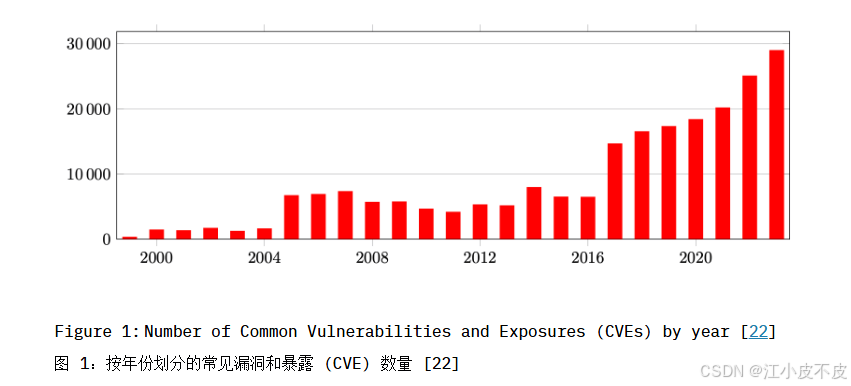
大语言模型的广泛应用
大语言模型(LLMs)作为生成式人工智能的子集,通过实现高级内容生成和流程自动化,在众多领域引发了变革:
- 教育领域:生成问题、批改论文、提供个性化反馈。
- 娱乐行业:创作视频游戏叙事和音乐字幕。
- 商业运营:优化营销活动、客户服务和供应链流程。
- 医疗保健:提供实时决策支持,预测疾病进展。
网络安全漏洞的严峻形势
- 过去十年,已识别的漏洞数量增长了四倍。
- 全球网络攻击被世界经济论坛列为风险前五。
- 挑战:现有漏洞评估方法过于技术化、耗时且易出错,无法快速应对漏洞的增长。
LLMs 在网络安全领域的应用
- 威胁检测与响应:分析日志和网络流量,识别异常模式。
- 漏洞管理:解析 NVD 数据库,加速漏洞分类和修复。
- 威胁识别与渗透测试:结合 GPT-4 等工具进行系统安全检查。
- 智能防御系统与防火墙:实时检测高级持续威胁(APTs)。
- 简化安全协议:自动化网络漏洞检测,提升效率并减少人为错误。
研究目的
探索 LLMs 在软件漏洞评估中的潜力,提出 ChatNVD 工具,结合 NVD 数据为安全专业人员提供有效的漏洞评估解决方案。
3. ChatNVD 的开发过程
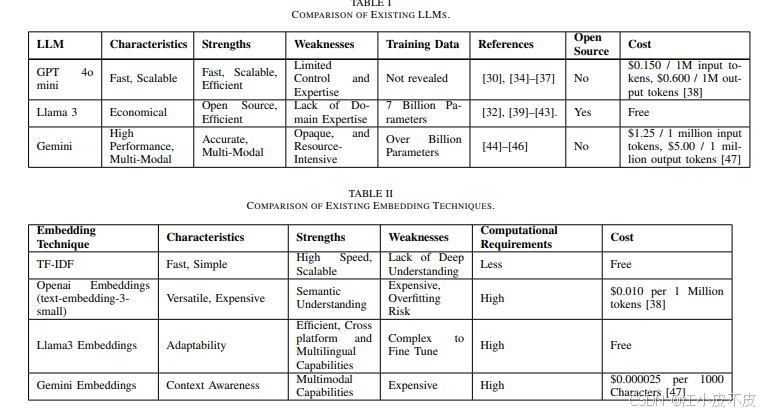
模型与嵌入技术选择
-
LLMs 选择:
- GPT-4o mini:性能优良,支持多模态输入。
- Llama 3:开源且可灵活微调。
- Gemini 1.5 Pro:专注安全任务,具备高性能。
-
嵌入技术选择:
- TF-IDF:简单高效,适合处理大规模数据集。
- 高级嵌入模型:如 OpenAI、Llama 和 Gemini,因成本限制主要采用 TF-IDF。
TF-IDF
- 定义:评估单词的重要性。
- 特点:计算简单、可解释性强。
- 优缺点:计算高效,但无法捕捉语义或上下文。
嵌入模型
- 定义:文本映射到向量空间,捕捉语义关系。
- 优缺点:具备深度语义理解,但计算成本高。
NVD 数据提取与预处理
- 数据来源:2002-2024 年的 NVD 数据,约 1.29GB。
- 处理结果:缩减至 720.7MB,提高了数据质量,降低计算成本。
评估过程
- 测试集:125 个问题,涵盖漏洞的发布日期、描述、可利用性评分等。
- 方法:
- 随机选择 CVEs 生成问题。
- 输入至 LLMs,输出与预期答案对比,评估准确性。
API 开发与用户界面集成
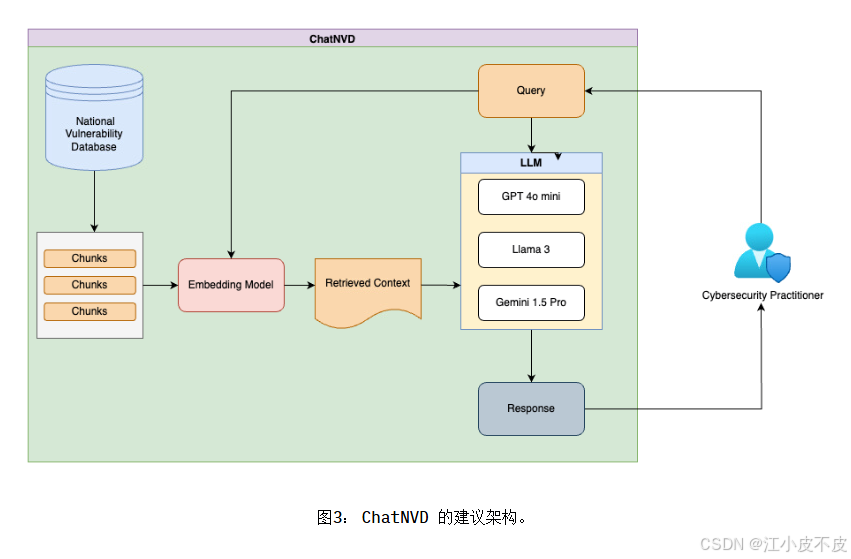
- API:使用 FastAPI,部署于 AWS EC2 实例(t2.medium)。
- 前端:采用 React 构建用户界面。
- 示例模板:
prompt_template = """
{internallinenumbers*}
You are an assistant that helps with CVE data. Only use the context provided. Respond with CVE details, recommend this website, and attach the CVE ID in front of it https://nvd.nist.gov/vuln/detail/ \n
Context:\n {context}\n
Question: \n{question}?\n
Answer:
"""
prompt_template = """
{内部行号*}
您是协助处理 CVE 数据的助手。请仅使用提供的上下文。回复 CVE 详细信息,推荐此网站,并在其前面附上 CVE ID https://nvd.nist.gov/vuln/detail/ \n
上下文:\n {上下文}\n
问题:\n{问题}?\n
回答:
"""
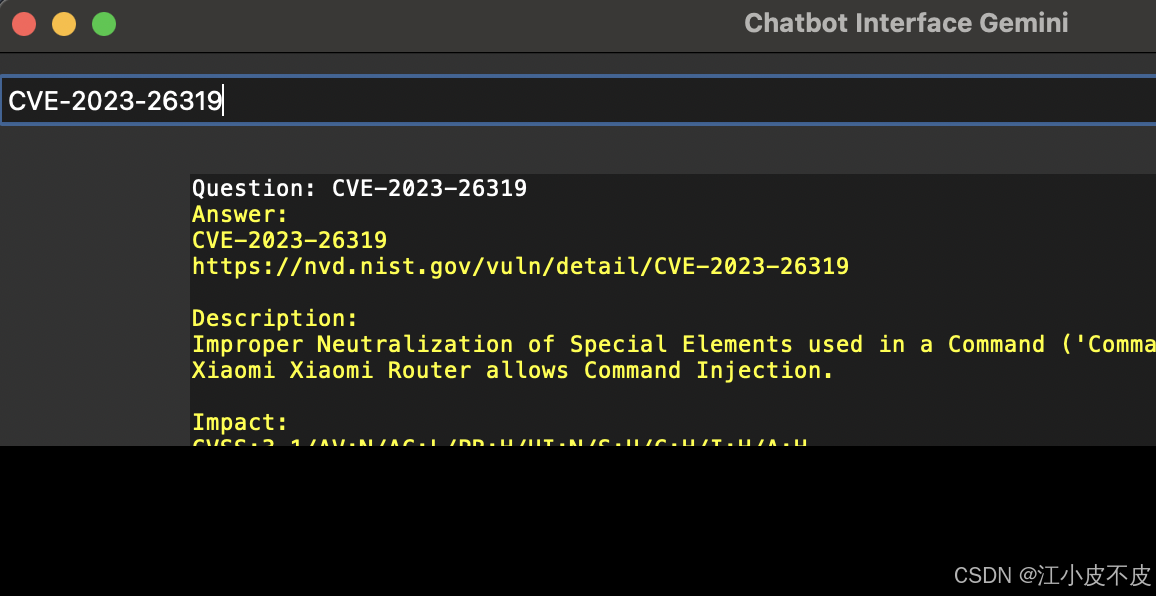
4. 实验评估结果与分析
实验设置
- 环境:Python 3.12.2,MacBook Pro(M3 Pro,18GB 内存)。
评估结果
示例问题:
- CVE-2016-9733 的发布日期是什么时候?
- CVE-2016-9733的描述是什么?
- CVE-2016-9733 的可利用性评分是多少?
- CVE-2016-9733的影响分数是多少?
- CVE-2016-9733 的基本分数是多少?
- CVE-2016-9733 的发布日期是什么?
{ "question": "What is the published date of CVE-2016-9733", "expected_answer": "2017-07-05T17:29Z", "actual_answer": "The published date of CVE-2016-9733 is 2017-07-05T17:29Z..." }
准确率对比
- GPT-4o mini:准确率 1.0
- Gemini 1.5 Pro:准确率 0.84
- Llama 3:准确率 0.86
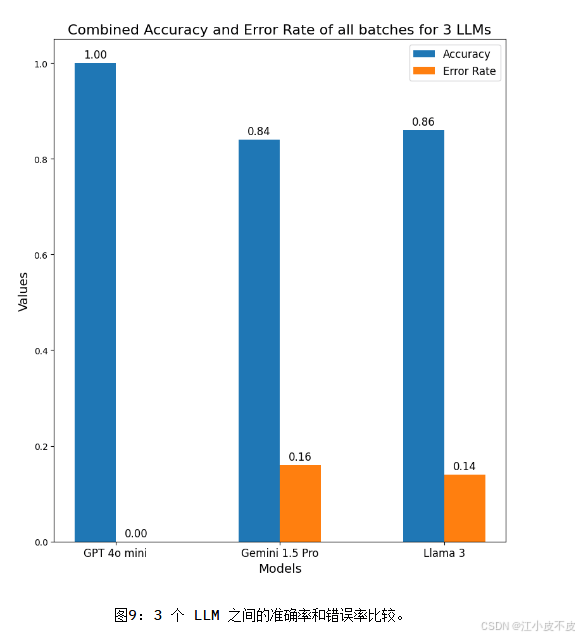
模型表现分析
- GPT-4o mini:表现最佳,尤其在大上下文窗口问题中优势显著。
- Llama 3:上下文处理能力有限,部分回答出现幻觉。
- Gemini 1.5 Pro:描述类问题表现不稳定。
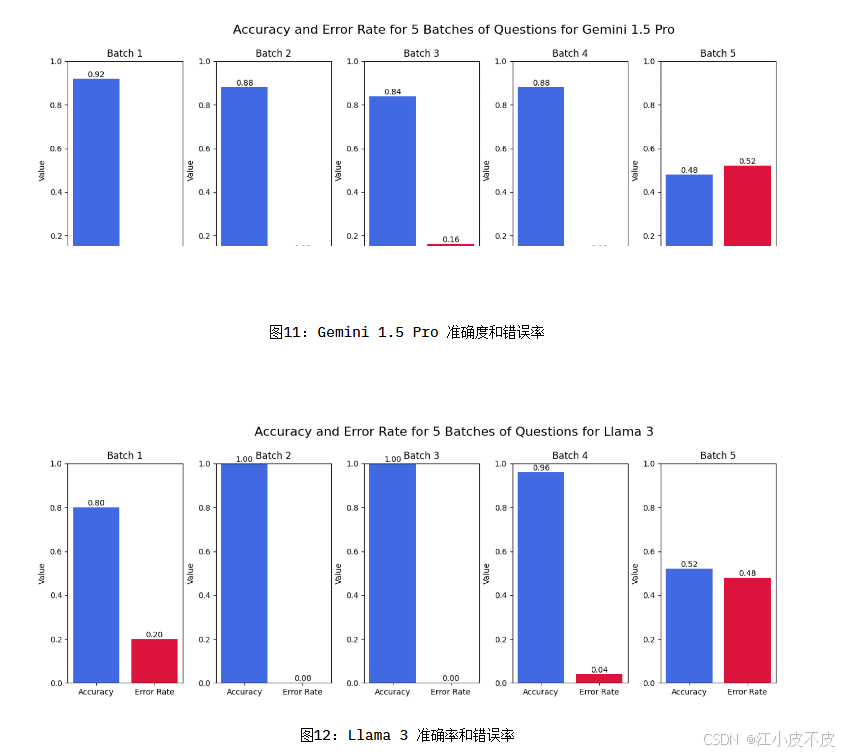
5. 研究的局限性与挑战
1. 有效性威胁
- 幻觉问题:模型可能生成不准确的回答。
- 令牌限制:长对话易丢失上下文。
- 成本问题:LLM 运营成本高,需探索优化方案。
2. 模型改进需求
- GPT-4o mini 表现优秀,但仍有改进空间。
- 需要优化模型架构,确保在多场景下表现稳定。
数据格式示例
{
"cve" : {
"data_type" : "CVE",
"data_format" : "MITRE",
"data_version" : "4.0",
"CVE_data_meta" : {"ID" : "CVE-2023-0017", "ASSIGNER" : "cna@sap.com"},
"description" : {
"description_data" : [{"lang" : "en", "value" : "An unauthenticated attacker in SAP..."}]
},
"impact" : {
"baseMetricV3" : {
"cvssV3" : {
"version" : "3.1",
"baseScore" : 9.8,
"baseSeverity" : "CRITICAL"
}
}
}
}
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











