







如何在自定义数据集上训练YOLOv11目标检测模型
一、YOLOv11简介
YOLOv11是YOLO(You Only Look Once)系列目标检测算法的最新演进版本,由国内研究团队于2023年提出。Yolo11CustomObjectDetection作为单阶段目标检测器的代表,YOLOv11在保持实时检测速度的同时,进一步提升了检测精度,特别优化了小目标检测能力。
YOLOv11的核心改进
- 更高效的骨干网络:采用改进的CSPNet结构,增强特征提取能力
- 自适应特征融合:动态调整不同尺度特征的融合权重
- 更精确的锚框设计:基于数据统计自动优化锚框尺寸
- 训练策略优化:引入更先进的损失函数和数据增强方法
二、准备工作
1. 硬件要求
- GPU:推荐NVIDIA RTX 3060及以上(8GB显存)
- CPU:4核以上
- 内存:16GB以上
- 存储空间:至少50GB可用空间
2. 软件环境配置
# 创建Python虚拟环境
python -m venv yolov11_env
source yolov11_env/bin/activate # Linux/Mac
# yolov11_env\Scripts\activate # Windows
# 安装基础依赖
pip install torch==1.12.0+cu113 torchvision==0.13.0+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
pip install opencv-python matplotlib tqdm pandas seaborn
# 克隆YOLOv11官方仓库
git clone https://github.com/WongKinYiu/yolov11.git
cd yolov11
pip install -r requirements.txt
3. 数据集准备
自定义数据集需要按以下结构组织:
custom_dataset/
├── images/
│ ├── train/
│ │ ├── image1.jpg
│ │ └── ...
│ └── val/
│ ├── image2.jpg
│ └── ...
└── labels/
├── train/
│ ├── image1.txt
│ └── ...
└── val/
├── image2.txt
└── ...
标注文件格式(YOLO格式):
<class_id> <x_center> <y_center> <width> <height>
其中坐标值为相对于图像宽高的归一化值(0-1)
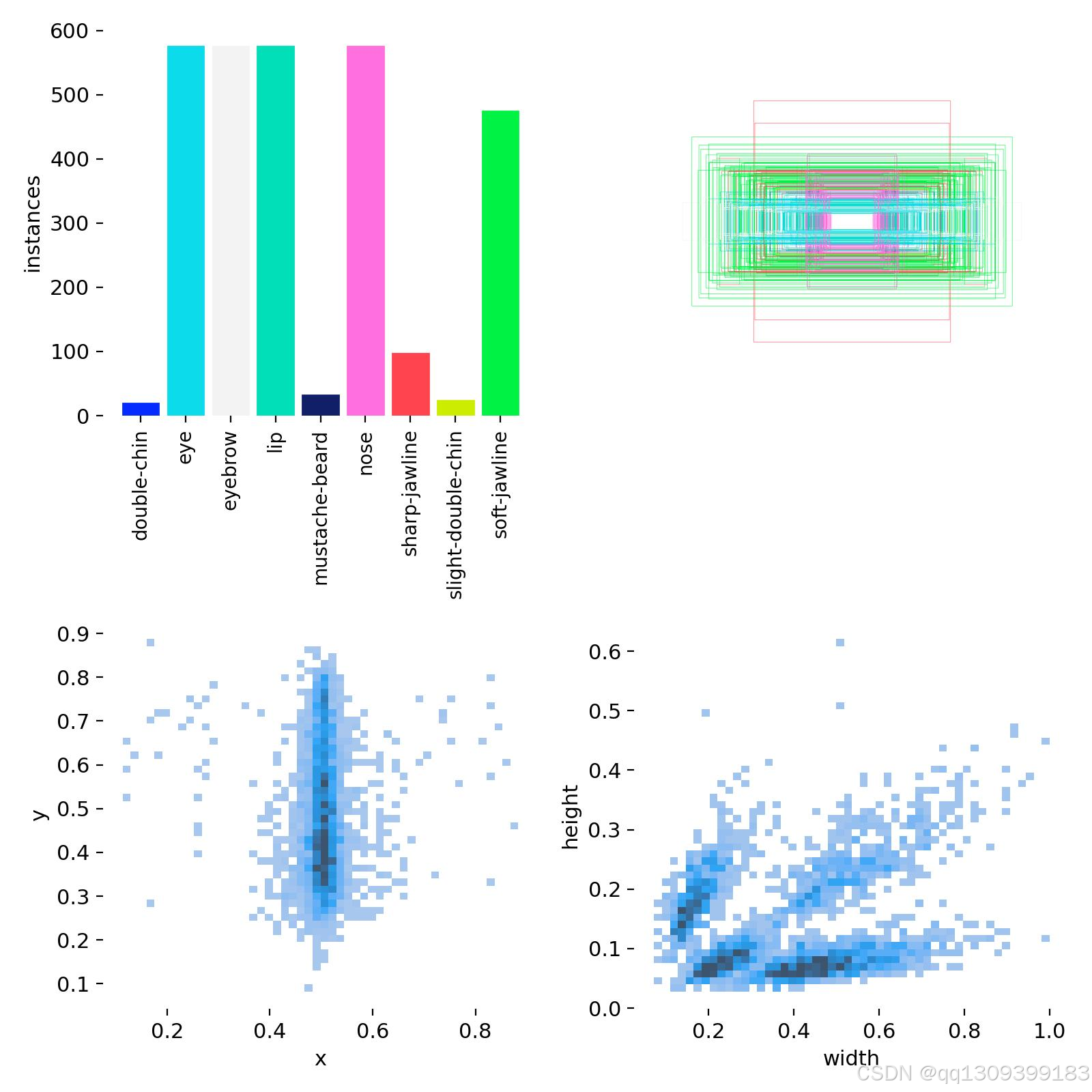
三、训练流程详解
1. 数据配置文件
创建data/custom.yaml:
# 训练和验证图像路径
train: ../custom_dataset/images/train
val: ../custom_dataset/images/val
# 类别数量
nc: 3 # 根据你的数据集调整
# 类别名称
names: ['person', 'car', 'dog'] # 替换为你的类别
2. 模型配置文件
选择预定义配置(如models/yolov11s.yaml)或自定义网络结构

3. 开始训练
python train.py --img 640 --batch 16 --epochs 100 --data data/custom.yaml --cfg models/yolov11s.yaml --weights '' --name yolov11s_custom
关键参数说明:
--img 640: 输入图像尺寸--batch 16: 批次大小(根据GPU显存调整)--epochs 100: 训练轮次--weights '': 从头开始训练(使用预训练权重可改为’yolov11s.pt’)
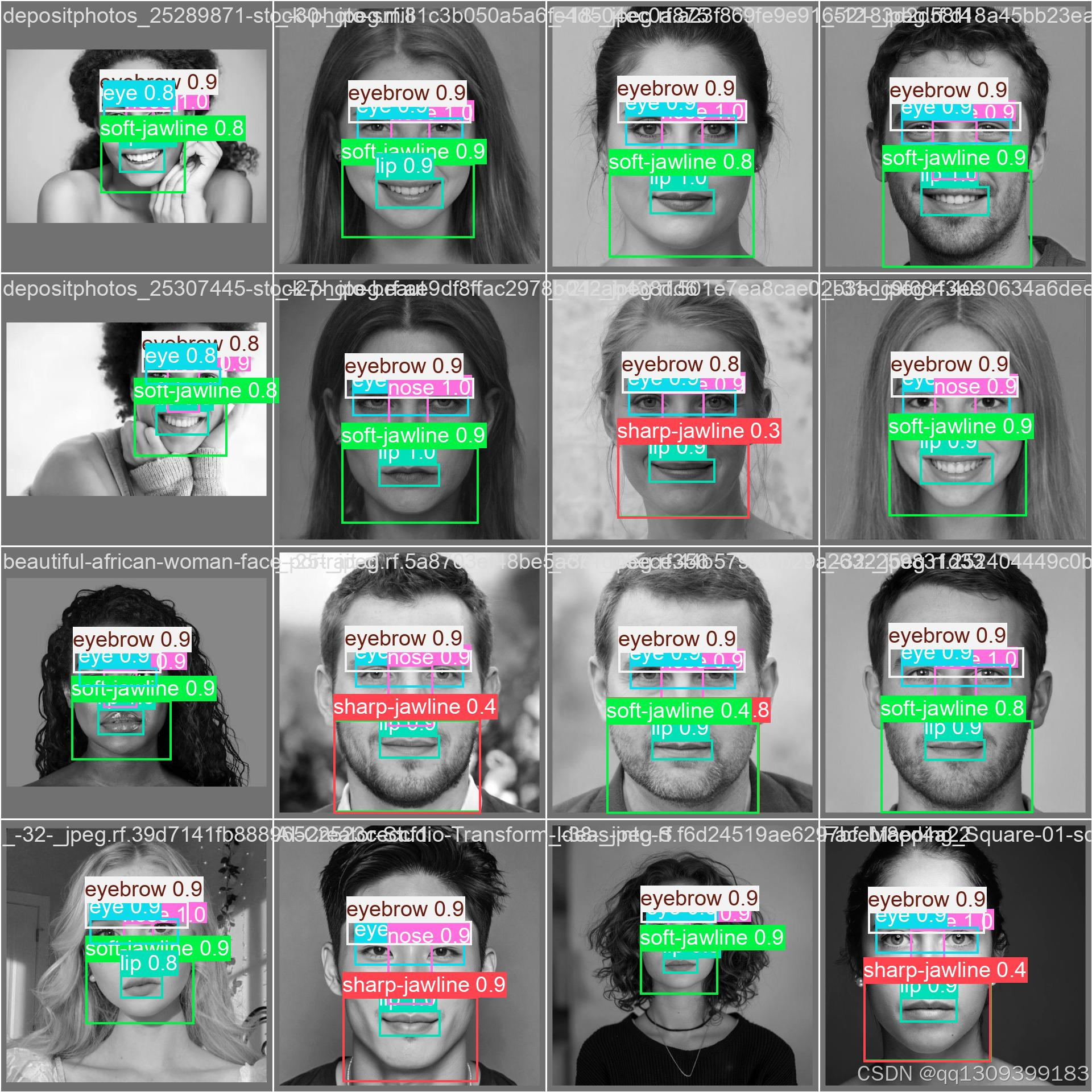
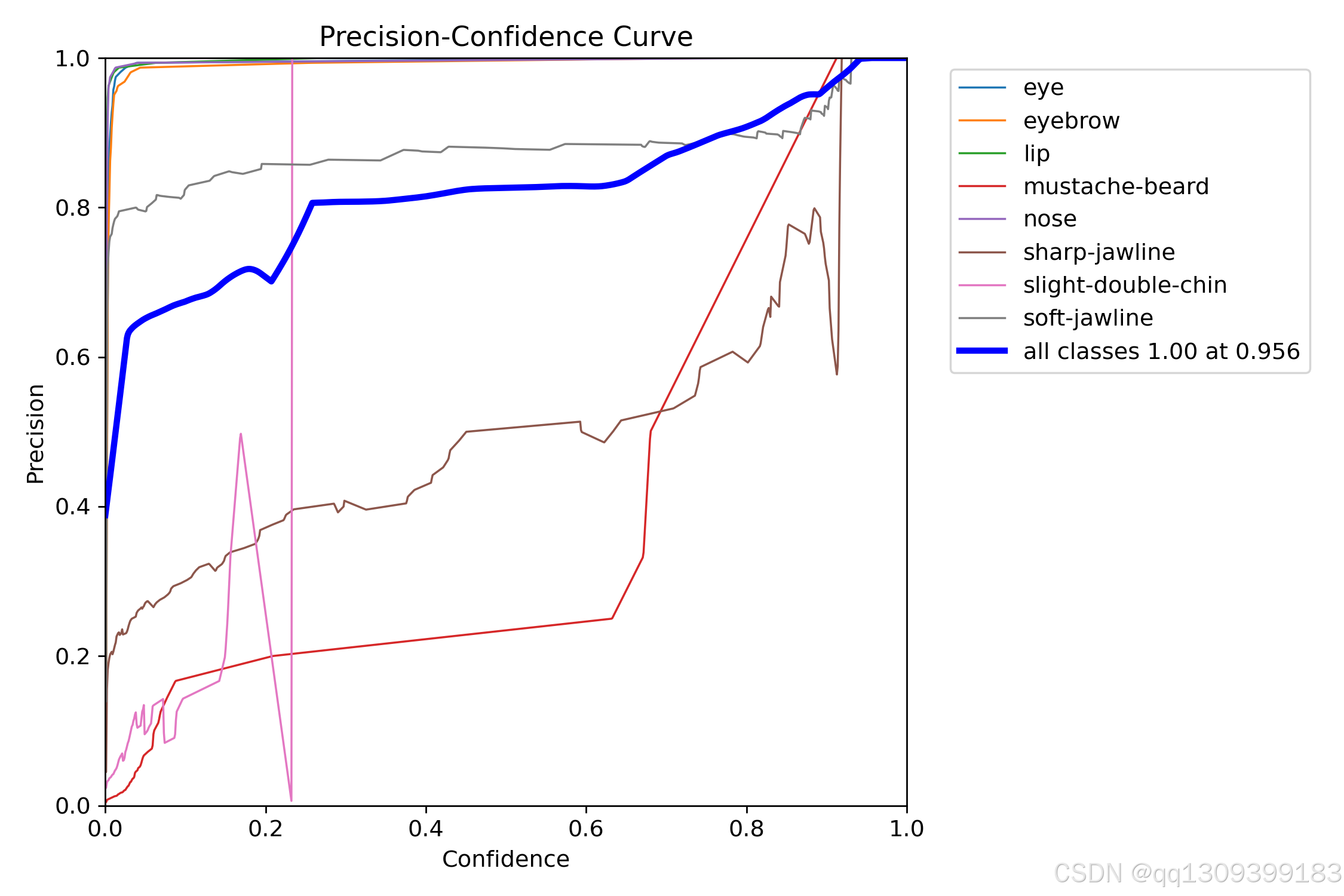
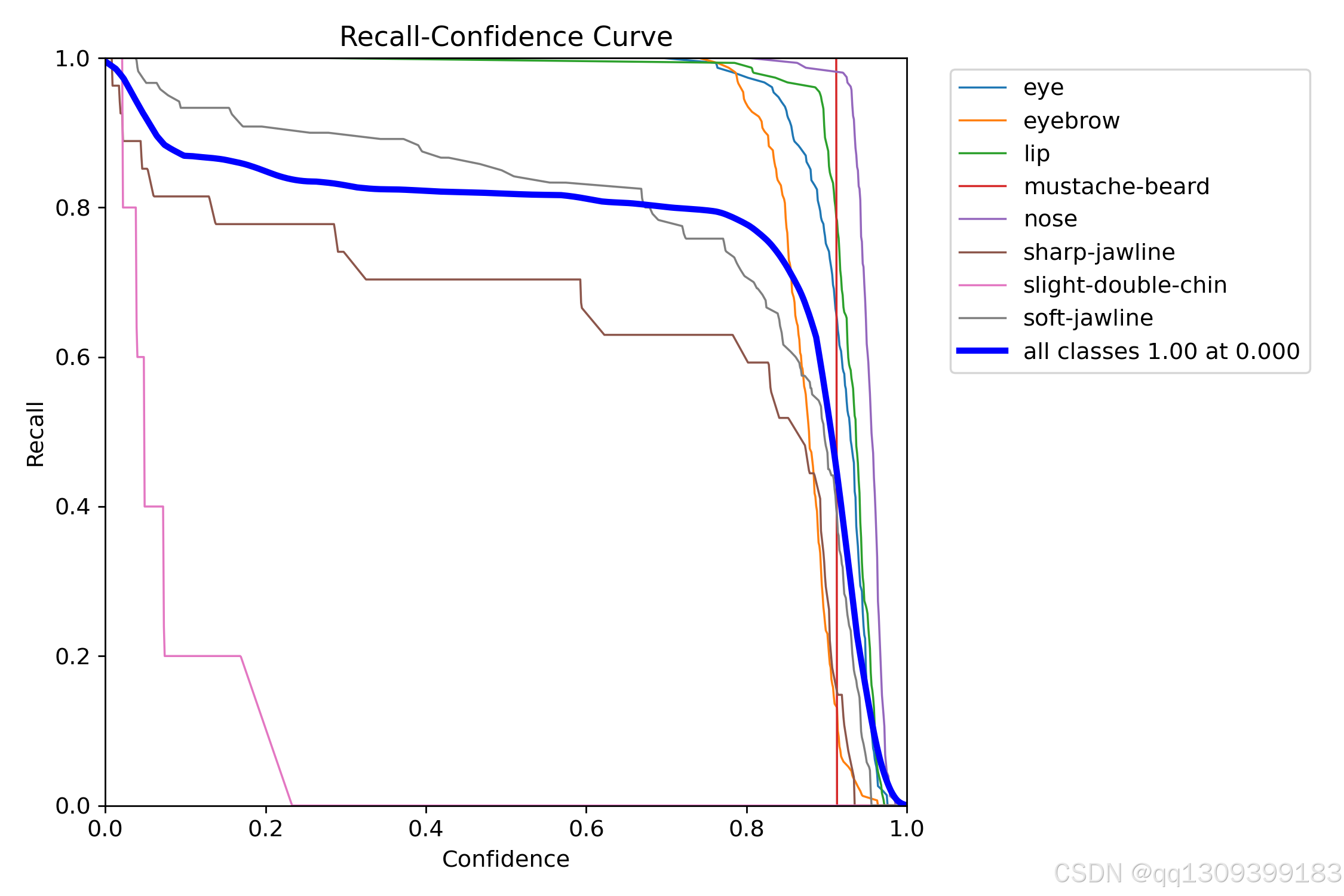
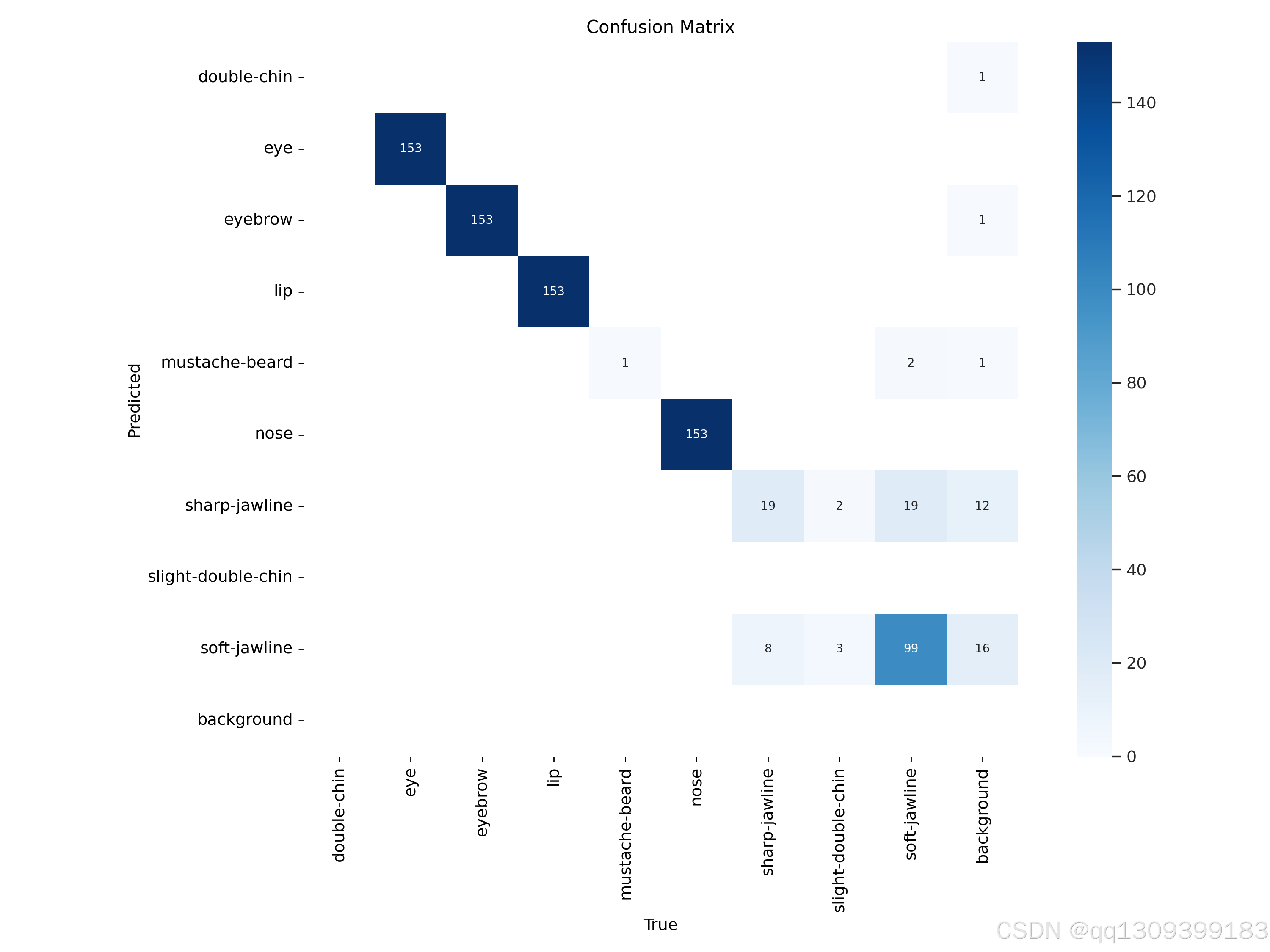
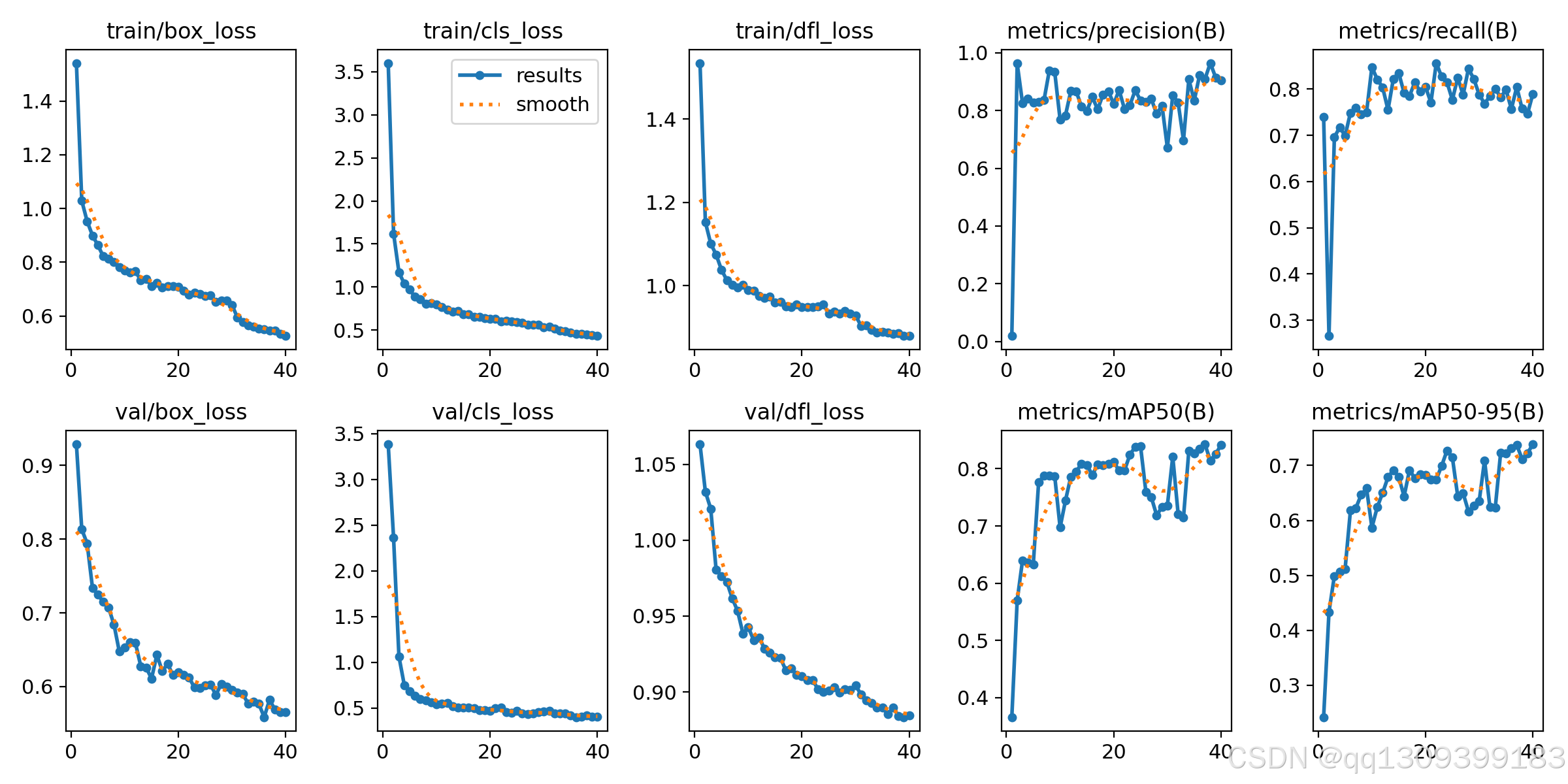
4. 训练过程监控
YOLOv11会自动记录以下信息:
- 损失函数变化
- 精度指标(mAP@0.5)
- 验证集结果示例
使用TensorBoard查看训练过程:
tensorboard --logdir runs/train

四、高级训练技巧
1. 数据增强策略
在data/hyps/hyp.scratch.yaml中调整:
# 色彩空间增强
hsv_h: 0.015 # 色调增强幅度
hsv_s: 0.7 # 饱和度增强幅度
hsv_v: 0.4 # 明度增强幅度
# 几何变换
degrees: 0.0 # 旋转角度范围
translate: 0.1 # 平移比例
scale: 0.5 # 缩放比例
shear: 0.0 # 剪切强度
# 马赛克增强
mosaic: 1.0 # 使用马赛克增强的概率
mixup: 0.0 # MixUp增强概率
2. 迁移学习
使用预训练权重加速收敛:
python train.py ... --weights yolov11s.pt
3. 多尺度训练
添加--multi-scale参数,随机选择图像尺寸(±50%)
4. 自动锚框优化
训练前运行:
python train.py --data custom.yaml --cfg yolov11s.yaml --weights '' --anchors
五、模型评估与测试
1. 评估模型性能
python val.py --data data/custom.yaml --weights runs/train/yolov11s_custom/weights/best.pt --img 640
2. 测试单张图像
python detect.py --source test.jpg --weights runs/train/yolov11s_custom/weights/best.pt
3. 导出为ONNX格式
python export.py --weights runs/train/yolov11s_custom/weights/best.pt --include onnx
六、常见问题解决
-
CUDA内存不足:
- 减小
--batch-size - 降低
--img-size - 添加
--gradient-accumulation-steps 2
- 减小
-
训练损失不下降:
- 检查标注是否正确
- 尝试更小的学习率(
--lr 0.001) - 使用预训练权重
-
验证mAP低但训练损失低:
- 减少数据增强强度
- 增加训练数据量
- 检查训练/验证集分布是否一致
-
小目标检测效果差:
- 使用更高分辨率的输入(
--img 1280) - 采用专门的小目标检测模型配置
- 使用更高分辨率的输入(
七、实际应用建议
-
模型轻量化:
- 尝试YOLOv11的tiny或nano版本
- 使用模型剪枝/量化技术
-
部署优化:
- 转换为TensorRT格式加速推理
- 使用OpenVINO优化Intel平台性能
-
持续改进:
- 定期补充困难样本
- 使用主动学习策略筛选有价值样本
通过本指南,您应该能够成功在自定义数据集上训练YOLOv11模型。根据具体应用场景调整参数和策略,持续优化模型性能。YOLOv11的灵活性和高效性使其成为工业级目标检测应用的优秀选择。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









