






括号区间匹配
给定一个由 ‘[’ ,‘]’,‘(’,‘)’ 组成的字符串,请问最少插入多少个括号就能使这个字符串的所有括号左右配对。
例如当前串是 “([[])”,那么插入一个’]‘即可满足。
数据范围:字符串长度满足 1≤n≤100
输入描述:
仅一行,输入一个字符串,字符串仅由 ‘[’ ,’]’ ,‘(’ ,‘)’ 组成
输出描述:
输出最少插入多少个括号
示例:
输入:([[])
输出:1
输入:([])[]
输出:0
这道题是一个区间dp问题,我看了各种c++代码,最后理解还是靠自己画方格图一点一点通过网上的代码倒推理解的。先上正确代码:
import java.util.*;
public class Main{
public static int process(String str){
char[]ch=str.toCharArray();
int n=ch.length;
int[][]dp=new int[n][n];
//最大值填充
// for(int i=0;i<n;i++)
// Arrays.fill(dp[i],Integer.MAX_VALUE);
//对角线填充,因为一个括号只需要另1个括号就能匹配
for(int i=0;i<n;i++){
dp[i][i]=1;
}
for(int i=1;i<n;i++){//i表示以j为左边界,向右移动的距离。
for(int j=0;j+i<n;j++){
dp[j][j+i]=Integer.MAX_VALUE;
if((ch[j]=='('&&ch[j+i]==')')||(ch[j]=='['&&ch[j+i]==']'))
dp[j][j+i]=Math.min(dp[j][j+i],dp[j+1][j+i-1]);
for(int k=j;k<j+i;k++){
dp[j][j+i]=Math.min(dp[j][j+i],dp[j][k]+dp[k+1][i+j]);
}
}
}
return dp[0][n-1];
}
public static void main(String[]args){
Scanner sc=new Scanner(System.in);
String str=sc.next();
System.out.print(process(str));
}
}
这里逐行解释:
dp的两个维度分别表示在字符串ch的当前左下标和右下标上的最少填充数,比如dp[3][6]表示的是在ch的第三个下标到第六个下标内的最少填充,这里为了方便举例:
输入 ( [ ) [ ) ( ]
这里n=7;
因为对于单个括号,只需要另一个就可以了,所以代码第13行:

再看网上代码: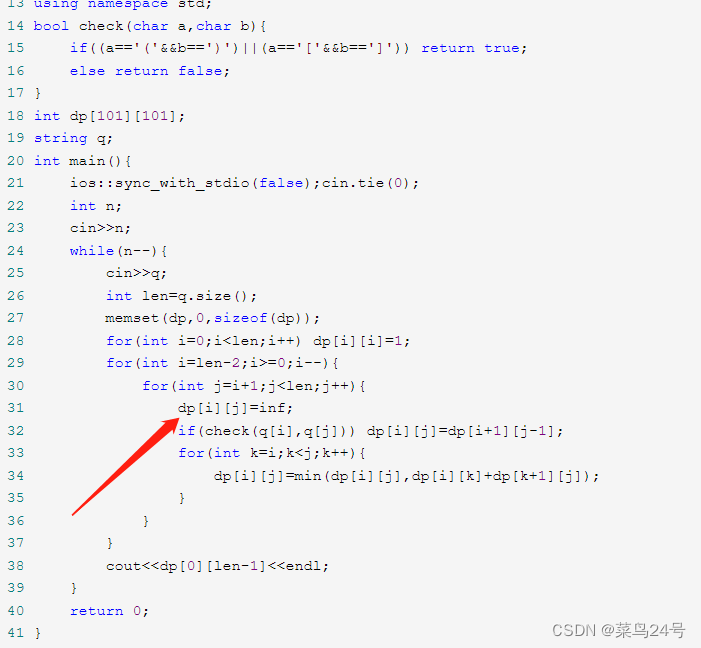
我就想为什么不能提前把所有dp初始化为Integer.MAX_VALUE呢,因为如果提前处理了,假如输入的字符串本来就不需要额外的括号就已经很完美了呢,就没办法返回0了。
再说到我写的java代码,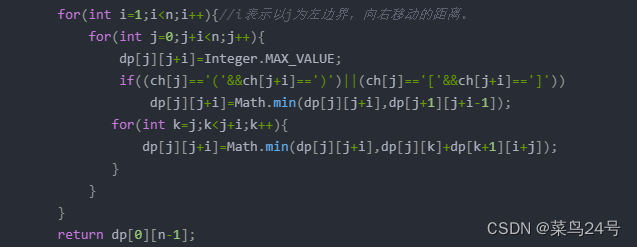
最开始我一直没看明白别人c++代码里的两个for,后来我才理解了,第一个for的意思是表示以j为左边界向右框起来的字符串得距离。j表示left,i+j就表示right,对于每一个位置的dp最初值为MAX,由于每次循环都不会改变之前已经确定了的dp值,为什么不会改变呢,因为第2个for(int j=0;j+i<n;j++)每次只确定dp[j][j+i]的值,不会改变其他值。
再说i为什么从1开始,因为在第一步赋初值时对角线已经填满1了,i从0开始,相当于dp[j][j+i]每次多算一次对角线,没必要。
第二个for循环for(int j=0;j+i<n;j++)的意思刚开始看其他人的代码我也卡壳很久。其实这里的意思是最右边界right不能超过n,left从j开始。
if((ch[j]=='('&&ch[j+i]==')')||(ch[j]=='['&&ch[j+i]==']'))
dp[j][j+i]=Math.min(dp[j][j+i],dp[j+1][j+i-1]);
这个好理解,就是说在区间 j~j+i 内如果左右边界符合条件,那么最小填充值就等于 j+1~j+i-1 范围内的最小填充值。
接下来为什么要枚举遍历呢,就是for(int k···)
因为最小值答案可能来自以在j到j+i范围内以k为分界点的两个部分的和。为什么呢,举例子:
(())【【】】
这个串中答案为0,但是不同的两部分得到的答案不同,比如0-3位置加4-7位置答案为0,但是0-0位置加1-7位置答案=1+1=2.
最后通过画方块看过程就稍微容易理解些了。
举例:( [ ) [ ) ( ]
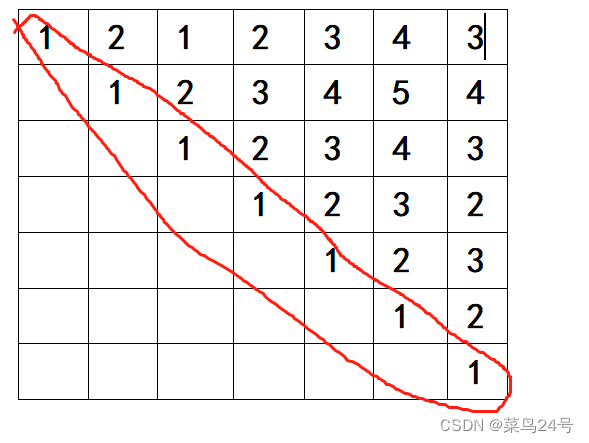
第一步初始化,图中没有数据的为0.
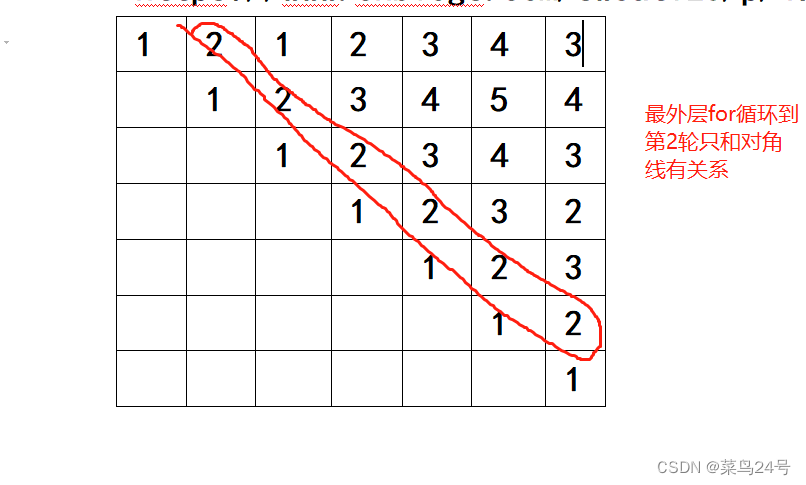
第四轮for循环之和之前产生的对角线有关系。
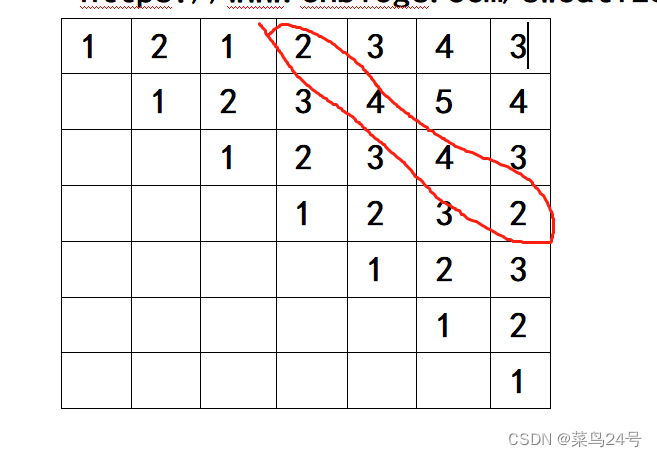
最后返回dp[0][n-1]=3表示在整个字符串范围内最小答案。
这道题直接dp不好理解还可以用左程云左神的记忆化搜索的方法,可能好理解些。我也是请教了左神看了他的代码然后慢慢理解的。
package class_2022_08_5_week;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String line;
while ((line = br.readLine()) != null) {
System.out.println(minAdd(line.toCharArray()));
}
}
public static int minAdd(char[] s) {
int n = s.length;
int[][] dp = new int[n][n];
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
dp[i][j] = -1;
}
}
return process(s, 0, s.length - 1, dp);
}
// 让s[l...r]都完美匹配
// 至少需要加几个字符
public static int process(char[] s, int l, int r, int[][] dp) {
// 只有一个字符,不管是什么,要想配对,都需要添加一个字符
if (l == r) {
return 1;
}
// 只有两个字符,
// 如果是()、[],那什么也不需要添加
// 否则,都需要添加2个字符
if (l == r - 1) {
if ((s[l] == '(' && s[r] == ')') || (s[l] == '[' && s[r] == ']')) {
return 0;
}
return 2;
}
if (dp[l][r] != -1) {
return dp[l][r];
}
// 重点是如下的过程
// 可能性1,先搞定l+1...r,然后搞定l
// 比如s[l...r] = ([][]
// 先搞定[][],需要添加0个,然后搞定(,需要添加1个
// 整体变成([][])搞定
int p1 = 1 + process(s, l + 1, r, dp);
// 可能性2,先搞定l...r-1,然后搞定r
// 和可能性1同理
int p2 = 1 + process(s, l, r - 1, dp);
// 可能性3,s[l]和s[r]天然匹配,需要搞定的就是l+1..r-1
// 比如([[),搞定中间的[[,就是最优解了
int p3 = Integer.MAX_VALUE;
if ((s[l] == '(' && s[r] == ')') || (s[l] == '[' && s[r] == ']')) {
p3 = process(s, l + 1, r - 1, dp);
}
// 可能性后续:可能,最优解并不是l....r整体变成最大的嵌套
// 而是,并列关系!
// l....split 先变成合法
// split+1...r 再变成合法
// 是并列的关系!
// 比如(())[[]]
// l...split : (())
// split+1...r : [[]]
// 这种并列关系下,有可能出最优解
// 所以,枚举每一个可能的并列划分点(split)
int ans = Math.min(p1, Math.min(p2, p3));
for (int split = l; split < r; split++) {
ans = Math.min(ans, process(s, l, split, dp) + process(s, split + 1, r, dp));
}
dp[l][r] = ans;
return ans;
}
}














 705
705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









