







多线程基础知识(三):锁+临界区+锁消耗
前言
- 之前的输出例子中发现,cout的时候输出的内容会错乱,这个就是因为不同线程都使用了相同的输出流
- 原因分析:
1、线程是抢占式的
2、多个线程同时使用了输出流(各自线程并不知道其他线程正在使用输出流)

一、锁的使用
1、锁住整个workFun
a)源码
#include<iostream>
#include<thread>
#include<mutex>
using namespace std;
mutex m;
void workFun(int index)
{
m.lock();
for (int n = 0; n < 4; ++n)
cout << index << "Hello,other thread." << n << endl;
m.unlock();
}
int main()
{
thread t[3];//thread* t[3];
for (int n = 0; n < 3; ++n)
{
t[n] = thread(workFun, n);//t[n] = new thread(workFun, n);
}
for (int n = 0; n < 3; ++n)
{
t[n].join();//t[n]->detach();
}
for (int n = 0; n < 4; ++n)
cout << "Hello,main thread." << endl;
while (true)
{
}
return 0;
}
b)测试
这样锁会导致失去了多线程的意义,每个线程都是按顺序执行的
先执行完0线程,再执行1线程,再执行2线程
我们应该准确的锁住共享的区域,而不是整个函数都锁住

2、仅锁住workFun中cout
a)源码
mutex m;
void workFun(int index)
{
for (int n = 0; n < 40; ++n)
{
m.lock();
cout << index << "Hello,other thread." << n << endl;
m.unlock();
}
}
b)测试
输出结果:可以看到线程之间正常的资源抢占

二、临界区的概念
临界区域术语:用锁锁住的区域,需要被共享的程序段
临界区指的是一个访问共用资源(例如:共用设备或是共用存储器)的程序片段,而这些共用资源又无法同时被多个线程访问的特性
三、计算中使用锁
1、多线程共享计数不使用锁的情况
每次运行得到的sum结果不一样
并且计算的值是错误的
mutex m;
const int tCount = 4;
int sum = 0;
void workFun(int index)
{
for (int n = 0; n < 200000; ++n)
{
//m.lock();
sum++;
//m.unlock();
}
//cout << index << "Hello,other thread." << n << endl;
}
int main()
{
thread t[tCount];
for (int n = 0; n < tCount; ++n)
{
t[n] = thread(workFun, n);
}
for (int n = 0; n < tCount; ++n)
{
t[n].join();
}
cout << "sum=" << sum << endl;
cout << "Hello,main thread." << endl;
return 0;
}

2、计算时加锁
可以得到最后的正确结果:800000
void workFun(int index)
{
for (int n = 0; n < 200000; ++n)
{
m.lock();
sum++;
m.unlock();
}
//cout << index << "Hello,other thread." << n << endl;
}

四、锁的消耗
1、添加高精度计时
为了测试锁的消耗,我们使用之前的高精度计时CELLTimestamp.hpp
mutex m;
const int tCount = 4;
int sum = 0;
void workFun(int index)
{
for (int n = 0; n < 200000; ++n)
{
m.lock();
sum++;
m.unlock();
}
//cout << index << "Hello,other thread." << n << endl;
}
int main()
{
thread t[tCount];
for (int n = 0; n < tCount; ++n)
{
t[n] = thread(workFun, n);
}
CELLTimestamp tTime;
for (int n = 0; n < tCount; ++n)
{
t[n].join();
}
cout << tTime.getElapsedTimeInMilliSec() << ",sum=" << sum << endl;
cout << "Hello,main thread." << endl;
return 0;
}
2、测试锁消耗
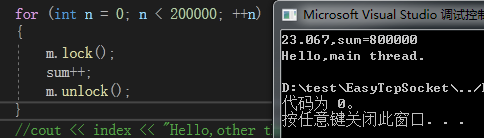
- Release86 -> 加锁 -> 每个线程计算20万次 -> 消耗23.067ms
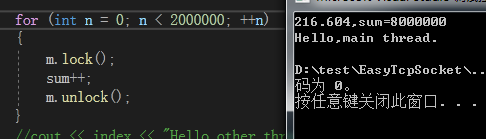
- Release86 -> 加锁 -> 每个线程计算200万次 -> 消耗216.604ms
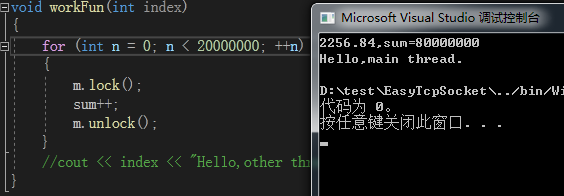
- Release86 -> 加锁 -> 每个线程计算2000万次 -> 消耗2256.84ms
3、对比主线程直接计算的消耗
- Release86 -> 每个线程计算2000万次
锁 -> 2169.24ms
主线程 -> 0ms- 可以得出结论,消耗集中在m.lock()与m.unlock()

4、测试线程启动的消耗
- Debug86 -> 每个线程计算2000万次 -> 注释掉锁的操作
可以看到还是会比主线程消耗的时间多
而这些时间就是线程启动所消耗的时间
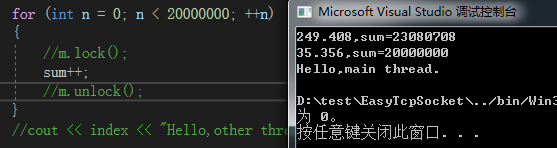
- Release86 -> 每个线程计算2000万次 -> 注释掉锁的操作
这个0.149ms也就是线程启动的消耗了

五、完整源码
1、main.cpp
#include<iostream>
#include<thread>
#include<mutex>
#include"CELLTimestamp.hpp"
using namespace std;
mutex m;
const int tCount = 4;
int sum = 0;
void workFun(int index)
{
for (int n = 0; n < 20000000; ++n)
{
//m.lock();
sum++;
//m.unlock();
}
//cout << index << "Hello,other thread." << n << endl;
}
int main()
{
thread t[tCount];
for (int n = 0; n < tCount; ++n)
{
t[n] = thread(workFun, n);
}
CELLTimestamp tTime;
for (int n = 0; n < tCount; ++n)
{
t[n].join();
}
cout << tTime.getElapsedTimeInMilliSec() << ",sum=" << sum << endl;
sum = 0;
tTime.update();
for (int n = 0; n < 20000000; ++n)
{
sum++;
}
cout << tTime.getElapsedTimeInMilliSec() << ",sum=" << sum << endl;
cout << "Hello,main thread." << endl;
return 0;
}
2、CELLTimestamp.hpp
#ifndef _CELLTimestamp_hpp_
#define _CELLTimestamp_hpp_
//#include <windows.h>
#include<chrono>
using namespace std::chrono;
class CELLTimestamp
{
public:
CELLTimestamp()
{
//QueryPerformanceFrequency(&_frequency);
//QueryPerformanceCounter(&_startCount);
update();
}
~CELLTimestamp()
{}
void update()
{
//QueryPerformanceCounter(&_startCount);
_begin = high_resolution_clock::now();
}
/**
* 获取当前秒
*/
double getElapsedSecond()
{
return getElapsedTimeInMicroSec() * 0.000001;
}
/**
* 获取毫秒
*/
double getElapsedTimeInMilliSec()
{
return this->getElapsedTimeInMicroSec() * 0.001;
}
/**
* 获取微妙
*/
long long getElapsedTimeInMicroSec()
{
/*
LARGE_INTEGER endCount;
QueryPerformanceCounter(&endCount);
double startTimeInMicroSec = _startCount.QuadPart * (1000000.0 / _frequency.QuadPart);
double endTimeInMicroSec = endCount.QuadPart * (1000000.0 / _frequency.QuadPart);
return endTimeInMicroSec - startTimeInMicroSec;
*/
return duration_cast<microseconds>(high_resolution_clock::now() - _begin).count();
}
protected:
//LARGE_INTEGER _frequency;
//LARGE_INTEGER _startCount;
time_point<high_resolution_clock> _begin;
};
#endif // !_CELLTimestamp_hpp_
















 1050
1050











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











