







 本文深入浅出地介绍了Java编程的基础知识,包括面向对象编程、类与对象、构造方法、继承与多态等核心概念。同时,文章还探讨了Java集合框架、泛型、IO流、网络编程等高级主题,以及SpringData、SpringCloud等现代Java开发框架的应用。
本文深入浅出地介绍了Java编程的基础知识,包括面向对象编程、类与对象、构造方法、继承与多态等核心概念。同时,文章还探讨了Java集合框架、泛型、IO流、网络编程等高级主题,以及SpringData、SpringCloud等现代Java开发框架的应用。
Java体系学习
一、主流语言介绍
1、c语言:底层编程,比如嵌入式、病毒开发等应用,可以替代汇编语言来开发系统程序;高层应用可以开发从操作系统到各种应用软件。是一种面向过程的语言。
2、java:广泛应用于企业级软件开发、安卓移动应用开发、大数据云计算等领域。
3、Python:在人工智能方面有很大优势,广泛用于图形处理、科学计算、web编程、引擎开发、多媒体应用。被称为胶水语言,能够调用其他语言制作的各种模块(尤其C/C++)。
4、C++:是c语言的扩展,是一种面向对象的语言,在操作系统、引擎开发等广泛应用,但是,大部分被java取代。
5、C#:是微软开发的一种语言,用于取代java,但是没有成功。C#是基于windows操作系统的应用开发,正在取代C++;但是在游戏开发(unity3D),使用C#和JavaScript。
6、JavaScript:是一种脚本语言,主要用于前端(浏览器)的开发。与html和css结合使用。
7、PHP:一般用于web开发,主要用于网站的开发(效率比较高)。
8、swift:是应用于苹果应用的开发,与oc(object-c)共同应用于苹果平台(mac os和ios)。
9、kotlin:是谷歌公司新推出来的一种应用于Android的开发语言。是基于jvm的内核语言,和java是兼容的,用于取代java语言。
二、学习路线
第一步学习技术;第二部积累经验;第三步积累人脉。并行开展,五年的时间就会出现分层,显现出差别。
三、java基础学习
(一)、面向对象编程
1、面向对象和面向过程是相辅相成的关系,二者都是解决问题的思维方式。
面向过程用于解决简单的问题,对于复杂问题,需要协作的就需要使用面向对象来解决。
对于复杂问题,宏观上使用面向对象来把握,微观处理任然使用面向过程(即程序中的方法)。
例如:开车可以使用面向过程,而造成使用面向过程就比较麻烦了,可以使用面向对象来解决,车这个对象由哪些对象组成,每个对象建好,将其组装成汽车。
2、量变引起质变,世物的发展规律,原有方法不在适用,需要引入新的解决方式。
3、类、对象、实例、属性和方法的学习。
类是一类事物的抽象;对象和实例是类的实例;属性是对象的静态属性;方法是对象的功能。
4、类变量:类变量(也叫静态变量)是类中独立于方法之外的变量,用static 修饰。(static表示“全局的”、“静态的”,用来修饰成员变量和成员方法,或静态代码块(静态代码块独立于类成员,jvm加载类时会执行静态代码块,每个代码块只执行一次,按顺序执行))。静态变量可以通过:ClassName.VariableName的方式访问。静态变量除了被声明为常量外很少使用。(本类中的静态方法可以直接使用,其他类的静态方法使用类名.方法名)
5、构造方法:构造方法用来初始化对象,与方法的定义区分开,构造方法没有返回值类型。
如果没有显式地为类定义构造方法,Java编译器将会为该类提供一个默认构造方法。在创建一个对象的时候,至少要调用一个构造方法。构造方法的名称必须与类同名,一个类可以有多个构造方法。
6、源文件声明规则:一个源文件中只能有一个public类;一个源文件可以有多个非public类;源文件的名称应该和public类的类名保持一致;如果源文件包含import语句,那么应该放在package语句和类定义之间。Import语句就是用来提供一个合理的路径,使得编译器可以找到某个类。例如:import java.io.*;
(1)继承(extends和implements)
子类拥有父类的非private的属性和方法;子类拥有自己的属性和方法,即子类可以对父类进行扩展;子类可以用自己的方式实现父类的方法(重写);Java的继承是单继承,但是可以多重继承,单继承就是一个子类只能继承一个父类,多重继承就是,例如A类继承B类,B类继承C类,所以按照关系就是C类是B类的父类,B类是A类的父类,这是java继承区别于C++继承的一个特性;提高了类之间的耦合性(继承的缺点,耦合度高就会造成代码之间的联系越紧密,代码独立性越差)。
- 继承关键字:继承可以使用 extends 和 implements 这两个关键字来实现继承,而且所有的类都是继承于 java.lang.Object,当一个类没有继承的两个关键字,则默认继承object(这个类在 java.lang 包中,所以不需要 import)祖先类。
- implements 关键字可以变相的使java具有多继承的特性,使用范围为类继承接口的情况,可以同时继承多个接口(接口跟接口之间采用逗号分隔)。
- super关键字:我们可以通过super关键字来实现对父类成员的访问,用来引用当前对象的父类。this关键字:指向自己的引用。
- final定义的类不能继承;修饰的方法不能被子类重写。(用于保护父类方法)
- 子类是不继承父类的构造器(构造方法或者构造函数)的,它只是调用(隐式或显式)。如果父类的构造器带有参数,则必须在子类的构造器中显式地通过 super 关键字调用父类的构造器并配以适当的参数列表。
- 如果父类构造器没有参数,则在子类的构造器中不需要使用 super 关键字调用父类构造器,系统会自动调用父类的无参构造器。
(2)多态
1、重写(override):重写是子类对父类的允许访问的方法的实现过程进行重新编写, 返回值和形参都不能改变。即外壳不变,核心重写!需要在子类中调用父类的被重写方法时,要使用super关键字。
2、构造方法不能被重写;如果不能继承一个方法,则不能重写这个方法。
3、重载(overload):是在一个类里面,方法名字相同,而参数不同。返回类型可以相同也可以不同;方法能够在同一个类中或者在一个子类中被重载;无法以返回值类型作为重载函数的区分标准;被重载的方法可以改变访问修饰符;
4、多态是同一个行为具有多个不同表现形式或形态的能力。应用于接口,子类实现接口展示不同的行为方法。要想调用父类中被重写的方法,则必须使用关键字super。指向子类的父类引用由于向上转型了,它只能访问父类中拥有的方法和属性,而对于子类中存在而父类中不存在的方法,该引用是不能使用的,尽管是重载该方法。若子类重写了父类中的某些方法,在调用该些方法的时候,必定是使用子类中定义的这些方法(动态连接、动态调用)。
5、抽象类:除了不能实例化对象之外,类的其它功能依然存在,成员变量、成员方法和构造方法的访问方式和普通类一样。抽象类和接口区分开:接口中的抽象方法可以省略abstract关键字,抽象类中的抽象方法不能省略。抽象类的子类必须给出抽象类中的抽象方法的具体实现,除非该子类也是抽象类。
(3)封装
1、封装可以防止该类的代码和数据被外部类定义的代码随机访问。最主要的功能在于我们能修改自己的实现代码,而不用修改那些调用我们代码的程序片段。即:类内部的结构可以自由修改,减少耦合。
2、实现封装:修改属性的可见性来限制对属性的访问,属性设置为private,这样外部类不能访问该类的私有属性;对每个属性设置对外的公共方法访问,通过setter和getter方法提供外部类访问该类的私有属性。 this 关键字是为了解决实例变量(private String name)和局部变量(setName(String name)中的name变量)之间发生的同名的冲突。
(4)接口(interface)
1、结构不能用于实例化对象;接口没有构造方法;接口中的所有方法都是抽象方法;接口不能包含成员变量,除了static和final变量(接口中的变量会被隐式的指定为 public static final 变量(并且只能是 public,用 private 修饰会报编译错误,因此接口中的方法默认为public));接口支持多继承;
2、 一个类只能继承一个抽象类,而一个类却可以实现多个接口。
3、接口的主要作用:将方法和方法的实现进行分离。
(5)内部类
内部类的好处:可以直接使用外部类的属性和方法。(工作中很少使用)。
1、广泛意义上的内部类一般来说包括这四种:成员内部类、局部内部类、匿名内部类和静态内部类。
2、匿名内部类:匿名内部类用来解决只需创建该类或者接口一个对象的问题,其中匿名内部类默认隐式继承该类或者实现该接口。使用匿名内部类能够在实现父类或者接口中的方法情况下同时产生一个相应的对象,但是前提是这个父类或者接口必须先存在才能这样使用。例如:我想吃一桶泡面,我不可能建一个厂,制造一个流水线,生产一包泡面之后就在也不去使用这个泡面厂了。
匿名内部类应该是平时我们编写代码时用得最多的,在编写事件监听的代码时使用匿名内部类不但方便,而且使代码更加容易维护。匿名内部类的好处是可以不用创建过多的实现类,但是坏处是,匿名内部类不能重用。
一般来说,匿名内部类用于继承其他类或是实现接口,并不需要增加额外的方法,只是对继承方法的实现或是重写。使用格式:new 类或者接口(){//方法体}

Eclipse查询类的层级(hierarchy)关系:选中类或接口,ctrl+t;或者右键选择Open Type Hierarchy。
Breadcrumb:导航;explicit:显式的
注意:父类已经定义了一个有参的构造器,此时编译器不会为你调用默认的构造器,当子类继承时,必须在自己的构造函数显示调用父类的构造器,自己才能确保子类在初始化前父类会被实例化
(二)java修饰符
1、java修饰符,主要分为访问修饰符和非访问修饰符。
Java中,可以使用访问控制符来保护对类、变量、方法和构造方法的访问。
2、Java 支持 4 种不同的访问权限。
default (即缺省,什么也不写): 在同一包内可见,不使用任何修饰符。使用对象:类、接口、变量、方法。
private : 在同一类内可见。使用对象:变量、方法。 注意:不能修饰类(外部类)
public : 对所有类可见。使用对象:类、接口、变量、方法
protected : 对同一包内的类和所有子类可见。使用对象:变量、方法。 注意:不能修饰类(外部类)。
protected 需要从以下两个点来分析说明:
子类与基类在同一包中:被声明为 protected 的变量、方法和构造器能被同一个包中的任何其他类访问;
子类与基类不在同一包中:那么在子类中,子类实例可以访问其从基类继承而来的 protected 方法,而不能访问基类实例的protected方法。
3、访问控制和继承
请注意以下方法继承的规则:
父类中声明为 public 的方法在子类中也必须为 public。
父类中声明为 protected 的方法在子类中要么声明为 protected,要么声明为 public,不能声明为 private。
父类中声明为 private 的方法,不能够被继承。
4、非访问修饰符
(1)static 修饰符,用来修饰类方法和类变量。对类变量和方法的访问可以直接使用 classname.variablename 和 classname.methodname 的方式访问。
(2)final 修饰符,用来修饰类、方法和变量,final 修饰的类不能够被继承,修饰的方法不能被继承类重新定义,修饰的变量为常量,是不可修改的。
Final修饰变量一旦赋值后,不能被重新赋值。被 final 修饰的实例变量必须显式指定初始值;
类中的 final 方法可以被子类继承,但是不能被子类修改。声明 final 方法的主要目的是防止该方法的内容被修改;final 类不能被继承,没有类能够继承 final 类的任何特性。
(3)abstract 修饰符,用来创建抽象类和抽象方法。抽象类不能用来实例化对象,声明抽象类的唯一目的是为了将来对该类进行扩充。任何继承抽象类的子类必须实现父类的所有抽象方法,除非该子类也是抽象类。如果一个类包含若干个抽象方法,那么该类必须声明为抽象类。抽象类可以不包含抽象方法。
(4)synchronized主要用于线程的编程。synchronized 关键字声明的方法同一时间只能被一个线程访问。synchronized 修饰符可以应用于四个访问修饰符。主要用于解决线程同步问题。
(5)volatile 修饰的成员变量在每次被线程访问时,都强制从共享内存中重新读取该成员变量的值。避免原有值的干扰。
(6)transient关键字的作用,简单地说,就是让某些被修饰的成员属性变量不被序列化,Java中对象的序列化指的是将对象转换成以字节序列的形式来表示,这些字节序列包含了对象的数据和信息,一个序列化后的对象可以被写到数据库或文件中,也可用于网络传输,一般当我们使用缓存cache(内存空间不够有可能会本地存储到硬盘)或远程调用rpc(网络传输)的时候,经常需要让我们的实体类实现Serializable接口,目的就是为了让其可序列化。(序列化可以节省内存空间),HashMap源码中modCount主要用于判断HashMap是否被修改,就没有必要将其进行序列化。
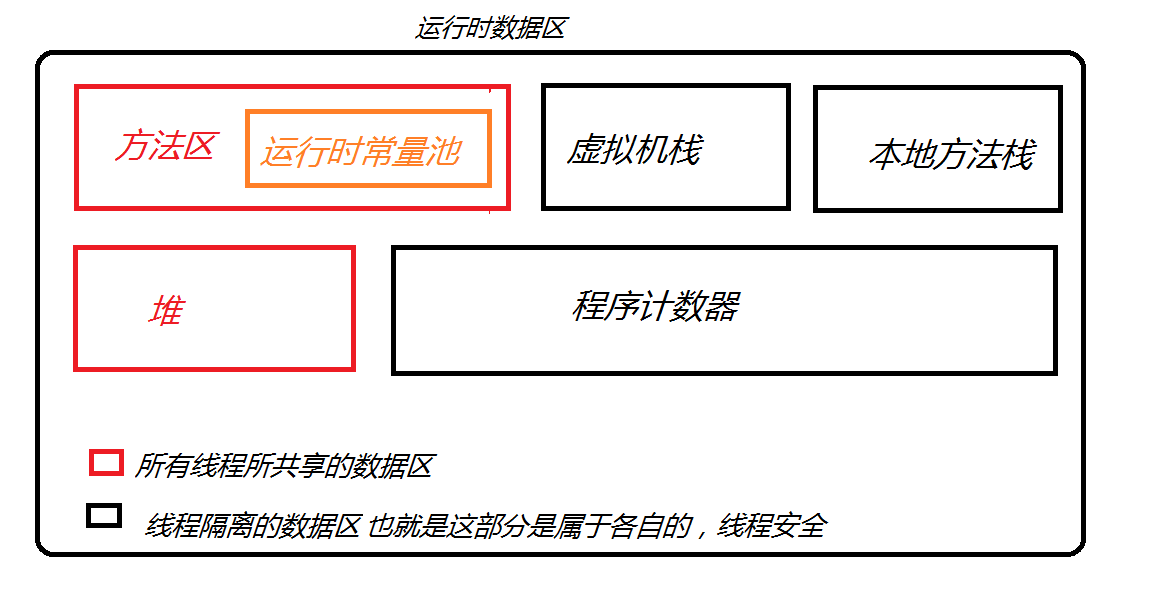
(三)内存分析
1、java虚拟机的内存分为三个区域:栈stack、堆heap、方法区method area(也在堆内存中)、程序计数器
2、栈(stack):栈描述的是方法执行的内存模型,每个方法被调用都会创建一个栈帧(存储局部变量、操作数、方法出口等);JVM为每个线程创建一个栈,用于存放该线程执行方法的信息(实际参数、局部变量等);栈属于线程私有,不能实现线程间的共享;栈的存储特性是先进后出,后进先出;栈是由系统自动分配,是一个连续的内存空间,速度快;方法执行完成后,系统就会将栈空间释放。(每个方法在执行的同时都会创建一个栈帧用来存放存储局部变量表、操作数表、动态连接、方法出口等信息,每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。)分为虚拟机栈和本地方法栈。
3、堆(heap):堆用于存储创建好的对象和数组(数组也是对象),存储对象的相关信息;JVM只有一个堆,被所有线程之间共享;堆是一个不连续的空间,使用灵活,速度慢。(java的垃圾回收机制自动释放空间)。
4、方法区(method area):JVM只有一个方法区,被所有线程共享;方法区本质也是堆,只用于存储类、常量相关的信息;用来存储程序中永远不变或唯一的内容(类代码信息、静态变量、字符串常量等)。自从JDK7之后,Hotspot虚拟机便将运行时常量池从永久代移除了。
5、程序计数器:JVM规范中规定,如果线程执行的是非native方法,则程序计数器中保存的是当前需要执行的指令地址,如果线程执行的是native方法,则程序计数器中的值undefined。每个线程都有自己独立的程序计数器。为什么呢?因为多线程下,一个CPU内核只会执行一条线程中的指令,因此为了使每个线程在线程切换之后能够恢复到切换之前的程序执行的位置,所以每个线程都有自己独立的程序计数器。
(四)飞机小游戏练习
1、AWT和Swing是java最常见的GUI(图形用户界面)技术,但由于java很少用于桌面软件开发,很少使用,了解即可。
2、AWT:AWT(Abstract Window Toolkit):抽象窗口工具包,早期编写图形界面应用程序的包。
AWT的图形函数与操作系统提供的图形函数有着一一对应的关系。也就是说,当我们利用 AWT构件图形用户界面的时候,实际上是在利用操作系统的图形库。 不同的操作系统其图形库的功能可能不一样,在一个平台上存在的功能在另外一个平台上则可能不存在。为了实现Java语言所宣称的"一次编译,到处运行"的概念,AWT不得不通过牺牲功能来实现平台无关性。因此,AWT 的图形功能是各操作系统图形功能的“交集”。 因为AWT是依靠本地方法来实现功能的,所以AWT控件称为“重量级控件”。
3、Swing :为解决 AWT 存在的问题而新开发的图形界面包。Swing是对AWT的改良和扩展。Swing ,不仅提供了AWT 的所有功能,还用纯粹的Java代码对AWT的功能进行了大幅度的扩充。 Swing是用纯粹的Java代码来实现的,因此Swing控件在各平台通用。因为Swing不使用本地方法,故Swing控件称为“轻量级控件”。
4、AWT和Swing之间的区别: 1)AWT 是基于本地方法的C/C++程序,其运行速度比较快;Swing是基于AWT的Java程序,其运行速度比较慢。 2)AWT的控件在不同的平台可能表现不同,而Swing在所有平台表现一致。
5、Swing是AWT的扩展,它提供了许多新的图形界面组件。Swing组件以“J”开头,除了拥有与AWT类似的按钮(JButton)、标签(JLabel)、复选框(JCheckBox)、菜单(JMenu)等基本组件外,还增加了一个丰富的高层组件集合,如表格(JTable)、树(JTree)。在javax.swing包中,定义了两种类型的组件:顶层容器(Jframe、Japplet、JDialog和JWindow)和轻量级组件。
除了Swing顶层容器类(top level containers)以外,其余所有的Swing组件类都继承自JComponent类,如前所述,JComponent类是Container类的子类,因此,所有的Swing组件都可作为容器使用。Swing顶层容器类包括了JFrame、JDialog、JApplet、JWindow,它们为其他的Swing组件提供了绘制自身的场所。
顶层容器中: (1)JApplet可作为java小应用程序的窗体,但通常使用java.applet.Applet类来创建小应用程序。 (2)JFrame集成自AWTFrame类,通常作为主窗体使用。 (3)JDialog用于创建对话框的窗体。 (4)JWindow与AWT中的Window相似,但几乎不用,因为没有太大的实用价值。
(四)进程和线程
线程作为调度和分配的基本单位,进程作为拥有资源的基本单位。线程是进程中执行运算的最小单位,是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。资源分配给进程,同一进程的所有线程共享该进程的所有资源。
线程是进程中的一个执行路径。进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位
一、创建线程的方法:
- 通过实现 Runnable 接口;重写run()方法,其中run()方法为线程的执行主体即线程的执行内容,是线程的执行入口。调用线程,需要调用Thread类的start()方法来告知虚拟机执行线程的run()方法。注意:Runnable接口没有重写start()方法,需要利用Thread类来调用Start()方法。利用Thread类的构造方法,Thread(Runnable target)。
- 通过继承 Thread 类本身;本质也是实现的Runnable接口。
- 通过 Callable 和 Future 创建线程。
(五)面向对象和数组
一、回调函数(callback)的使用:主要运用了多态的思想,父类引用指向子类对象。主要用于解决异步应用之间的通信,提高工作效率。
二、回调函数具备两个基本条件
1.Class A调用Class B中的X方法
2.ClassB中X方法执行的过程中调用Class A中的Y方法完成回调
实例分析:假设你公司的总经理出差前需要你帮他办件事情,这件事情你需要花些时间去做,这时候总经理肯定不能守着你做完再出差吧,于是就他告诉你他的手机号码叫你如果事情办完了你就打电话告诉他一声;其中这个打电话告诉领导就是回调函数的使用。
Interface Callback{ public void back(); }
Class A implements Callback{ //重写back方法 bushu(B b){ b.doWork(this,”完成需求”){ //方法执行} }//A类部署工作的方法} //理解doWork方法中this的使用
Class B { void doWork(Callback cb,String task){ //B的工作方法 cb.back()//执行回调方法,通知A类} }
三、数组的使用:
数组使用格式:数据类型[ ] 数据名= new 数据类型[数组大小];
1、length是数组的属性,表示数组的大小;length()是String的方法,表示字符串的长度;
Size()是集合的方法。
2、数组的元素类型和数组的大小都是确定的,通常使用基本循环和加强的foreach循环,
Foreach循环:for(元素类型t 元素变量x : 遍历对象obj){ //引用x的java语句;}3、java.util.Arrays 类能方便地操作数组,它提供的所有方法都是静态的。类的静态方法的调用是直接使用类名进行调用,即:类名.方法名();
4、return的使用方法:1、返回一个值给调用该方法的语句,返回值的数据类型必须与方法的声明中的返回值的类型一致;2、return后面也可以不带参数,不带参数就是返回空,其实主要目的就是用于想中断函数执行,返回调用函数处。
(六)常用类
1、java中的包装类:Java 1.5 之后可以自动拆箱装箱,也就是在进行基本数据类型和对应的包装类转换时,系统将自动进行,这将大大方便程序员的代码书写。例如:Integer in = new Integer(4); int a = in; //in会自动拆箱为int数据类型(系统自动完成)。
2、抽象类 Number 是 BigDecimal、BigInteger、Byte、Double、Float、Integer、Long 和 Short 类的超类。含有转换为各种基本数据类型的抽象方法。注意:==和equals的区别:==比较的是对象的地址;equals比较的是对象的内容。Java 会对 -128 ~ 127 的整数进行缓存,所以当定义两个变量初始化值位于 -128 ~ 127 之间时,两个变量使用了同一地址;超过该范围的,会使用不同的地址。
3、Math类包含了用于执行基本数学运算的属性和方法,如初等指数、对数、平方根和三角函数。Math 的方法都被定义为 static 形式,都是静态方法,直接通过Math类调用。注意:random() 方法用于返回一个随机数(double类型),随机数范围为 0.0 =< Math.random() < 1.0。
4、字符创相关类:
不可变字符序列:String;数字自动转化为字符串:直接通过空字符串+数字的形式转换为字符串。
可变字符序列:StringBuffer、StringBuilder
5、时间处理相关类
一、Date
从 JDK 1.1 开始,应该使用 Calendar 类实现日期和时间字段之间转换,使用 DateFormat 类来格式化和解析日期字符串。Date 中的相应方法已废弃。Date类的对象表示一个特定的瞬间,时间精确到毫秒。
Java中时间的表示说白了也是数字,是从:标准纪元1970.1.1 0点开始到某个时刻的毫秒数,类型是long。定义long类型,数字后要L。
二、DateFormat、SimpleDateFormat:完成字符串和时间对象的转化。DateFormat是抽象类,SimpleDateFormat是DateFormat的子类。SimpleDateFormat 是一个以与语言环境有关的方式来格式化和解析日期的具体类。它允许进行格式化(日期 -> 文本)、解析(文本 -> 日期)和规范化。Format(Date)将日期对象转化为制定格式的字符串;parse(String)将字符串转化为制定格式的日期对象。
三、Calendar是一个抽象类(Calendar类不能直接创建实例),GregorianCalendar是Calendar类的一个具体实现。它为特定瞬间与一组诸如YEAR、MONTH、DAY_OF_MONTH、HOUR等日历字段之间的转换提供了一些方法,并为操作日历字段(例如获得下个星期的日期)提供了一些方法;瞬间可用毫秒值来表示,它是距历元(格林威治时间1970年1月1日的00:00:00.000)的偏移量。将日期和long类型的数字(毫秒)进行转换。
注意:一月是0,二月是1,以此类推。
星期:周日是1,周二是2、以此类推。
6、File类
(七)容器和数据结构
一、数据结构:是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。合适的数据结构可以提高运行或者存储效率。包括数据的逻辑结构、存储结构(物理结构)和数据之间的运算。
1、逻辑结构主要包括:集合:数据同属一个集合外,无其他关系。
线性结构:数据元素存在一对一的相互关系。
树形结构:数据元素存在一对多的相互关系。
图形结构:数据元素存在多对多的相互关系。
2、存储结构(物理结构):指数据的逻辑结构在计算机存储空间的存放形式。主要包括:顺序存储结构和链式存储结构。
顺序存储结构:是把逻辑上相邻的结点存储在物理位置相邻的存储单元里,结点间的逻辑关系由存储单元的邻接关系来体现。
链接存储结构:不要求逻辑上相邻的结点在物理位置上也相邻,结点间的逻辑关系是由附加的指针字段表示的。
数据结构的形式定义为:数据结构是一个二元组 :Data_Structure=(D,R),其中,D是数据元素的有限集,R是D上关系的有限集。
二、容器
面向对象语言对事物的体现都是以对象的形式存在,所以为了方便对多个对象的操作,就对对象进行存储,集合就是存储对象最常用的一种方式。集合只用于存储对象,集合长度是可变的,集合可以存储不同类型的对象。如果往集合里存放基本数据类型,在存取过程中会有个自动装箱和拆箱。与数组区分开,数组是长度固定,效率更高。集合的长度是可变的。
数组可以存储基本数据类型,也可以存储引用数据类型;集合只能存储引用数据类型。
数组存储的元素必须是同一个数据类型;集合存储的对象可以是不同数据类型(集合对不同数据类型会自动装箱和拆箱,装箱成为对象,实现存储)。
任何对象加入集合类后,自动转变为Object类型,所以在取出的时候,需要进行强制类型转换。(为使集合更加通用,即可以装载任何对象,将对象利用多态向上转型,变为Object类型进行存储;将对象从集合中取出时,对其进行类型强制转换,变为需要的对象类型。例如:球和篮球、足球、排球的关系:父类和子类,球框里可以存放篮球、足球和排球,进行存放时,都是默认为球进行存放的,即向上转型;从球框中取球时,也是按照球进行取出的,根据需要进行类型强制转换为所需对象,这样容易造成类型转换异常,未解决该问题,引入泛型的概念,解决了集合存储数据和取数据时避免大量的类型判断。即传入什么类型,取出就什么类型。)
集合框架的类和接口均在java.util包中。
三、泛型(generics)
Java 泛型(generics)是 JDK 5 中引入的一个新特性, 泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。(用来指示集合存储的数据类型)。泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。(将数据类型参数化,这样就可以传入各种类型的数据,方法就可以多样化)。
1、操作的数据类型被指定为一个参数,这种参数类型可以用在类、接口和方法中,分别被称为泛型类、泛型接口、泛型方法。
(八)IO流技术
一、序列化
Java 提供了一种对象序列化的机制,该机制中,一个对象可以被表示为一个字节序列(一个字节等于8位,1Byte=8bit),该字节序列包括该对象的数据、有关对象的类型的信息和存储在对象中数据的类型。(序列化本质:将程序中的对象(数据)通过序列化的方式,保存到本地中。即为了保存在内存中的各种对象的状态,并且可以把保存的对象状态再读出来。可以节省存储空间,方便传输。)整个过程都是java虚拟机JVM中独立实现的。
二、序列化注意事项
1、当一个父类实现序列化,子类自动实现序列化,不需要显式实现Serializable接口;
2、当一个对象的实例变量引用其他对象,序列化该对象时也把引用对象进行序列化;
3、静态变量不属于对象,属于类,不能被序列化。还有瞬态的变量也不能被序列化 。即用transient 修饰的变量。Transient 关键字用在数据类型前方,例如:private transient String name;
三、transient关键字用法
transient就是让某些被修饰的成员属性变量不被序列化。
HashMap源码的时候,发现有个字段是用transient修饰的,我觉得还是有道理的,确实没必要对这个modCount字段进行序列化,因为没有意义,modCount主要用于判断HashMap是否被修改(像put、remove操作的时候,modCount都会自增),对于这种变量,一开始可以为任何值,0当然也是可以(new出来、反序列化出来、或者克隆clone出来的时候都是为0的),没必要持久化其值。
四、java的IO类
Java.io 包几乎包含了所有操作输入、输出需要的类。广泛地应用到文件传输和网络编程中。
1、java生成word的方案:
(1)Apache POI包括一系列的API,他的excel处理很强大,对于word还局限于读取,目前只能实现一些简单文件的操作,不能设置样式。
(2)Java2word是一个在java程序中调用 MS Office Word 文档的组件(类库)。该组件提供了一组简单的接口,以便java程序调用他的服务操作Word 文档。
(3)用XML做就很简单了。Word从2003开始支持XML格式,大致的思路是先用office2003或者2007编辑好word的样式,然后另存为xml,将xml翻译为FreeMarker模板,最后用java来解析FreeMarker模板并输出Doc。经测试这样方式生成的word文档完全符合office标准,样式、内容控制非常便利,打印也不会变形,生成的文档和office中编辑文档完全一样。
(4) iText操作Excel还行。对于复杂的大量的word也是噩梦。用法很简单, 但是功能很少, 不能设置打印方向等问题。
总结:处理word使用Java2word和xml两种方式;处理excel使用poi和itext。
1、File类
File类可以用来创建文件和文件夹(文件夹也可以叫做目录)。
注意: File 类是对文件系统的映射并不是硬盘上真实的文件, new File("xxx.xxx") 只是在内存中创建File文件映射对象,而并不会在硬盘中创建文件。(java通过File类把操作系统与硬盘上的文件建立联系,非常依赖操作系统的文件系统,File对象是一个抽象表示)
文件的状态:一、不存在(先判断文件或文件夹是否存在,用exists() );二、文件;三、文件夹。
2、API的学习
首先了解类的继承管理及其含义作用,类的构造器(无构造器一般是工具类或者存在一个产生对象的方法),类的方法(方法的参数类型和返回值类型)。
3、流(stream)
对文件内容的读写需要使用流来完成。字节流和字符流。建议使用缓冲输入输出流。
(九)网络编程
一、网络编程本质
网络编程的实质就是两个(或多个)设备(例如计算机)之间的数据传输。
了解网络编程的含义,首先对节点的ip和端口进行定位,建立连接,进行数据传输。API中会有具体的类实现该功能。
二、计算机网络 按照计算机网络的定义,通过一定的物理设备将处于不同位置的计算机连接起来组成的网络,这个网络中包含的设备有:计算机、路由器、交换机等等。 其实从软件编程的角度来说,对于物理设备的理解不需要很深刻,就像你打电话时不需要很熟悉通信网络的底层实现是一样的,但是当深入到网络编程的底层时,这些基础知识是必须要补的。 路由器和交换机组成了核心的计算机网络,计算机只是这个网络上的节点以及控制等,通过光纤、网线等连接将设备连接起来,从而形成了一张巨大的计算机网络。 网络最主要的优势在于共享:共享设备和数据,现在共享设备最常见的是打印机,一个公司一般一个打印机即可,共享数据就是将大量的数据存储在一组机器中,其它的计算机通过网络访问这些数据,例如网站、银行服务器等等。 如果需要了解更多的网络硬件基础知识,可以阅读《计算机网络》教材,对于基础进行强化,这个在基础学习阶段不是必须的,但是如果想在网络编程领域有所造诣,则是一个必须的基本功。
三、IP地址 对于网络编程来说,最主要的是计算机和计算机之间的通信,这样首要的问题就是如何找到网络上的计算机呢?这就需要了解IP地址的概念。 为了能够方便的识别网络上的每个设备,网络中的每个设备都会有一个唯一的数字标识,这个就是IP地址。在计算机网络中,现在命名IP地址的规定是IPv4协议,该协议规定每个IP地址由4个0-255之间的数字组成,例如10.0.120.34。每个接入网络的计算机都拥有唯一的IP地址,这个IP地址可能是固定的,例如网络上各种各样的服务器,也可以是动态的,例如使用ADSL拨号上网的宽带用户,无论以何种方式获得或是否是固定的,每个计算机在联网以后都拥有一个唯一的合法IP地址,就像每个手机号码一样。 但是由于IP地址不容易记忆,所以为了方便记忆,有创造了另外一个概念——域名(Domain Name),例如sohu.com等。一个IP地址可以对应多个域名,一个域名只能对应一个IP地址。域名的概念可以类比手机中的通讯簿,由于手机号码不方便记忆,所以添加一个姓名标识号码,在实际拨打电话时可以选择该姓名,然后拨打即可。 在网络中传输的数据,全部是以IP地址作为地址标识,所以在实际传输数据以前需要将域名转换为IP地址,实现这种功能的服务器称之为DNS服务器,也就是通俗的说法叫做域名解析。例如当用户在浏览器输入域名时,浏览器首先请求DNS服务器,将域名转换为IP地址,然后将转换后的IP地址反馈给浏览器,然后再进行实际的数据传输。 当DNS服务器正常工作时,使用IP地址或域名都可以很方便的找到计算机网络中的某个设备,例如服务器计算机。当DNS不正常工作时,只能通过IP地址访问该设备。所以IP地址的使用要比域名通用一些。 IP地址和域名很好的解决了在网络中找到一个计算机的问题,但是为了让一个计算机可以同时运行多个网络程序,就引入了另外一个概念——端口(port)。
四、端口的概念
端口用两个字节标识,即一个16位的二进制整数表示,对应十进制的0-65535。
公认端口:0-1023,分配给公共服务应用。
注册端口:1024-49151,分配给用户进程或应用程序。
动态/私有端口:49152-65535
同一个协议内端口号不能重复,不同协议端口号可以重复(不建议这么用)。
端口命令:
查看所有端口:netstat -ano
查看指定端口:netstat -ano|findstr “端口号”
查看指定进程:tasklist|findstr ”PID”
查看具体程序:使用任务管理器查看pid(pid是进程标识符)
管道符号,是unix一个很强大的功能,符号为一条竖线:"|"。用法: command 1 | command 2 他的功能是把第一个命令command 1执行的结果作为command 2的输入传给command 2。(逻辑运算符中表示或)
使用InetSocketAddress类包含端口,用于socket通信(socket是插座的意思,相当于接通)。 在介绍端口的概念以前,首先来看一个例子,一般一个公司前台会有一个电话,每个员工会有一个分机,这样如果需要找到这个员工的话,需要首先拨打前台总机,然后转该分机号即可。这样减少了公司的开销,也方便了每个员工。在该示例中前台总机的电话号码就相当于IP地址,而每个员工的分机号就相当于端口。 有了端口的概念以后,在同一个计算机中每个程序对应唯一的端口,这样一个计算机上就可以通过端口区分发送给每个端口的数据了,换句话说,也就是一个计算机上可以并发运行多个网络程序,而不会在互相之间产生干扰。 在硬件上规定,端口的号码必须位于0-65535之间,每个端口唯一的对应一个网络程序,一个网络程序可以使用多个端口。这样一个网络程序运行在一台计算上时,不管是客户端还是服务器,都是至少占用一个端口进行网络通讯。在接收数据时,首先发送给对应的计算机,然后计算机根据端口把数据转发给对应的程序。 有了IP地址和端口的概念以后,在进行网络通讯交换时,就可以通过IP地址查找到该台计算机,然后通过端口标识这台计算机上的一个唯一的程序。这样就可以进行网络数据的交换了。 但是,进行网络编程时,只有IP地址和端口的概念还是不够的,下面就介绍一下基础的网络编程相关的软件基础知识。
1.2网络编程概述 网络编程中有两个主要的问题,一个是如何准确的定位网络上一台或多台主机,另一个就是找到主机后如何可靠高效的进行数据传输。在TCP/IP协议中IP层主要负责网络主机的定位,数据传输的路由,由IP地址可以唯一地确定Internet上的一台主机。而TCP层则提供面向应用的可靠的或非可靠的数据传输机制,这是网络编程的主要对象,一般不需要关心IP层是如何处理数据的。 按照前面的介绍,网络编程就是两个或多个设备之间的数据交换,其实更具体的说,网络编程就是两个或多个程序之间的数据交换,和普通的单机程序相比,网络程序最大的不同就是需要交换数据的程序运行在不同的计算机上,这样就造成了数据好换的复杂。虽然通过IP地址和端口号可以找到网络上运行的一个程序,但是如果需要进行网络编程,则需要了解网络通讯的过程。 网络通讯基于“请求—响应”模型。在网络通讯中,第一次主动发起通讯的程序被称为客户端(client)程序,简称客户端,而第一次通讯中等待链接的程序被称为服务器端(Server)程序,简称服务器。一旦通讯建立,则客户端和服务器端完全一样,没有本质区别。 由此,网络编程中的两种程序就分别是客户端和服务器端,例如QQ程序,每个QQ用户安装的都是QQ客户端程序,而QQ服务器端程序则在腾讯公司的机房中,为大量的QQ用户提供服务。这种网络编程的结构被称为客户端/服务器结构,也叫Client/Serverj结构,简称C/S结构。 使用C/S结构的程序,在开发时需要分别开发客户端和服务器端,这种结构的优势在于客户端是专门开发的,所以根据需要实现各种效果,专业点的说就是表现力丰富,而服务器端也需要专门进行开发。但是这种结构也存在着很多不足,例如通用性差,几乎不能通用,也就是说一种程序的客户端只能和对应的服务器端通讯,而不能和其他服务器端通讯,在实际维护中,也需要维护专门的客户端和服务器端,维护的压力比较大。 其实在运行很多程序时,没有必要使用专门的客户端,而需要使用通用的客户端,例如浏览器,使用浏览器作为客户端的结构称为浏览器/服务器结构,也叫做Browser/Server结构,简称B/S结构。 使用B/S结构的程序,在开发时只需要开发服务器端即可,这种优势在于开发压力比较小,不需要维护客户端,但是这种结构也存在这很多不足,例如浏览器的限制比较大,表现了不强,不能进行系统级别的操作等。 总之C/S结构和B/S结构是现在网络编程中常见的两种结构,B/S结构其实也就是一种特殊的C/S结构。 另外简单的介绍一下P2P(Point to Point)程序,常见的如BT、电驴等。P2P程序是一种特殊的程序,应该一个P2P程序中既包含客户端程序,也包含服务器端程序,例如BT,使用客户端程序部分连接其它的种子(服务器端),而使用服务器端向其它的BT客户端传输数据。如果这个还不是很清楚,其实P2P程序和手机是一样的,当手机拨打电话时就是使用客户端的作用,而手机处于待机状态时,可以接收到其它用户拨打的电话则起的就是服务器端的功能,只是一般的手机不能同时使用拨打电话和接听电话的功能,而P2P程序实现了该功能。 最后介绍一下网络编程中最重要的,也是最复杂的概念——协议(protocol)。按照前面的介绍,网络编程就是运行在不同计算机中两个程序之间的数据交换。在实际进行数据交换时,为了让接收端理解该数据,计算机比较笨,什么都不懂的,那么久需要规定该数据的格式,这个数据的格式就是协议。 如果没有理解协议的概念,那么再举一个例子,记得有个电影叫《永不消逝的电波》,讲述的是地下党通过电台发送情报的故事,这里我们不探讨电影的剧情,而只关 心电台发送的数据。在实际发报时,需要首先将需要发送的内容转换为电报编码,然后将电报编码发送出去,而接收端接收的是电报编码,如果需要理解电报的内容 则需要根据密码本翻译出该电报的内容。这里的密码本就规定了一种数据格式,这种对于网络中传输的数据格式在网络编程中就被称作协议。 那么如何编写协议格式呢?答案是随意。只要按照这种协议格式能够生成唯一的编码,按照该编码可以唯一的解析出发送数据的内容即可。也正因为各个网络程序之间协议格式的不同,所以才导致了客户端程序都是专用的结构。 在实际的网络编程中,最麻烦的内容不是数据的发送和接受,因为这个功能在几乎所有编程语言中都提供了封装好的API进行调用,最麻烦的内容就是协议的设计及协议的生产和解析,这个才是网络编程最核心的内容。 1.3网络通讯方式 在现有的网络中,网络通讯的方式主要有两种: 1.TCP(传输控制协议)方式。(数据不会丢失) 2.UDP(用户数据协议)方式。 (数据会存在丢失) 为了方便理解这两种方式,还是先来看个例子。大家使用手机时,向别人传递信息时有两种方式:拨打电话和发送短信。使用拨打电话的方式可以保证该信息传递给别人,因为别人接电话时本身就确认收到了该信息。而发送短信的方式价格低廉,使用方便,但是接受人可能收不到。 在网络通讯中,TCP方式就类似于拨打电话,使用该种方式进行网络通讯时,需要建立专门的虚拟连接,然后进行可靠的数据传输,如果数据发送失败,则客户端会自动重发该数据,而UDP方式就类似于发送短信,使用这种方式进行网络通讯时,不需要建立专门的虚拟连接,传输也不是很可靠,如果发送失败则客户端无法获得。 这两种传输方式都是实际的网络编程中进行使用,重要的数据一般使用TCP方式进行数据传输,而大量的非核心数据则都通过UDP方式进行传递,在一些程序中甚至结合使用这两种方式进行数据的传递。 由于TCP需要建立专用的虚拟连接以及确认传输是否正确,所以使用TCP方式的速度稍微慢一些,而且传输时产生的数据量要比UDP稍微大一些。 关于网络编程的基础知识就介绍这么多,如果需要深入了解相关知识请阅读专门的计算机网络书籍,下面开始介绍Java语言中网络编程的相关技术。
1.3网络编程步骤 按照前面的基础知识介绍,无论使用TCP方式还是UDP方式进行网络通讯,网络编程都是由客户端和服务器端组成,所以,下面介绍网络编程的步骤时,均以C/S结构为基础进行介绍。 1.3.1客户端网络编程步骤 客户端是指网络编程中首先发起连接的程序,客户端一般实现程序界面和基本逻辑实现,在进行实际的客户端编程时,无论客户端复杂还是简单,以及客户端实现的方式,客户端的编程主要由三个步骤实现: 1.建立网络连接 客户端网络编程的第一步都是建立网络连接。在建立网络连接时需要指定连接的服务器的IP地址和端口号,建立完成以后,会形成一条虚拟的连接,后续的操作就可以通过该连接实现数据交换了。 2.交换数据 连接建立以后,就可以通过这个连接交换数据了,交换数据严格要求按照请求响应模型进行,由客户端发送一个请求数据到服务器,服务器反馈一个响应数据后给客户端,如果客户端不发送请求则服务器就不响应。 根据逻辑需要,可以多次交换数据,但是还是必须遵循请求响应模型。 3.关闭网络连接 在数据交换完成后,关闭网络连接,释放程序占用的端口、内存等系统资源,结束网络编程。 最基本的步骤一般都是这三个步骤,在实际实现时,步骤2会出现重复,在进行代码组织时,由于网络编程是比较耗时的操作,所以一般开启专门的现场进行网络通讯。
1.4服务器端网络编程步骤 服务器是指网络编程中被等待连接的程序,服务器端一般实现程序的核心逻辑以及数据存储等核心功能。服务器端的编程步骤和客户端不同,是由四个步骤实现,依次是: 1.监听端口 服务器端属于被动等待连接,所以服务器端启动以后,不需要发起连接,而只需要监听本地计算机的某个固定端口即可。这个端口就是服务器端开放给客户端的端口,服务器端程序运行的本地计算机的IP地址就是服务器端程序的IP地址。 2.获得连接 当客户端连接到服务器端时,服务器端就可以获得一个连接,这个连接包含客户端信息,例如客户端IP地址等,服务器端和客户端通过该连接进行数据交换。 一般在服务器端编程中,当获得连接时,需要开启专门的线程处理该连接,每个连接都由独立的线程实现。 3.交换数据 服务器端通过获得的连接进行数据交换。服务器端的数据交换步骤是首先接收客户端发送过来的数据,然后进行逻辑处理,再把处理以后的结果数据发送给客户端。简单来说,就是先接收再发送,这个和客户端的数据交换顺序不同。 其实,服务器端获得的连接和客户端的连接是一样的,只是数据交换的步骤不同。当然,服务器端的数据交换也是可以多次进行的。在数据交换完成以后,关闭和客户端的连接。 4.关闭连接 当服务器程序关闭时,需要关闭服务器端,通过关闭服务器端使得服务器监听的端口以及占用的内存可以释放出来,实现了连接的关闭。 其实服务器端编程的模型和呼叫中心的实现是类似的,例如移动的客服电话10086就是典型的呼叫中心,当一个用户拨打10086时,转接给一个专门的客服人员,由该客服实现和该用户的问题解决,当另外一个用户拨打10086时,则转接给另一个客服,实现问题解决,依次类推。 在服务器端编程时,10086这个电话号码就类似于服务器端的端口号码,每个用户就相当于一个客户端程序,每个客服人员就相当于服务器端启动的专门和客户端连接的线程,每个线程都是独立进行交互的。 这就是服务器端编程的模型,只是TCP方式是需要建立连接的,对于服务器端的压力比较大,而UDP是不需要建立连接的,对于服务器端的压力比较小罢了。 总之,无论使用任何语言,任何方式进行基础的网络编程,都必须遵循固定的步骤进行操作,在熟悉了这些步骤以后,可以根据需要进行逻辑上的处理,但是还是必须遵循固定的步骤进行。 其实,基础的网络编程本身不难,也不需要很多的基础网络知识,只是由于编程的基础功能都已经由API实现,而且需要按照固定的步骤进行,所以在入门时有一定的门槛,希望下面的内容能够将你快速的带入网络编程技术的大门。
五、URL简介(URL类方法可以获取协议、域名ip、端口、参数、锚点)
1、IP用于区分连接到Internet上的主机;端口用于区分主机上的软件;url用于区分主机上软件中的各种资源,URL是浏览器寻找信息时所需的资源位置,通过URL,应用程序才能找到并使用共享因特网上大量的数据资源。
2、URL:(Uniform/Universal Resource Locator 的缩写,统一资源定位符)。
URI:(Uniform Resource Identifier 的缩写,统一资源标识符)。
其中URL和URI的区别:URI属于父类,URL属于URI的子类,URI是用来标识资源的字符串,即资源名字;URL不仅可以用来标识资源,还可以用来定位资源,即如何访问。
3、url包含4部分:协议、存放资源的主机域名、端口号、资源文件名;其中资源名还可以细分:参数和锚点,参数用?与资源文件名分隔,多个参数用&连接;锚点使用#标识。
例如:http://abc.com:8080/dir/index.html?id=255&m=hello#top
(十)注解和反射
一、反射详解
反射就是把java类中的各种成分映射成一个个的Java对象。JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
二、Class对象(本质:Class类用来存储类的相关信息,通过Class对象可以获取类的各种信息)
在Java中有两种对象:Class对象和实例对象,实例对象是类的实例,通常是通过new关键字构建的。Class对象是JVM生成用来保存对象的类的信息的。Java程序执行之前需要经过编译、加载、链接和初始化这几个阶段,编译阶段会将源码文件编译为.class字节码文件,编译器同时会在.class文件中生成Class对象,加载阶段通过JVM内部的类加载机制,将Class对象加载到内存中。在创建对象实例之前,JVM会先检查Class对象是否在内存中存在,如果不存在,则加载Class对象,然后再创建对象实例,如果存在,则直接根据Class对象创建对象实例。JVM中只有一个Class对象,但可以根据Class对象生成多个对象实例。
Java程序在运行时,Java运行时系统一直对所有的对象进行所谓的运行时类型标识,即所谓的RTTI。这项信息纪录了每个对象所属的类。虚拟机通常使用运行时类型信息选准正确方法去执行,用来保存这些类型信息的类是Class类。Class类封装一个对象和接口运行时的状态,当装载类时,Class类型的对象自动创建。注意:一个类只有一个Class对象。即把Class对象和类的实例区分开。
三、Class原理
我们都知道所有的java类都是继承了object这个类,在object这个类中有一个方法:getclass().这个方法是用来取得该类已经被实例化了的对象的该类的引用,这个引用指向的是Class类的对象。我们自己无法生成一个Class对象(构造函数为private),而 这个Class类的对象是在当各类被调入时,由 Java 虚拟机自动创建 Class 对象,或通过类装载器中的 defineClass 方法生成。我们生成的对象都会有个字段记录该对象所属类在CLass类的对象的所在位置。
四、利用Class对象生成目标类的实例
利用Class类的对象来生成目标类的实例,获取一个Class类的对象后,可以用 newInstance() 函数来生成目标类的一个实例。然而,该函数并不能直接生成目标类的实例,只能生成object类的实例;使用泛化Class引用生成带类型的目标实例。
例如:Class<shapes> obj=shapes.class; shapes newShape=obj.newInstance();
Class<? extends Number> obj=int.class; obj=Number.class; obj=double.class;
Class<?> obj=int.class; obj=double.class; obj=shapes.class;
五、注解(Annotation)
注解的作用:可以对程序进行解释说明;可以被其他程序读取。
@SuppressWarnings,关闭不当编译器警告信息。
1、注解(Annotation)相当于一种标记,在程序中加入注解就等于为程序打上某种标记,标记可以加在包、类,属性、方法,方法的参数以及局部变量上。
2、注解定义
注解通过 @interface 关键字进行定义。
public @interface TestAnnotation { String msg(); //成员变量定义,msg是属性名,String是属性值的类型。public String msg() default "gogo";
}
注解中属性可以有默认值,默认值需要用 default 关键值指定。
注解中只有一个属性时,可以省略value=,即@Check("hi")
3、元注解
元注解是可以注解到注解上的注解,或者说元注解是一种基本注解,但是它能够应用到其它的注解上面。(注意:注解只有成员变量,没有方法。注解的成员变量在注解的定义中以“无形参的方法”形式来声明,其方法名定义了该成员变量的名字,其返回值定义了该成员变量的类型。)
元标签有 @Retention、@Documented、@Target、@Inherited、@Repeatable 5 种。其中@Target、@Retention比较常用。
4、@Target
Target 是目标的意思,@Target 指定了注解运用的地方,即使用范围。比如可用在类、接口、方法、变量等上面。使用方法:@Target(value=ElementType.TYPE)
5、@Retention
Retention 的英文意为保留期的意思。当 @Retention 应用到一个注解上的时候,它解释说明了这个注解的的存活时间。取值:RetentionPolicy.RUNTIME 注解可以保留到程序运行的时候,它会被加载进入到 JVM 中,所以在程序运行时可以获取到它们。
(十一)设计模式
一、设计模式分类
创建型模式(Creational Patterns)、结构型模式(Structural Patterns)、行为型模式(Behavioral Patterns)、J2EE 设计模式。
二、创建型模式
这些设计模式提供了一种在创建对象的同时隐藏创建逻辑的方式,而不是使用 new 运算符直接实例化对象。这使得程序在判断针对某个给定实例需要创建哪些对象时更加灵活。
- 工厂模式:工厂类中生产一类产品,将该类型产品抽象为接口,通过具体的实现类来产生具体产品对象,通过工厂类中的产品方法获取所需产品。
- 抽象工厂模式:工厂中生产各种类型的产品,将工厂抽象为抽象类,含有生产各种类型产品的方法;各种类型产品抽象为接口,通过具体实现类来生产具体产品;通过具体工厂类来实现工厂抽象类,获取具体产品。
- 单例模式:保证一个类仅有一个实例,并提供一个访问它的全局访问点。主要有三种模式:懒汉模式和饿汉模式、静态内部类,懒汉模式:需要的时候才会创建该类的一个实例(要注意线程同步问题);饿汉模式:程序加载时就会创建该类的一个实例。通过将构造方法私有化,利用static关键字来修饰对象的变量引用;静态内部类的方法:类加载器加载类是线程安全的,这样就结合了以上几种的方式的优点:
public class Singleton {
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
private Singleton (){}
public static final Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
}(注意:反射和序列化可以对单例模式进行破解,通过抛出异常和重写readResolve()方法解决。)
三、结构型模式
这些设计模式关注类和对象的组合。继承的概念被用来组合接口和定义组合对象获得新功能的方式。
1、
四、行为型模式
这些设计模式特别关注对象之间的通信。
五、J2EE设计模式
这些设计模式特别关注表示层。
六、设计模式原则(目的:就是为了软件容易扩展和易于维护)
1、单一职责原则
单一职责原则是实现高内聚、低耦合的指导方针,它是最简单但又最难运用的原则,需要设计人员发现类的不同职责并将其分离,而发现类的多重职责需要设计人员具有较强的分析设计能力和相关实践经验。一个类只负责一个功能领域中的相应职责。
2、开闭原则
软件实体对扩展开放,对修改关闭。软件实体可以指一个软件模块、一个由多个类组成的局部结构或一个独立的类。面向对象编程语言中都提供了接口、抽象类等机制,可以通过它们定义系统的抽象层,再通过具体类来进行扩展。如果需要修改系统的行为,无须对抽象层进行任何改动,只需要增加新的具体类来实现新的业务功能即可,实现在不修改已有代码的基础上扩展系统的功能,达到开闭原则的要求。(通过接口和抽象类来实现)。开闭原则是目标,里氏代换原则是基础,依赖倒转原则是手段。
3、里氏替换原则
所有引用父类(基类)的地方都可以使用其子类的对象。(多态的应用,父类引用指向子类对象)。
4、依赖倒置原则
在程序代码中传递参数时或在关联关系中,尽量引用层次高的抽象层类,即使用接口和抽象类进行变量类型声明、参数类型声明、方法返回类型声明,以及数据类型的转换等,而不要用具体类来做这些事情。为了确保该原则的应用,一个具体类应当只实现接口或抽象类中声明过的方法,而不要给出多余的方法,否则将无法调用到在子类中增加的新方法。(父类引用指向子类对象,子类对象需要向上转型,子类对象特有的方法不能被调用)。
5、接口隔离原则
当一个接口太大时,我们需要将它分割成一些更细小的接口,使用该接口的客户端仅需知道与之相关的方法即可。每一个接口应该承担一种相对独立的角色,不干不该干的事,该干的事都要干。(建立多个专门的接口,而不是使用单一的总接口)
6、迪米特法则
应该尽量减少对象之间的交互,如果两个对象之间不必彼此直接通信,那么这两个对象就不应当发生任何直接的相互作用,如果其中的一个对象需要调用另一个对象的某一个方法的话,可以通过第三者转发这个调用。简言之,就是通过引入一个合理的第三者来降低现有对象之间的耦合度。
(十二)正则表达式
一、正则表达式工具软件:RegexBuddy
二、普通字符:字母、数字、下划线、汉字、以及没有特殊定义的标点符号都是普通字符。
三、标准字符集合:能够与多种字符匹配的表达式。
"\d": 匹配数字; "\w":匹配字母,数字,下划线; "\s":匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]; ".":匹配除换行符 \n 之外的任何单字符。
四、自定义字符集合
【】方括号匹配方式,能够匹配方括号中任意一个字符。其中方括号中^表示取反。
五、量词:用来修饰匹配的次数。
"*"(贪婪) 重复零次或更多;"+"(懒惰) 重复一次或更多次; "?"(占有) 重复零次或一次; "{n}" 重复n次; "{n,m}" 重复n到m次;"{n,}" 重复n次或更多次。
六、字符边界
"^" :^会匹配行或者字符串的起始位置,有时还会匹配整个文档的起始位置。
"$" :$会匹配行或字符串的结尾
"\b" :不会消耗任何字符只匹配一个位置,表示一个单词的边界。
(十三)JDBC数据库操作
JDBC是为java开发者使用数据库提高的统一的编程接口。各数据库厂商提供驱动类。
一、mysql的客户端软件:Navicat(绿色版解压即可使用:免安装)
Navicat与数据库进行连接,连接名可以任意起,一般是见名知意。
二、命令行操作
1、配置环境变量:将mysql的bin目录配置到path中。
2、登录数据库:mysql -hlocalhost -uroot -proot 退出数据库:exit
显示表的结构:describe 表名;
三、JDBC访问数据库
1、Driver接口
Driver接口由数据库厂家提供,作为java开发人员,只需要使用Driver接口就可以了。在编程中要连接数据库,必须先装载特定厂商的数据库驱动程序,不同的数据库有不同的装载方法。如:
装载MySql驱动:Class.forName("com.mysql.jdbc.Driver");
装载Oracle驱动:Class.forName("oracle.jdbc.driver.OracleDriver");
2、Connection接口
Connection与特定数据库的连接(会话),在连接上下文中执行sql语句并返回结果。DriverManager.getConnection(url, user, password)方法建立在JDBC URL中定义的数据库Connection连接上。
连接MySql数据库:Connection conn = DriverManager.getConnection("jdbc:mysql://host:port/database", "user", "password");
连接Oracle数据库:Connection conn = DriverManager.getConnection("jdbc:oracle:thin:@host:port:database", "user", "password");
- createStatement():创建向数据库发送sql的statement对象。
- prepareStatement(sql) :创建向数据库发送预编译sql的PrepareSatement对象。
- prepareCall(sql):创建执行存储过程的callableStatement对象。
- setAutoCommit(boolean autoCommit):设置事务是否自动提交。
- commit() :在链接上提交事务。
- rollback() :在此链接上回滚事务。
3、Statement接口
用于执行静态SQL语句并返回它所生成结果的对象。
-
- Statement:由createStatement创建,用于发送简单的SQL语句(不带参数)。(会产生sql注入问题)
- PreparedStatement :继承自Statement接口,由preparedStatement创建,用于发送含有一个或多个参数的SQL语句。PreparedStatement对象比Statement对象的效率更高,并且可以防止SQL注入,所以我们一般都使用PreparedStatement。
- CallableStatement:继承自PreparedStatement接口,由方法prepareCall创建,用于调用存储过程。
常用Statement方法:
-
- execute(String sql):运行语句,返回是否有结果集
- executeQuery(String sql):运行select语句,返回ResultSet结果集。
- executeUpdate(String sql):运行insert/update/delete操作,返回更新的行数。
- addBatch(String sql) :把多条sql语句放到一个批处理中。
- executeBatch():向数据库发送一批sql语句执行。
4、ResultSet接口
ResultSet提供检索不同类型字段的方法,常用的有:
-
- getString(int index)、getString(String columnName):获得在数据库里是varchar、char等类型的数据对象。
- getFloat(int index)、getFloat(String columnName):获得在数据库里是Float类型的数据对象。
- getDate(int index)、getDate(String columnName):获得在数据库里是Date类型的数据。
- getBoolean(int index)、getBoolean(String columnName):获得在数据库里是Boolean类型的数据。
- getObject(int index)、getObject(String columnName):获取在数据库里任意类型的数据。
ResultSet还提供了对结果集进行滚动的方法:
-
- next():移动到下一行
- Previous():移动到前一行
- absolute(int row):移动到指定行
- beforeFirst():移动resultSet的最前面。
- afterLast() :移动到resultSet的最后面。
使用后依次关闭对象及连接:ResultSet → Statement → Connection
(十四)数据结构和算法
一、数据结构
数据结构包括逻辑结构+存储结构+元素之间的运算。
二、算法
算法是解决问题的过程,即一系列解决问题的清晰指令。
1、算法特征:
有穷性:算法必须能在执行有限个步骤之后终止;
确切性:算法的每一步骤必须有确切的定义;
可行性:每个计算步都可以在有限时间内完成;
输入项:一个算法有0个或多个输入,0个输入是指算法本身定出了初始条件;
输出项:没有输出的算法是毫无意义的;
2、算法评定
一个算法的评价主要从时间复杂度和空间复杂度来考虑。时间复杂度和空间复杂度二者相互影响,一般时间快了,就会占用过多的空间;空间节省了,就会浪费过多的时间。
3、时间复杂度
时间复杂度是指执行算法所需要的计算工作量,时间复杂度常用大O符号(朗道符号)即不包括这个函数的低阶项和首项系数。T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
在pascal中比较容易理解,容易计算的方法是:看看有几重for循环,只有一重则时间复杂度为O(n),二重则为O(n^2),依此类推,如果有二分则为O(logn),二分例如快速幂、二分查找,如果一个for循环套一个二分,那么时间复杂度则为O(nlogn)。
4、空间复杂度
算法的空间复杂度S(n)定义为该算法所耗费的存储空间,记做S(n)=O(f(n))。
三、常见算法
1、递推法:思想是把一个复杂的庞大的计算过程转化为简单过程的多次重复;
2、递归法:通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解;
3、穷举法:对于要解决的问题,列举出它的所有可能的情况,逐个判断有哪些是符合问题所要求的条件,从而得到问题的解。
4、贪心算法:一步一步地进行,常以当前情况为基础根据某个优化测度作最优选择,而不考虑各种可能的整体情况,它省去了为找最优解要穷尽所有可能而必须耗费的大量时间,它采用自顶向下,以迭代的方法做出相继的贪心选择,每做一次贪心选择就将所求问题简化为一个规模更小的子问题, 通过每一步贪心选择,可得到问题的一个最优解;
5、分治算法:把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题……直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。
6、动态规划算法:将原问题分解为相似的子问题,在求解的过程中通过子问题的解求出原问题的解。
7、迭代法:一种不断用变量的旧值递推新值的过程;
8、回溯算法:走不通就退回再走的算法。
(十五)java虚拟机
Java虚拟机在执行字节码时,把字节码解释成具体平台上的机器指令执行。这就是Java的能够“一次编译,到处运行”的原因。
1、虚拟机的核心:垃圾回收机制(GC)
GC的基本原理:将内存中不再被引用的对象进行回收,GC中用于回收的方法称为收集器。垃圾:不再被引用的对象。
2、判断一块内存空间是否符合回收标准:
(1)对象赋予了空值,且之后再未调用(obj = null;)
(2)对象赋予了新值,即重新分配了内存空间(obj = new Obj();)
内存泄漏:程序中保留着对永远不再使用的对象的引用。因此这些对象不回被GC回收,却一直占用内存空间却毫无用处。即:1)对象是可达的;2)对象是无用的。满足这两个条件即可判定为内存泄漏。内存泄露的原因:1)全局集合;2)缓存;3)ClassLoader
3、类加载器
加载过程中会先检查类是否被已加载,检查顺序是自底向上,从Custom ClassLoader到BootStrap ClassLoader逐层检查,只要某个classloader已加载就视为已加载此类,保证此类只所有ClassLoader加载一次。而加载的顺序是自顶向下,也就是由上层来逐层尝试加载此类。
4、双亲委派机制
JVM在加载类时默认采用的是双亲委派机制。通俗的讲,就是某个特定的类加载器在接到加载类的请求时,首先将加载任务委托给父类加载器,依次递归。如果父类加载器可以完成类加载任务,就成功返回;只有父类加载器无法完成此加载任务时,才自己去加载。
作用:1)避免重复加载;2)更安全。如果不是双亲委派,那么用户在自己的classpath编写了一个java.lang.Object的类,那就无法保证Object的唯一性。所以使用双亲委派,即使自己编写了,但是永远都不会被加载运行。
(十六)xml技术解析
1、xml可扩展标记语言(eXtensible Markup Language)。被设计用来传输和存储数据。
一、XML的解析方法
XML的解析方式分为四种:1、DOM解析;2、SAX解析;3、JDOM解析;4、DOM4J解析。其中前两种属于基础方法,是官方提供的平台无关的解析方式;后两种属于扩展方法,它们是在基础的方法上扩展出来的,只适用于java平台。
二、DOM解析
DOM的全称是Document Object Model,也即文档对象模型。在应用程序中,基于DOM的XML分析器将一个XML文档转换成一个对象模型的集合(通常称DOM树),应用程序正是通过对这个对象模型的操作,来实现对XML文档数据的操作。
由于DOM“一切都是节点(everything-is-a-node)”,XML树的每个 Document、Element、Text 、Attr和Comment都是 DOM Node(节点)。(注意:元素中的文本也是节点)
DOM 是这样规定的:
- 整个文档是一个文档节点
- 每个 XML 标签是一个元素节点
- 包含在 XML 元素中的文本是文本节点
- 每一个 XML 属性是一个属性节点
- 注释属于注释节点
优点:
1、形成了树结构,有助于更好的理解、掌握,且代码容易编写。
2、解析过程中,树结构保存在内存中,方便修改。
缺点:
1、由于文件是一次性读取,所以对内存的耗费比较大。
2、如果XML文件比较大,容易影响解析性能且可能会造成内存溢出。
1、Node接口
在DOM中,所有节点类型都继承自Node类,它代表在DOM树中的一个节点。Node接口定义了一些用于处理子节点的方法,但是并不是所有的节点有子节点,比如Text节点并没有子节点,因而向Text节点添加子节点(appendChild)会抛出DOMException。Node接口提供了getNodeName()、getNodeValue()、getAttributes()三个方法,以方便应用程序获取这些信息,而不需要每次都转换成不同子类以获取这些信息。但是并不是所有的节点类型都有NodeName、NodeValue、Attributes信息,因而对那些不存在这些信息的节点可以返回null。注意:getChildNodes()获取子节点数,不包含孙子节点数,只获取子节点数。XML中元素之间的空格会被当做文本节点来处理。
2、Document接口
Document是DOM树的根节点,由于其他节点类型都要基于Document而存在,因而Document接口还提供了创建其他节点的工厂方法。
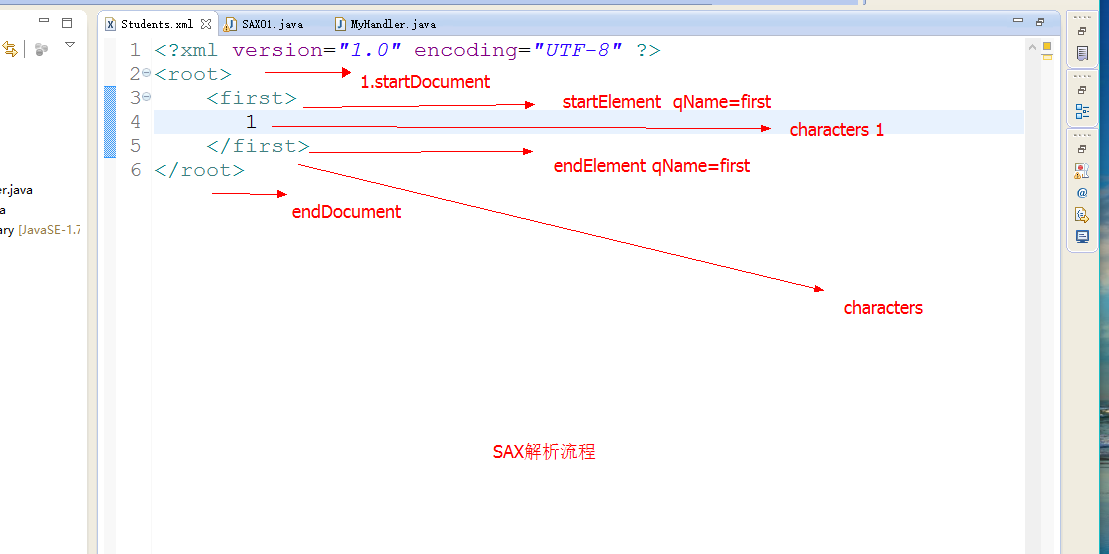
三、sax解析(常用)
1、读取顺序:(从根元素开始读取,需要对元素进行判断,是否为所需元素)。把元素看成对象进行处理,子元素可看成属性进行处理。
SAX的全称是Simple APIs for XML,也即XML简单应用程序接口。与DOM不同,SAX提供的访问模式是一种顺序模式,这是一种快速读写XML数据的方式。当使用SAX分析器对XML文档进行分析时,会触发一系列事件,并激活相应的事件处理函数,应用程序通过这些事件处理函数实现对XML文档的访问,因而SAX接口也被称作事件驱动接口。
优点:
1、采用事件驱动模式,对内存耗费比较小。
2、适用于只处理XML文件中的数据时。
缺点:
1、编码比较麻烦。
2、很难同时访问XML文件中的多处不同数据。
1、原理:通过parse(file,listener)函数用一个listener对xml文件进行查找,按顺序读取文档,遍历每个标签,当发现目标标签时,读取标签的属性、结点值等信息并返回。
2、操作步骤:
1:创建解析工厂:SAXParserFactory factory = SAXParserFactory.newInstance();
2:由工厂创建解析器:SAXParser parser = factory.newSAXParser();
3:通过解析器的parse()方法,对指定xml文档以指定handler之类进行解析查询:parser.parse(xmlFile, new MySaxListener());
我们要继承DefaultHandler类,定义相应的查询操作类:
1:重写父类中的文档开始方法、文档结束方法,定义开始、结束遍历xml文档时的操作:
void startDocument()
接收文档开始的通知。
void endDocument()
接收文档结束的通知。
2:重写父类的标签开始方法、标签结束方法,定义遍历到一个开始、结束标签时的操作:(从根元素开始扫描)
void startElement(String uri, String localName, String qName, Attributes attributes) //参数qName是标签名、attributes是属性列表
接收元素开始的通知。
void endElement(String uri, String localName, String qName)
接收元素结束的通知。
3:重写characters(char[] ch, int start, int length)方法:
// 对事件发生时,元素的字符怎么处理 (扫描元素中文本节点的内容)
public void characters(char[] ch, int start, int length) throws SAXException {
//参数ch是当上述4中事件随便一个发生时,对应的元素的值,值在ch中start开始,length长。从头到尾遍历整个xml文档时,每个标签的值依次被存入ch中。 }
也就是说,通过SAX解析xml文档是没有dom对象出现的,所以不会有node,不会有getNodeName()、getNodeValue()获取结点名、值。总结:SAX解析XML文档的结点名是通过事件函数的参数qName获取的,属性是通过参数attributes的getValue("属性名")获取的,结点值是通过当前事件函数发生时,characters(char[] ch, int start, int length)方法中的内容获取的。
二、常见节点
元素:元素是 XML 的基本构造模块。通常,元素拥有子元素、文本节点,或两者的组合。元素节点也是能够拥有属性的唯一节点类型。
文本:文本节点就是名副其实的文本。它可以由更多信息组成,也可以只包含空白。(文本总是存储在文本节点中)。
四、JSON学习
JSON是一种取代XML的数据结构,和xml相比,它更小巧但描述能力却不差,由于它的小巧所以网络传输数据将减少更多流量从而加快速度。JSON本质是具有特定格式的字符串。
(1)遇到{}就写一个类
(2)遇到[]就写一个集合一般写ArrayLsit
1、json介绍
JSON的全称是”JavaScript Object Notation”,意思是JavaScript对象表示法,它是一种基于文本,独立于语言的轻量级数据交换格式。XML也是一种数据交换格式,为什么没有选择XML呢?因为XML虽然可以作为跨平台的数据交换格式,但是在JS(JavaScript的简写)中处理XML非常不方便,同时XML标记比数据多,增加了交换产生的流量,而JSON没有附加的任何标记,在JS中可作为对象处理,所以我们更倾向于选择JSON来交换数据。
JSON 通常用于与服务端交换数据,在接收服务器数据时一般是字符串,因此,前端网页要使用从服务器响应的数据时,要将字符串转换为JavaScript对象才可以。
2、json对象和数组
json对象结构以”{”大括号开始,以”}”大括号结束。中间部分由0或多个以”,”分隔的”key(关键字)/value(值)”对构成,关键字和值之间以”:”分隔,其中key 必须是字符串,value 可以是合法的 JSON 数据类型(字符串, 数字, 对象, 数组, 布尔值或 null)。
Json数组结构以”[json对象,json对象]”结束。中间由0或多个以”,”分隔的值列表组成。
3、json解析技术
Gson解析技术:Gson是目前功能最全的Json解析神器,Gson当初是为因应Google公司内部需求而由Google自行研发而来,但自从在2008年五月公开发布第一版后已被许多公司或用户应用。Gson的应用主要为toJson与fromJson两个转换函数,无依赖,不需要例外额外的jar,能够直接跑在JDK上。而在使用这种对象转换之前需先创建好对象的类型以及其成员才能成功的将JSON字符串成功转换成相对应的对象。类里面只要有get和set方法,Gson完全可以将复杂类型的json到bean或bean到json的转换,是JSON解析的神器。Gson在功能上面无可挑剔,但是性能上面比FastJson有所差距。
1、Gson框架技术
特点:编码简洁,Google官方推荐
数据之间转换:
(1)将json格式的字符串{}转换为java对象
API:
<T> T fromJson(String json,Class<T> classofT)
注意:要求Json对象中的key的名称与java对象对应的类中的属性名要相同
步骤:
(a)将Gson的jar包导入的项目中
(b)创建Gson对象
Gson gson = new Gson();
(c)通过创建的Gson对象调用fromJson()方法,返回该Json数据对应的java对象
DataInfo dataInfo = gson.fromJson(json,DataInfo,class);
(2)将json格式的字符串[]转换为java对象的List
API:
fromJson(json,Type typeofT);
步骤:
(a)将Gson的jar包导入的项目中
(b)创建Gson对象
Gson gson = new Gson();
(c)通过创建的Gson对象调用fromJson()方法,返回该Json数据对应的java集合
List<DataInfo> infos = gson.fromJson(josn,new TypeToken<List<DataInfo>>(){}.getType());
(3)将java对象转换为json字符串{}
API:
String toJson(Object src);
步骤:
(a)将Gson的jar包导入的项目中
(b)创建Gson对象
Gson gson = new Gson();
(c)通过创建的Gson对象调用toJson()方法,返回该Json数据
DataInfo info = new DataInfo(1,”apple”,250.0,”eggs”);
String json = gson.toJson(info);
(4)将java对象的List转换为json字符串[]
API:
String toJson(Object src);
步骤:
(a)将Gson的jar包导入的项目中
(b)创建Gson对象
Gson gson = new Gson();
(c)通过创建的Gson对象调用toJson()方法,返回该Json数据
List<DataInfo> infoList = new ArrayList<>();
String json = gson.toJson(infoList);
fastJson解析技术:Gson是目前功能最全的Json解析神器,Gson当初是为因应Google公司内部需求而由Google自行研发而来,但自从在2008年五月公开发布第一版后已被许多公司或用户应用。Gson的应用主要为toJson与fromJson两个转换函数,无依赖,不需要例外额外的jar,能够直接跑在JDK上。
2、FastJson技术
特点:FastJson是一个java语言编写的高性能功能完善的Json库,它采用一种“假定有序快速匹配”的算法,把Json解析的性能提升到极致,是目前java语言中最快的Josn库,导入其jar包即可使用。
数据间转换
(1)将json格式的字符串{}转换为java对象
API:
<T> T parseObject(String json,Class<T> classOfT);
步骤:
(a)将FastJson的jar包导入的项目中
(b)JSON调用parseObject()方法,获取转换后的java对象
DataInfo dataInfo = JSON.parseObject(json,DataInfo.class);
(2)将json格式的字符串[]转换为java对象的List
API:
List<T> parseArray(String json,Class<T> classOfT);
步骤:
(a)将FastJson的jar包导入的项目中
(b)JSON调用parseArray()方法,获取转换后的java集合
List<DataInfo> infoList = new ArrayList(json,DataInfo.class);
(3)将java对象转换为json字符串{}
API:
String toJSONString(Object object);
步骤:
(a)将FastJson的jar包导入的项目中
(b)JSON调用toJSONString()方法,获取转换后的json数据
DataInfo dataInfo = new DataInfo(1,”apple”,2,”eggs”);
String json = JSON.toJSONString(dataInfo);
(4)将java对象的List转换为json字符串[]
API:
String toJSONString(Object object);
步骤:
(a)将FastJson的jar包导入的项目中
(b)JSON调用toJSONString()方法,获取转换后的json数据
List<DataInfo> infoList = new ArrayList();
DataInfo zhangsan = new DataInfo(1,zhangsan);
DataInfo lisi = new DataInfo(2,lisi);
infoList.add(zhangsan);
infoList.add( lisi )
String json = JSON.toString(infoList);
(十七)异常机制
- 常见的异常:用户输出错误;设备问题;硬件问题;物理限制磁盘满了、程序问题等。
2、java是采用面向对象的方式来处理异常。处理过程:
抛出异常:在执行一个方法时,如果发生异常,则这个方法生成代表该异常的一个对象,停止当前执行路径,并把异常对象提交给JRE。
捕获异常:JRE得到该异常后,寻找相应的代码来处理该异常。JRE在方法的调用栈中查找,从生成异常的方法开始回溯,直到找到相应的异常处理代码为止。
3、异常分为检查性异常和非检查性异常。
检查性异常:表示程序在运行前,编译器会对程序进行检查,是否对异常进行了处理。(此类异常通常是程序可预见的致命错误或问题,必须处理)。当函数中存在抛出检查型异常的操作时该函数的函数声明中必须包含throws语句。调用改函数的函数也必须对该异常进行处理,如不进行处理则必须在调用函数上声明throws语句。
非检查性异常:在Java中所有RuntimeException的派生类都是非检查型异常,与检查型异常对比,非检查型异常可以不在函数声明中添加throws语句,调用函数上也不需要强制处理。(此类异常是程序无法预见的问题或错误,通常是用户引起的问题或错误)。对于RuntimeException的子类最好也使用异常处理机制。虽然RuntimeException的异常可以不使用try...catch进行处理,但是如果一旦发生异常,则肯定会导致程序中断执行,所以,为了保证程序再出错后依然可以执行,在开发代码时最好使用try...catch的异常处理机制进行处理。(常见的非检查性异常有空指针异常、类型转换异常、数组越界异常)。
一、捕获处理异常
使用 try 和 catch 关键字可以捕获异常。try/catch 代码块放在异常可能发生的地方。使用格式:
try{ // 程序代码 }catch(异常类型1 异常的变量名1){ // 程序代码 }catch(异常类型2 异常的变量名2){ // 程序代码 }finally{ // 程序代码 }
- 一个try语句必须带有至少一个catch语句或一个finally语句;当异常处理的代码执行结束以后,是不会回到try语句去执行尚未执行的代码。
- Catch语句:用于处理可能产生的不同类型的异常对象。常用的方法:getMessage()方法:只显示产生异常的原因,不显示类名;printStackTrace():用来跟踪异常事件发生时堆栈的内容。这些方法都继承自Throwable类。注意:catch捕获的异常对象若存在集成关系,子类在上,父类在下。(若父类在上,当发生子类异常时,直接执行父类异常,就不会执行子类异常了)。
- finally语句:无论是否发生异常,finally 代码块中的代码总会被执行。一般用于清理类型等收尾工作。关闭资源等,比如就有可能使用资源使用没有关闭,导致服务器挂掉。
- 注意:不建议在finally中使用return关键字,如果使用会覆盖try/catch中的return的返回值。
二、处理异常使用:throw和throws关键字
1、throws:用来声明一个方法可能产生的所有异常,不做任何处理而是将异常往上传,谁调用我,谁来出来。可以跟多个异常类名,用逗号隔开。任何方法都是可以使用throws,抽象方法也可以。
2、throw:手动抛出异常对象,用来抛出一个具体的异常类型对象。对于手动抛出的异常对象,要么使用try/catch进行处理或者使用throws向外抛出。 用在方法体内,跟的是异常对象名。
三、可以自定义异常
1、自定义异常必须继承异常类:写一个检查性异常类,则需要继承 Exception 类;一个运行时异常类,那么需要继承 RuntimeException 类。
四、数据库开发
(一)oracle和sql语言
(二)mysql的使用
(三)powerdesigner的使用(类似的工具还有Rose)
1、利用PDM产生一个数据库:Database-> Generate Database。
2、利用数据库产生一个PDM:File->Reverse Engineer->Database
3、实体(Entity),也称为实例,对应类的一个具体对象。
4、实体集(Entity Set)是具体相同类型及相同性质实体的集合。对应类的集合。
5、实体类型(Entity Type)是实体集中每个实体所具有的共同性质的集合,对应类。
6、标识符(Identifier):实体类型中的每个实体包含唯一标识它的一个或一组属性。对应表中的主键或者外键。
7、数据项(Data Item)是信息存储的最小单位,它可以附加在实体上作为实体的属性。
8、Add a DataItem 与 Reuse a DataItem的区别在于:Reuse a DataItem情况下,只引用不新增,就是引用那些已经存在的数据项,作为新实体的数据项。
一、标定联系(依赖关系:主从表关系)
两个实体集之间发生联系,其中一个实体类型的标识符进入另一个实体类型并与该实体类型中的标识符共同组成其标识符时,这种联系则称为标定联系。在标定联系中,一个实体集中的全部实例完全依赖于另个实体集中的实例,在这种依赖联系中一个实体必须至少有一个标识符,而另一个实体却可以没有自己的标识符。
二、非标定联系(每个实体都必须有标识符即主键)
非标定联系中,一个实体集中的部分实例依赖于另一个实例集中的实例,在这种依赖联系中,每个实体必须至少有一个标识符。即一个Entity型的Identifier进入另一个Entity型后充当其非Identifier时,这种关联称为非标定关联
三、mandatory
联系对应的那两个实体型的实体实例的 个数可不可能为零。
四、dependent
从表要依赖于主表。对于依赖型联系,不存在多对多联系,在这个联系中,必须有一个作为主体的实体型。一个dependent联系的从实体可以没有自己的identifier。
五、dominant
它仅作用于一对一联系,并指明这种联系中的主从表关系。在A,B两个实体型的联系中,如果A-->B被指定为 dominant,那么A为这个一对一联系的主表,B为从表,并且在以后生成的PDM中会产生一个引用(如果不指定dominant属性的话会产生两个引 用)。比如老师和班级之间的联系,因为每个班级都有一个老师做班主任,每个老师也最多只能做一个班级的班主任,所以是一个一对一关系。同时,我们可以将老 师作为主表,用老师的工号来唯一确定一个班主任联系。
六、Cardinality(基数)
基数是用实体间实例的数值对应关系表示,它从父实体的角度描述了一对实体间的数量维度,换句话说,基数中的数字是描述父实体在一个子表中可能出现的次数范围。即一个字表中拥有或属于多少个父实体。
七、递归联系
递归联系是实体集内部实例之间的一种联系,同一实体类型中不同实体集之间的联系也称为递归联系。例如:在“职工”实体集中存在很多的职工,这些职工之间必须存在一种领导与被领导的关系。又如“学生”实体信中的实体包含“班长”子实体集与“普通学生”子实体集,这两个子实体集之间的联系就是一种递归联系。
八、一对一、一对多、多对多关系设计表
1、一对一关系:一般需要设计两个表,通过主外键关联实现;当然做项目时为了省空间,通常只建一个表,如果要实现一对一的查询,可以建两个视图。
2、一对多关系:至少两个表,一般在多的一方引用外键。
3、多对多关系:至少三张表,需要建立关系表,来维护两个类型之间的关系。
(四)JDBC数据库连接
一、JDBC(Java Data Base Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。
其中,安装好数据库之后,我们的应用程序也是不能直接使用数据库的,必须要通过相应的数据库驱动程序,通过驱动程序去和数据库打交道。
二、Driver接口
Driver接口由数据库厂家提供,作为java开发人员,只需要使用Driver接口就可以了。在编程中要连接数据库,必须先装载特定厂商的数据库驱动程序,不同的数据库有不同的装载方法。如:
装载MySql驱动:Class.forName("com.mysql.jdbc.Driver");
装载Oracle驱动:Class.forName("oracle.jdbc.driver.OracleDriver");
三、Connection接口
Connection与特定数据库的连接(会话),在连接上下文中执行sql语句并返回结果。DriverManager.getConnection(url, user, password)方法建立在JDBC URL中定义的数据库Connection连接上。
连接MySql数据库:Connection conn = DriverManager.getConnection("jdbc:mysql://host:port/database", "user", "password");
连接Oracle数据库:Connection conn = DriverManager.getConnection("jdbc:oracle:thin:@host:port:database", "user", "password");
连接SqlServer数据库:Connection conn = DriverManager.getConnection("jdbc:microsoft:sqlserver://host:port; DatabaseName=database", "user", "password");
常用方法:
-
- createStatement():创建向数据库发送sql的statement对象。
- prepareStatement(sql) :创建向数据库发送预编译sql的PrepareSatement对象。
- prepareCall(sql):创建执行存储过程的callableStatement对象。
- setAutoCommit(boolean autoCommit):设置事务是否自动提交。
- commit() :在链接上提交事务。
- rollback() :在此链接上回滚事务。
四、Statement接口
用于执行静态SQL语句并返回它所生成结果的对象。
三种Statement类:
-
- Statement:由createStatement创建,用于发送简单的SQL语句(不带参数)。
- PreparedStatement :继承自Statement接口,由preparedStatement创建,用于发送含有一个或多个参数的SQL语句。PreparedStatement对象比Statement对象的效率更高,并且可以防止SQL注入,所以我们一般都使用PreparedStatement。
- CallableStatement:继承自PreparedStatement接口,由方法prepareCall创建,用于调用存储过程。
常用Statement方法:
-
- execute(String sql):运行语句,返回是否有结果集
- executeQuery(String sql):运行select语句,返回ResultSet结果集。
- executeUpdate(String sql):运行insert/update/delete操作,返回更新的行数。
- addBatch(String sql) :把多条sql语句放到一个批处理中。
- executeBatch():向数据库发送一批sql语句执行。
五、ResultSet接口
ResultSet提供检索不同类型字段的方法,常用的有:
-
- getString(int index)、getString(String columnName):获得在数据库里是varchar、char等类型的数据对象。
- getFloat(int index)、getFloat(String columnName):获得在数据库里是Float类型的数据对象。
- getDate(int index)、getDate(String columnName):获得在数据库里是Date类型的数据。
- getBoolean(int index)、getBoolean(String columnName):获得在数据库里是Boolean类型的数据。
- getObject(int index)、getObject(String columnName):获取在数据库里任意类型的数据。
ResultSet还提供了对结果集进行滚动的方法:
-
- next():移动到下一行
- Previous():移动到前一行
- absolute(int row):移动到指定行
- beforeFirst():移动resultSet的最前面。
- afterLast() :移动到resultSet的最后面。
使用后依次关闭对象及连接:ResultSet → Statement → Connection
六、PreparedStatement设置sql参数
SetObject(int index,Object x);这里会用到数据类型的自动装箱。例如:setObject(1,“abc”);字符串会自动转换为String对象。这样导致运行效率会降低。原因涉及类型转换。
七、PreparedStatement中的setDate(int index,Date x)方法
setDate(int index,Date x)方法:使用运行应用程序的虚拟机的默认时区将指定参数设置为给定 java.sql.Date 值。在将此值发送到数据库时,驱动程序将它转换成一个 SQL DATE值。
Java.util.Date是java.sql.Date的父类,Java.util.Date的getTime()方法返回一个long类型。
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date date = sdf.parse("1995-5-6 10:30:00");
long lg = date.getTime(); //日期转时间戳
ps.setDate(3, new java.sql.Date(lg) );
八、date和timestamp
timestamp是DATE类型的扩展,可以精确到小数秒,java.sql.Timestamp是java.util.Date的子类。
Java.util.Date:一个包装了毫秒值的瘦包装器 (thin wrapper),它允许 JDBC 将毫秒值标识为 SQL DATE 值。毫秒值表示自 1970 年 1 月 1 日 00:00:00 GMT 以来经过的毫秒数。其中Java.sql.Date是java.util.Date的子类。
(五)mysql优化
(六)oracle深化
五、网页开发和设计
(一)html基础
(二)css基础
(三)JavaScript编程
(四)Jquery学习
一、jQuery简介
jQuery是一个JavaScript函数库。通过使用jQuery框架,能够使用户的html页动作和html内容分离,即不用再在html里面插入一堆js来调用命令了,只需定义id即可。通过id来调用。例如:JS中取对象document.getElementById(),但用jquery的话$("#id")即可。
jQuery框架本质是一个JavaScript文件。
注意事项:
1、js的全局代码区只有一个,这样就会造成同名变量的值会被覆盖;
2、使用对象封装,将代码封装到对象中,但是对象如果被覆盖,则全部失效,风险极高;
3、使用工厂模式,将代码进行封装,但是并没有解决问题;
4、将封装的函数名字去除,避免覆盖,但是函数无法调用;
5、匿名自调用,可以在页面加载的时候调用一次。但是不能重复调用,并且数据没有办法获取;
6、使用闭包解决问题:即将数据一次性挂载到window对象下。
闭包原理:使用更大作用域的变量来保存小作用域变量的值。本质:通过全局变量来保存函数内局部变量的值。
二、jQuery的使用
网页中引入jQuery框架:通过资源路径或者在线引用。
1、路径引入
<script src='文件路径'></script>
2、引入在线资源
<script src = "https://code.jquery.com/jquery-1.12.4.js"></script>
三、jQuery语法
jQuery 语法是通过选取 HTML 元素,并对选取的元素执行某些操作。
语法: $(selector).action() 其中$美元符号表示jQuery;selector(选择符)用于 定位查找HTML元素;jQuery的action()是对元素进行的操作。
四、jQuery对象
jQuery对象就是通过jQuery包装DOM对象后产生的对象。
约定:如果获取的是 jQuery 对象, 那么要在变量前面加上 $.。
1、DOM对象转化为jQuery对象
对于已经是一个DOM对象,只需要用$()把DOM对象包装起来,就可以获得一个jQuery对象,即$(DOM对象)。
2、Jquery对象转化为DOM对象
两种转换方式将一个jQuery对象转换成DOM对象:[index]和.get(index);
(1) jQuery对象是一个数组对象,可以通过[index]的方法,来得到相应的DOM对象;
(2) jQuery本身提供,通过.get(index)方法,得到相应的DOM对象。
五、jQuery选择器
基本选择器:
基本选择器是 jQuery 中最常用的选择器, 也是最简单的选择器, 它通过元素 id, class 和标签名来查找 DOM 元素(在网页中 id 只能使用一次, class 允许重复使用).1、#id用法: $(”#myDiv”); 返回值 单个元素的组成的集合说明: 这个就是直接选择html中的id=”myDiv”2、Element用法: $(”div”) 返回值 集合元素说明: element的英文翻译过来是”元素”,所以element其实就是html已经定义的标签元素,例如 div, input, a 等等.3、class 用法: $(”.myClass”) 返回值 集合元素说明: 这个标签是直接选择html代码中class=”myClass”的元素或元素组(因为在同一html页面中class是可以存在多个同样值的).4、*用法: $(”*”) 返回值 集合元素说明: 匹配所有元素,多用于结合上下文来搜索5、selector1, selector2, selectorN 用法: $(”div,span,p.myClass”) 返回值 集合元素说明: 将每一个选择器匹配到的元素合并后一起返回.你可以指定任意多个选择器, 并将匹配到的元素合并到一个结果内.其中p.myClass是表示匹配元素p class=”myClass”;
层次选择器:
如果想通过 DOM 元素之间的层次关系来获取特定元素, 例如后代元素, 子元素, 相邻元素, 兄弟元素等, 则需要使用层次选择器.1 、ancestor descendant用法: $(”form input”) ; 返回值 集合元素说明: 在给定的祖先元素下匹配所有后代元素.这个要下面讲的”parent > child”区分开.2、parent > child 用法: $(”form > input”) ; 返回值 集合元素说明: 在给定的父元素下匹配所有子元素.注意:要区分好后代元素与子元素3、prev + next用法: $(”label + input”) ; 返回值 集合元素说明: 匹配所有紧接在 prev 元素后的 next 元素4、prev ~ siblings用法: $(”form ~ input”) ; 返回值 集合元素说明: 匹配 prev 元素之后的所有 siblings 元素.注意:是匹配之后的元素,不包含该元素在内,并且siblings匹配的是和prev同辈的元素,其后辈元素不被匹配.注意: (“prev ~ div”) 选择器只能选择 “# prev ” 元素后面的同辈元素; 而 jQuery 中的方法 siblings() 与前后位置无关, 只要是同辈节点就可以选取;
过滤选择器:
过滤选择器主要是通过特定的过滤规则来筛选出所需的 DOM 元素, 该选择器都以 “:” 开头;按照不同的过滤规则, 过滤选择器可以分为基本过滤, 内容过滤, 可见性过滤, 属性过滤, 子元素过滤和表单对象属性过滤选择器;
(五)easyUI学习
一、easyUI的概念
easyUI是一个基于 jQuery 的框架,集成了各种用户界面插件,封装大量css和js,提供了创建网页所需的一切。注意,只适用于后台管理界面,不适用与前台项目页面;前端项目页面建议使用bootstrap,Bootstrap4 目前是 Bootstrap 的最新版本,是一套用于 HTML、CSS 和 JS 开发的开源工具集。
优点:处理服务器传递过来的json数据能力比较强。
二、json、easyUI的作用
JS:基于浏览器对web页面中的节点进行操作,比较麻烦
jQuery:基于浏览器简化对web页面中的节点进行操作,做到了write less do more
AJAX:基于浏览器与服务端进行局部刷新的异步通讯编程模式
JSON:简化自定义对象的创建与AJAX数据交换轻量级文本
EasyUI:快速基于现成的组件创建自已的web页面
组件:是指已经由第三方开源组织写好的,直接可以使用的功能界面,例如:form,layout,tree...
注意:我们学的都是零散的组件,项目中需要将其装配起来,方可构建完整的web页面,EasyUI只是众多前端WEB组件之一。
三、easyUI的使用规则
1、通过标签的class属性来引用easyUI组件;
2、data-options属性定义easyUI组件的效果属性值;
3、标签的每一个效果都可以使用纯标签方式和使用标签结合js方式:如果效果是静态的建议使用纯html标签方式实现;如果效果是动态的建议使用html结合js方式。
四、easyUI的使用方法
1、使用easyUI首相要导出EasyUI的CSS和Javascript文件到您的页面。
2、使用easyUI的组件:
<div id="p" class="easyui-panel" style="width:500px;height:200px;padding:10px;"
title="My Panel" data-options="iconCls:'icon-save',collapsible:true,maximizable:true">
The panel content
</div>
①想要使用什么样的组件,就要在div中用【 class="easyui-xxx" 】声明出来,例如 :要实现面板样式,需要添加 class="easyui-panel" ②组件内的效果可用 【 data-options=“属性名:属性值,···,属性名:属性值” 】属性来实现,例如:要显示保存图标且实现面板折叠功能,可在div中添加 data-options="iconCls:'icon-save',collapsible:true";
五、easyUI组件的使用格式
1、如果组件是cpt,使用组件cpt的语法:
$(“使用jQuery选择器获取对应标签”).cpt({
属性名:值,
事件:function([参数]){}
})
2、如果组件是cpt,使用组件cpt中方法的语法:
$(“使用jQuery选择器获取对应标签”).cpt(“方法名”);
$(“使用jQuery选择器获取对应标签”).cpt(“方法名”,”参数”);
其中:属性是样式;事件是与用户的交互动作;方法是要实现的功能。
六、Servlet和jsp学习
(一)servlet和tomcat
一、http协议详解
1、http简介
HTTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等),即超文本传输协议。HTTP默认端口号为80,但是你也可以改为8080或者其他端口。
2、http的作用
用于规范浏览器和服务器的数据交互的格式。
3、http的特点
简单快速;灵活(可以传输任意类型数据);
无状态:是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。
无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
4、http消息结构(请求和响应的形式类似)
请求消息包括请求行、请求头、空行和请求数据四个部分组成。
请求行:请求方法、url(服务器地址)、协议版本;
请求头:请求消息的附加信息(键值对的方式),类似邮寄填写信息;
空行:位于请求头和请求数据之间,空行是必须的;
请求数据:非必须。
5、get和post的区别
Get请求方式:请求数据连接在URL(请求地址)后,不够安全;http协议虽然没有规定请求数据的大小,但是浏览器的地址输入栏是有大小限制的,因此,get方式不能携带大量数据。
Post方式:请求数据在请求实体中进行发送,在url中看不到具体请求数据,相对安全;可以传送大量数据。
6、http的交互流程
先建立连接;客户端发送请求;服务器进行响应;关闭连接(http1.1之后不再立即关闭)。
二、服务器(tomcat)
Java代码编程的一个主要作用就是帮助我们进行数据处理。但是我们编写的代码都是一次性的,需要进行手动启动。这样就导致我们无法判断用户何时发送请求。如何解决该问题?
通过使用代码编写一个容器,该容器可以根据用户的请求来启动并运行我们编写的数据逻辑代码。该容器我们称为服务器。
1、服务器:本质也是一个程序,可以根据用户的请求实时的调用对应的逻辑代码的一个容器。服务器一启动,一般就不会停止了,用于实时响应用户请求。(实际工作中,我们选取一台计算机只运行一个服务器程序,来充当服务器。)
2、常见的服务器:tomcat、weblogic等。
3、tomcat的安装:下载解压即可用。注意:tomcat解压目录最好不要出现中文。
4、tomcat运行依赖jdk,其中启动闪退问题一般和jdk环境变量配置有关。在tomcat安装目录,在bin\startup.bat文件的第一行前面加入以下代码:
SET JAVA_HOME=(JDK目录)
SET CATALINA_HOME=(解压后的tomcat的目录)
重新启动startup.bat即可。
(二)request和response对象
(三)转发和重定向 cookie
(四)session_context对象
(五)jsp
(六)Ajax技术
(七)EL和JSTL标签库
(八)过滤器
(九)监听器
七、高级框架
(一)mybatis
(二)spring
一、spring的概念
Spring框架宗旨:不重新发明技术,让原有技术使用起来更加方便。从实际需求出发,着眼于轻便、灵巧,易于开发、测试和部署的轻量级开发框架。
二、spring的核心功能
1、IOC/DI:控制反转/依赖注入,对象的创建交给spring容器而不是手动创建,常用setter注入。
2、AOP:面向切面编程,在方法前中后添加功能。
3、声明式事务:TransactionManager,事务是执行一组命令,要么都成功,要么都失败。
spring事务的本质就是对数据库事务的支持,没有数据库的事务支持,spring是无法完成事务的。
对于纯jdbc操作数据库,是借助java.sql.Connection对象完成对事务的提交,使用事务如下:Connecton con = DriverManager.getConnection();con.setAutoCommit(false); //取消自动提交功能//执行crud 操作con.commint(); //crud操作成功,提交事务或者回滚事务 con.rollback(); //一旦一个命令出错,所有操作回滚
声明式事务管理建立在AOP之上的。其本质是对方法前后进行拦截,然后在目标方法开始之前创建或者加入一个事务,在执行完目标方法之后根据执行情况提交或者回滚事务。声明式事务最大的优点就是不需要通过编程的方式管理事务,这样就不需要在业务逻辑代码中掺杂事务管理的代码,只需在配置文件中做相关的事务规则声明(或通过基于@Transactional注解的方式),便可以将事务规则应用到业务逻辑中。注意:和编程式事务相比,声明式事务唯一不足地方是,后者的最细粒度只能作用到方法级别,无法做到像编程式事务那样可以作用到代码块级别。但是即便有这样的需求,也存在很多变通的方法,比如,可以将需要进行事务管理的代码块独立为方法等等。
4、事务并发产生的问题
脏读:一个事务读到另一个事务未提交的更新数据。 不可重复读:一个事务两次读同一行数据,可是这两次读到的数据不一样。 幻读:一个事务执行两次查询,但第二次查询比第一次查询多出了一些数据行。
隔离级别越高,意味着数据库事务并发执行性能越差,能处理的操作就越少。
5、oracle数据库通过锁机制实现事务
锁定是数据库确保数据一致性和完整性的重要机制。
6、微服务
微服务的目标是充分分解应用程序,以便于方便应用程序开发和部署。
(三)spring mvc
框架的目的就是帮助我们简化开发,Spring Web MVC也是要简化我们日常Web开发的。
前端控制器是DispatcherServlet;应用控制器其实拆为处理器映射器(Handler Mapping)进行处理器管理和视图解析器(View Resolver)进行视图管理;页面控制器/动作/处理器为Controller接口(仅包含ModelAndView handleRequest(request, response) 方法)的实现(也可以是任何的POJO类);支持本地化(Locale)解析、主题(Theme)解析及文件上传等;提供了非常灵活的数据验证、格式化和数据绑定机制;提供了强大的约定大于配置(惯例优先原则)的契约式编程支持。
一、springmvc的处理流程
第一步:用户发送请求到前端控制器(DispatcherServlet)。
第二步:前端控制器请求 HandlerMapping 查找 Handler,可以根据 xml 配置、注解进行查找。
第三步: 处理器映射器 HandlerMapping 向前端控制器返回 Handler
第四步:前端控制器调用处理器适配器去执行 Handler
第五步:处理器适配器执行 Handler
第六步:Handler 执行完成后给适配器返回 ModelAndView
第七步:处理器适配器向前端控制器返回 ModelAndView
ModelAndView 是SpringMVC 框架的一个底层对象,包括 Model 和 View
第八步:前端控制器请求试图解析器去进行视图解析
根据逻辑视图名来解析真正的视图。
第九步:试图解析器向前端控制器返回 view
第十步:前端控制器进行视图渲染
就是将模型数据(在 ModelAndView 对象中)填充到 request 域
第十一步:前端控制器向用户响应结果
(四)ssm框架整合
(五)RBAC权限控制
一、RBAC概念(基于资源或者角色的访问控制(Resource/Role-Based Access Control))
用户---角色---权限,角色是沟通用户和权限的中间件;用户属于某项角色,角色具有某些权限。用户与角色之间是多对多,角色和权限也是多对多。
二、RBAC详解
RBAC认为权限授权实际上是Who、What、How的问题。在RBAC模型中,who、what、how构成了访问权限三元组,也就是“Who对What(Which)进行How的操作”。即(who)用户或者角色对什么资源(what)进行怎样的操作(how)。
三、权限管理
权限管理包括用户身份认证和授权两部分,简称认证授权。对于需要访问控制的资源用户首先经过身份认证,认证通过后用户具有该资源的访问权限方可访问。
1、用户身份认证
身份认证,就是判断一个用户是否为合法用户的处理过程。最常用的简单身份认证方式是系统通过核对用户输入的用户名和口令,看其是否与系统中存储的该用户的用户名和口令一致,来判断用户身份是否正确。对于采用指纹等系统,则出示指纹;对于硬件Key等刷卡系统,则需要刷卡。
2、授权
授权,即访问控制,控制谁能访问哪些资源。主体进行身份认证后需要分配权限方可访问系统的资源,对于某些资源没有权限是无法访问的。即用户可以对资源进行哪些操作(RBAC)。
四、权限控制(RBAC)
1、基于角色的访问控制
RBAC基于角色的访问控制(Role-Based Access Control)是以角色为中心进行访问控制,比如:主体的角色为总经理可以查询企业运营报表,查询员工工资信息等。
缺点:以角色进行访问控制粒度较粗,如果上图中查询工资所需要的角色变化为总经理和部门经理,此时就需要修改判断逻辑为“判断主体的角色是否是总经理或部门经理”,系统可扩展性差。
2、基于资源的访问控制
RBAC基于资源的访问控制(Resource-Based Access Control)是以资源为中心进行访问控制,比如:主体必须具有查询工资权限才可以查询员工工资信息等。
优点:系统设计时定义好查询工资的权限标识,即使查询工资所需要的角色变化为总经理和部门经理也只需要将“查询工资信息权限”添加到“部门经理角色”的权限列表中,判断逻辑不用修改,系统可扩展性强。
(七)Hibernate4
一、Hibernate概念
Hibernate(冬眠),是一个轻量级的orm框架,对jdbc进行封装,简化jdbc操作,完成数据的持久化。使用hibernate之后,不需要编写sql语句,是一个全自动的持久化框架。直接调用hibernate的一个save方法,实现保存数据,其他类似。可以跨数据库平台,提高开发效率。
(八)jFinal(类似spring boot)
一、Jfinal概念
Jfinal是一个国产基于 Java 语言的极速 WEB + ORM 框架,使用这个框架可以省略XML配置,类似于SpringBoot这个开源框架;这个JFinal只需要关心业务代码,其他可以不用考虑;使用此框架你可以不用写接口,不用写业务,只需要写控制器;在使用控制器的时候也基本不需要注解,全部是SQL语句操作,最多配置一个后端路由就可以跑起整个项目。
采用的是MVC架构,其核心设计目标是开发迅速、代码量少、学习简单、功能强大、轻量级、易扩展、Restful。
(九)shiro安全框架
一、shiro概念(读ʃɪrɒ)
Shiro是apache旗下一个开源框架,它将软件系统的安全认证相关的功能抽取出来,实现用户身份认证,权限授权、加密、会话管理等功能,组成了一个通用的安全认证框架。
java领域中spring security(原名Acegi)也是一个开源的权限管理框架,但是spring security依赖spring运行,而shiro就相对独立,最主要是因为shiro使用简单、灵活,所以现在越来越多的用户选择shiro。
二、shiro相关概念
1、Subject
Subject即主体,外部应用与subject进行交互,subject记录了当前操作用户,将用户的概念理解为当前操作的主体,可能是一个通过浏览器请求的用户,也可能是一个运行的程序。Subject在shiro中是一个接口,接口中定义了很多认证授相关的方法,外部程序通过subject进行认证授,而subject是通过SecurityManager安全管理器进行认证授权。
2、SecurityManager
SecurityManager即安全管理器,对全部的subject进行安全管理,它是shiro的核心,负责对所有的subject进行安全管理。通过SecurityManager可以完成subject的认证、授权等,实质上SecurityManager是通过Authenticator进行认证,通过Authorizer进行授权,通过SessionManager进行会话管理等。
SecurityManager是一个接口,继承了Authenticator, Authorizer, SessionManager这三个接口。
3、Realm
Realm: Realm充当了Shiro与应用安全数据间的“桥梁”或者“连接器”。也就是说,当对用户执行认证(登录)和授权(访问控制)验证时,Shiro会从应用配置的Realm中查找用户及其权限信息。
从这个意义上讲,Realm实质上是一个安全相关的DAO:它封装了数据源的连接细节,并在需要时将相关数据提供给Shiro。当配置Shiro时,你必须至少指定一个Realm,用于认证和(或)授权。配置多个Realm是可以的,但是至少需要一个。
(十)solr搜索框架
一、solr概念(读soler)
Solr是 Apache 公司一个独立开源的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML/JSON文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML/JSON格式的返回结果。
Solr 包装并扩展了 Lucene,所以Solr的基本上沿用了Lucene的相关术语。更重要的是,Solr 创建的索引与 Lucene 搜索引擎库完全兼容。
二、Lucene概念(读'lusen)
Lucene是一个基于Java的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能。Lucene 目前是 Apache Jakarta(雅加达) 家族中的一个开源项目。也是目前最为流行的基于Java开源全文检索工具包。目前已经有很多应用程序的搜索功能是基于 Lucene ,比如Eclipse 帮助系统的搜索功能。Lucene能够为文本类型的数据建立索引,所以你只要把你要索引的数据格式转化的文本格式,Lucene 就能对你的文档进行索引和搜索。
三、solr的搜索流程
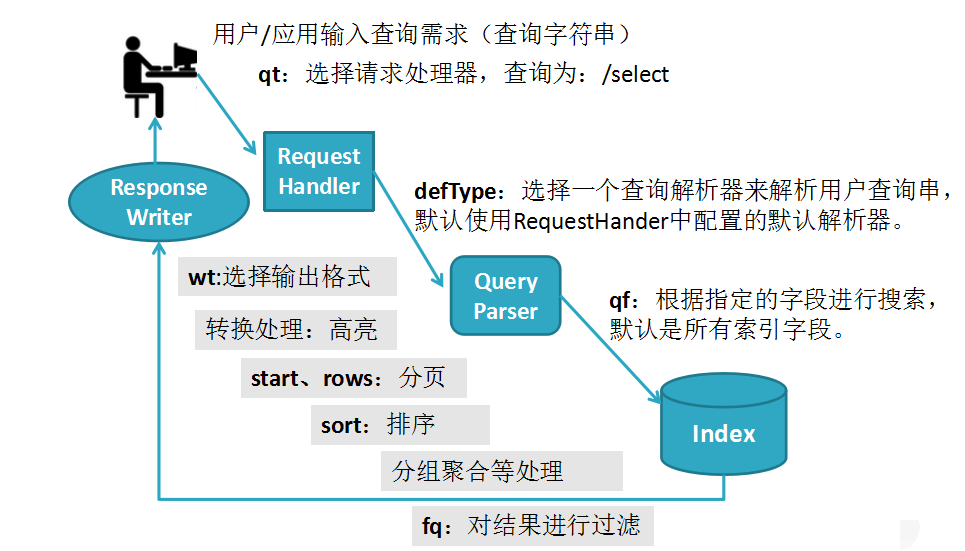
首先获取用户输入的查询串,使用查询解析器QueryParser解析查询串生成查询对象Query,使用所有搜索器IndexSearcher执行查询对象Query得到TopDocs,遍历TopDocs得到文档Document。
1、详细流程
用户输入查询字符串,根据用户的请求类型qt(查询为/select)选择请求处理器RequestHandler,根据用户输入的参数defType来选择一个查询解析器解析用户的查询串(默认使用RequestHander中配置的默认查询解析器),查询解析器解析完以后根据用户输入的参数qf指定的字段进行搜索(默认是所有索引字段),查询到结果以后做一些特殊的处理(fq,sort,start,rows,wt)以后使用响应处理器ResponseWriter返回给用户。
四、中文分词器
中文分词在solr里面是没有默认开启的,需要我们自己配置一个中文分词器。目前可用的分词器有smartcn,IK,Jeasy,庖丁。其实主要是两种:
一种是基于中科院ICTCLAS的隐式马尔科夫HMM算法的中文分词器,如smartcn,ictclas4j,优点是分词准确度高,缺点是不能使用用户自定义词库;
另一种是基于最大匹配的分词器,如IK ,Jeasy,庖丁,优点是可以自定义词库,增加新词,缺点是分出来的垃圾词较多。各有优缺点看应用场合自己衡量选择吧。
五、使用搜索指令准确搜索
双引号:告诉搜索引擎,将双引号里面的关键词作为一个整体进行搜索,不要进行分词操作。
Intitle:告诉搜索引擎,标题中一定要包含搜索关键词(网页内容有不算数)。
也可以自己组织关键词搜索,多个关键词用空格分开。
(十一)struts2框架
(十二)Nginx服务器
一、代理服务器
代理服务器是介于客户端和Web服务器之间的另一台服务器,有了它之后,浏览器不是直接到Web服务器去取回网页,而是通过向代理服务器发送请求,信号会先送到代理服务器,由代理服务器来取回浏览器所需要的信息并传送给你的浏览器。
二、反向代理服务器
反向代理服务器:在服务器端接收客户端的请求,然后把请求分发给具体的服务器进行处理,然后再将服务器的响应结果反馈给客户端。Nginx就是其中的一种反向代理服务器软件。
三、正向代理和反向代理的区别
正向代理:客户端知道服务器端,通过代理端连接服务器端。代理端代理的是服务器端;
反向代理:所谓反向,是对正向而言的。服务器端知道客户端,客户端不知道服务器端,通过代理端连接服务器端。代理端代理的是客户端。代理对象刚好相反,所以叫反向代理。
四、代理请求流程
一个完整的代理请求过程为:客户端首先与代理服务器创建连接,然后根据代理服务器所使用的代理协议,请求对目标服务器创建连接、或则获得目标服务器的指定资源。Web代理服务器是网络的中间实体。代理位于Web客户端和Web服务器之间,扮演“中间人”的角色。 HTTP的代理服务器既是Web服务器又是Web客户端。
五、Nginx概念(读endʒɪnks)
nginx是一款自由的、开源的、高性能的HTTP服务器和反向代理服务器;同时也是一个IMAP、POP3、SMTP代理服务器;nginx可以作为一个HTTP服务器进行网站的发布处理,另外nginx可以作为反向代理进行负载均衡的实现。(方向代理、负载均衡)
其特点是占有内存少,并发能力强,事实上nginx的并发能力确实在同类型的网页服务器中表现较好,中国大陆使用nginx网站用户有:百度、京东、新浪、网易、腾讯、淘宝等。
(十三)Redis缓存技术
一、Redis概念
Redis 是一个基于内存的高性能key-value数据库。redis本质上是一个Key-Value类型的内存数据库,很像memcached,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据flush到硬盘上进行保存。因为是纯内存操作,Redis的性能非常出色,每秒可以处理超过 10万次读写操作,是已知性能最快的Key-Value DB。 它常被称作是一款数据结构服务器。
二、Redis特点
Redis最大的魅力是支持保存多种数据结构,此外单个value的最大限制是1GB,不像 memcached只能保存1MB的数据,因此Redis可以用来实现很多有用的功能,比方说用他的List来做FIFO双向链表,实现一个轻量级的高性 能消息队列服务,用他的Set可以做高性能的tag系统等等。另外Redis也可以对存入的Key-Value设置expire时间,因此也可以被当作一 个功能加强版的memcached来用。
Redis为了达到最快的读写速度将数据都读到内存中,并通过异步的方式将数据写入磁盘。所以redis具有快速和数据持久化的特征。
(十四)jvm虚拟机优化
(十五)zookeeper学习
一、Zookeeper概念(读zu:ki:pə)
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协
调/通知、集群管理、Master 选举、配置维护,名字服务、分布式同步、分布式锁和分布式队列等功能。
二、Zookeeper工作原理
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
三、Zokeeper的三个角色
1、领导者(leader),负责进行投票的发起和决议,更新系统状态;2、学习者(learner),包括跟随者(follower)和观察者(observer);
3、follower用于接受客户端请求并想客户端返回结果,在选主过程中参与投票;4、 Observer可以接受客户端连接,将写请求转发给leader,但observer不参加投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读取速度。
(十六)、Logstach日志分析
一、logstach原理
logstash是一个数据分析软件,主要目的是分析log日志。整一套软件可以当作一个MVC模型,logstash是controller层,Elasticsearch是一个model层,kibana是view层。
首先将数据传给logstash,它将数据进行过滤和格式化(转成JSON格式),然后传给Elasticsearch进行存储、建搜索的索引,kibana提供前端的页面再进行搜索和图表可视化,它是调用Elasticsearch的接口返回的数据进行可视化。logstash和Elasticsearch是用Java写的,kibana使用node.js框架。
1、logstash基本上由三部分组成,input、output以及用户需要才添加的filter;格式如下:
input {...}:用于定义数据源
filter {...} :用于定义用户自己的数据规则
output {...}:用于定义输出配置。
Logstash 的过滤器是用 Ruby 写的,Kibana 是用纯 Javascript 写的,而 ElasticSearch 也有自己的 REST 接口和 JSON 模板。
二、日志处理
目前通常的解决办法是使用logstash划分使用日志,并将它们发送并存储在Splunk、ELK或其他的日志管理工具中。
三、日志的作用
1、问题追踪:通过日志不仅仅包括我们程序的一些bug,也可以在安装配置时,通过日志可以发现问题。
2、状态监控:通过实时分析日志,可以监控系统的运行状态,做到早发现问题、早处理问题。
3、安全审计:审计主要体现在安全上,通过对日志进行分析,可以发现是否存在非授权的操作。
四、日志级别
日志信息的优先级从高到低有OFF、FATAL、ERROR、WARN、INFO、DEBUG、ALL,分别用来指定这条日志信息的重要程度。
A:off 最高等级,用于关闭所有日志记录。
B:fatal 指出每个严重的错误事件将会导致应用程序的退出。(重大危险)
C:error 指出虽然发生错误事件,但仍然不影响系统的继续运行。(错误)
D:warm 表明会出现潜在的错误情形。(警告)
E:info 一般和在粗粒度级别上,强调应用程序的运行全程。(信息)
F:debug 一般用于细粒度级别上,对调试应用程序非常有帮助。(调试)
G:all 最低等级,用于打开所有日志记录。
五、Log4J组件
Log4j由三个重要的组件构成:日志信息的产生器、日志信息的输出目的地、日志信息的输出格式。
1、日志信息的的产生器Logger:它主要负责生成日志并能够按照优先级进行输出(级别从高到低有ERROR、WARN、INFO、DEBUG,分别用来指定这条日志信息的重要程度);
2、日志信息的输出目的地Appender:它指定了日志将打印到控制台还是文件中等不同的目的地;
3、日志信息的输出格式Layout:它控制了日志信息的显示内容的格式。
(十七)、SaaS:Software-as-a-Service(软件即服务)
SaaS是一种通过Internet提供软件的模式,厂商将应用软件统一部署在自己的服务器上,客户可以根据自己实际需求,通过互联网向厂商定购所需的应用软件服务,按定购的服务多少和时间长短向厂商支付费用,并通过互联网获得厂商提供的服务。(简单理解:人家把你想要的功能开发成应用软件,然后直接卖账号给你用,你也不需要担心服务器、带宽、应用开发等问题,直接交钱使用就行。)
云计算是通过将应用直接剥离出去,将平台留下来,做平台的始终做平台,而做云计算资源的人就专心做好自身的调度和服务。这种方式使做SaaS的人可以专注于自己所熟悉的业务,为别人提供软件和服务的应用。
(十八)、云计算
云计算这三个字的理解,云,是网络、互联网的一种比喻说法,即互联网与建立互联网所需要的底层基础设施的抽象体。“计算”当然不是指一般的数值计算,指的是一台足够强大的计算机提供的计算服务(包括各种功能,资源,存储)。“云计算”可以理解为:网络上足够强大的计算机为你提供的服务,只是这种服务是按你的使用量进行付费的。
一、云计算的三种模式
1、IaaS: Infrastructure-as-a-Service(基础设施即服务)
首先从IaaS对应的基础设施堆栈说起,包含了数据中心里计算、网络、存储和安全等几个部分,IaaS可不是简单将这些设备罗列起来,而是要将这些设备所能提供的资源抽象成一系列可用服务,可以通过代码或网页的控制台进行访问和自动化部署。IaaS提供的服务就是人们可以根据需要访问虚拟的基础设施资源,IaaS接到需求时,根据请求几分钟内就可以完成资源的部署和运行,而且还可以进行计费,向使用的人们收取使用费用。人们不用关心数据中心和基础设施怎么运转的,这些由IaaS的提供商来搞定,人们聚焦在自己的应用程序上就行。像国际上的亚马逊AWS,还有国内的阿里云,都在提供IaaS服务,是实际部署最多的一种服务模式。
基础设施:数据中心、存储、服务器、网络、负载均衡、防火墙。
2、PaaS:(Platform as a Service–平台即服务)
PaaS主要是将一个开发和运行平台作为服务提供给用户,可以包括一整套的IDE开发测试环境。可以是虚拟服务,也可以是操作系统,节省了你在硬件上的费用。对开发者来说,只需要关注自己系统的业务逻辑,能够快速、方便的创建Web应用,无需担心底层软件。 比较典型的便是计算平台。(PaaS最大的作用在于通过简单的API调用,人们就可以快速集成许多成熟和可靠的第三方解决方案,不必经历一系列的采购及安装实施流程。)
应用栈:操作系统、编程环境、应用服务器、数据库、监听、中间件、
3、SaaS:Software as a Service–软件即服务
对用户来说,软件的开发、管理、部署都交给了第三方,不需要关心技术问题,可以拿来即用。
应用软件:认证授权、用户界面、管理系统、控制面板、事务处理、工具。
(十九)RPC和REST详解
一、RPC(Remote Procedure Call Protocol):远程调用协议
1、RPC概念
RPC 的全称是 Remote Procedure Call 是一种进程间通信方式。 它允许程序调用另一个地址空间(通常是共享网络的另一台机器上)的过程或函数,而不用程序员显式编码这个远程调用的细节。即程序员无论是调用本地的还是远程的函数,本质上编写的调用代码基本相同。
使用场景:
当我们的业务越来越多、应用也越来越多时,自然的,我们会发现有些功能已经不能简单划分开来或者划分不出来。此时,可以将公共业务逻辑抽离出来,将之组成独立的服务Service应用 。而原有的、新增的应用都可以与那些独立的Service应用 交互,以此来完成完整的业务功能。所以此时,我们急需一种高效的应用程序之间的通讯手段来完成这种需求,所以你看,RPC大显身手的时候来了!
其实3描述的场景也是服务化 、微服务 和分布式系统架构 的基础场景。即RPC框架就是实现以上结构的有力方式。
2、RPC的意义
RPC 的主要目标是让构建分布式计算(应用)更容易,在提供强大的远程调用能力时不损失本地调用的语义简洁性。 为实现该目标,RPC 框架需提供一种透明调用机制让使用者不必显式的区分本地调用和远程调用。
3、RPC分类
RPC 调用分以下两种:
- 同步调用:客户端等待调用执行完成并获取到执行结果。
- 异步调用:客户端调用后不用等待执行结果返回,但依然可以通过回调通知等方式获取返回结果。若客户端不关心调用返回结果,则变成单向异步调用,单向调用不用返回结果。
异步和同步的区分在于是否等待服务端执行完成并返回结果。
4、RPC实现过程
User 就是 Client 端。当 User 想发起一个远程调用时,它实际是通过本地调用 User-stub。 User-stub 负责将调用的接口、方法和参数通过约定的协议规范进行编码并通过本地的 RPCRuntime 实例传输到远端的实例。 远端 RPCRuntime 实例收到请求后交给 Server-stub 进行解码后发起向本地端 Server 的调用,调用结果再返回给 User 端。
5、本地调用和远程调用的区别:
- 本地调用一定会执行,而远程调用则不一定,调用消息可能因为网络原因并未发送到服务方。
- 本地调用只会抛出接口声明的异常,而远程调用还会跑出 RPC 框架运行时的其他异常。
- 本地调用和远程调用的性能可能差距很大,这取决于 RPC 固有消耗所占的比重。
二、REST
REST架构风格最重要的架构约束有6个:
- 客户-服务器(Client-Server)
通信只能由客户端单方面发起,表现为请求-响应的形式。
- 无状态(Stateless)
通信的会话状态(Session State)应该全部由客户端负责维护。
- 缓存(Cache)
响应内容可以在通信链的某处被缓存,以改善网络效率。
- 统一接口(Uniform Interface)
通信链的组件之间通过统一的接口相互通信,以提高交互的可见性。
- 分层系统(Layered System)
通过限制组件的行为(即,每个组件只能“看到”与其交互的紧邻层),将架构分解为若干等级的层。
- 按需代码(Code-On-Demand,可选)
支持通过下载并执行一些代码(例如Java Applet、Flash或JavaScript),对客户端的功能进行扩展。
1、概念
REST全称是Representational State Transfer,中文意思是表述(编者注:通常译为表征)性状态转移。REST指的是一组架构约束条件和原则。” 如果一个架构符合REST的约束条件和原则,我们就称它为RESTful架构。
理论上REST架构风格并不是绑定在HTTP上,只不过目前HTTP是唯一与REST相关的实例。 所以我们这里描述的REST也是通过HTTP实现的REST。
2、rest表示
REST全称是表述性状态转移,那究竟指的是什么的表述? 其实指的就是资源。任何事物,只要有被引用到的必要,它就是一个资源。资源可以是实体(例如手机号码),也可以只是一个抽象概念(例如价值) 。要让一个资源可以被识别,需要有个唯一标识,在Web中这个唯一标识就是URI(Uniform Resource Identifier)。
3、资源的表述
资源在外界的具体呈现,可以有多种表述(或成为表现、表示)形式,在客户端和服务端之间传送的也是资源的表述,而不是资源本身。 例如文本资源可以采用html、xml、json等格式,图片可以使用PNG或JPG展现出来。 资源的表述包括数据和描述数据的元数据,例如,HTTP头“Content-Type” 就是这样一个元数据属性。
那么客户端如何知道服务端提供哪种表述形式呢?
答案是可以通过HTTP内容协商,客户端可以通过Accept头请求一种特定格式的表述,服务端则通过Content-Type告诉客户端资源的表述形式。
4、资源的链接
REST是使用标准的HTTP方法来操作资源的,但仅仅因此就理解成带CURD的Web数据库架构就太过于简单了。 这种反模式忽略了一个核心概念:“超媒体即应用状态引擎(hypermedia as the engine of application state)”。 超媒体是什么? 当你浏览Web网页时,从一个连接跳到一个页面,再从另一个连接跳到另外一个页面,就是利用了超媒体的概念:把一个个把资源链接起来.要达到这个目的,就要求在表述格式里边加入链接来引导客户端。
5、无状态原则
REST原则中的无状态通信原则。这里说的无状态通信原则,并不是说客户端应用不能有状态,而是指服务端不应该保存客户端状态。
状态应该区分应用状态和资源状态,客户端负责维护应用状态,而服务端维护资源状态。 客户端与服务端的交互必须是无状态的,并在每一次请求中包含处理该请求所需的一切信息。 服务端不需要在请求间保留应用状态,只有在接受到实际请求的时候,服务端才会关注应用状态。 这种无状态通信原则,使得服务端和中介能够理解独立的请求和响应。 在多次请求中,同一客户端也不再需要依赖于同一服务器,方便实现高可扩展和高可用性的服务端。
但有时候我们会做出违反无状态通信原则的设计,例如利用Cookie跟踪某个服务端会话状态,常见的像J2EE里边的JSESSIONID。 这意味着,浏览器随各次请求发出去的Cookie是被用于构建会话状态的。 当然,如果Cookie保存的是一些服务器不依赖于会话状态即可验证的信息(比如认证令牌),这样的Cookie也是符合REST原则的。 “会话”状态不是作为资源状态保存在服务端的,而是被客户端作为应用状态进行跟踪的。
八、微服务架构
(一)spring boot
一、微服务
微服务的目的是有效的拆分应用,实现敏捷开发和部署 。(将子系统拆成一个一个的jar包运行就是微服务。)
二、康威定律
人与人的沟通是非常复杂的,一个人的沟通精力是有限的,所以当问题太复杂需要很多人解决的时候,我们需要做拆分组织来达成对沟通效率的管理
组织内人与人的沟通方式决定了他们参与的系统设计,管理者可以通过不同的拆分方式带来不同的团队间沟通方式,从而影响系统设计
如果子系统是内聚的,和外部的沟通边界是明确的,能降低沟通成本,对应的设计也会更合理高效
复杂的系统需要通过容错弹性的方式持续优化,不要指望一个大而全的设计或架构,好的架构和设计都是慢慢迭代出来的。
一 、产品开发与业务团队
1、产品经理的需求太复杂了?适当忽略一些细节,先抓主线。产品经理的需求太多了?适当放弃一些功能。
2、做到安全有两种方式:
常规的安全指的是尽可能多的发现并消除错误的部分,达到绝对安全,这是理想。
另一种则是弹性安全,即使发生错误,只要及时恢复,也能正常工作,这是现实。
3、一口气吃不成胖子,先搞定能搞定的(就重避轻)。优先重要可搞定的开发,可以适当忽略一些细节和功能。因为无法搞出一个大而全的设计或架构,好的架构和设计都是慢慢迭代出来的,因此可以忽略部分细节和功能,为产品后续升级做准备。
4、业务团队划分:最好按业务来划分团队,这样能让团队自然的自治内聚,明确的业务边界会减少和外部的沟通成本,每个小团队都对自己的模块的整个生命周期负责,没有边界不清,没有无效的扯皮。
二、微服务设计概念落地
微服务设计听上来非常好,但是具体怎么落地啊?这需要回答下面几个问题:
- 客户端如何访问这些服务?
- 服务之间如何通信?
- 这么多服务,怎么找?
- 服务挂了怎么办?
1、客户端如何访问这些服务
一般在后台N个服务和UI之间一般会一个代理或者叫API Gateway,他的作用包括
① 提供统一服务入口,让微服务对前台透明
② 聚合后台的服务,节省流量,提升性能
③ 提供安全,过滤,流控等API管理功能
用过Taobao Open Platform(淘宝开放平台)的就能很容易的体会,TAO就是这个API Gateway。在淘宝开放平台上,各个商家维护自己的商店,其他不受影响。
2、每个服务之间如何通信
所有的微服务都是独立的Java进程跑在独立的虚拟机上,所以服务间的通信就是IPC(inter process communication),已经有很多成熟的方案。现在基本最通用的有两种方式:
同步调用:
①REST(JAX-RS,Spring Boot)
②RPC(Thrift, Dubbo)
异步消息调用(Kafka, Notify, MetaQ)
同步调用比较简单,一致性强,但是容易出调用问题,性能体验上也会差些,特别是调用层次多的时候。RESTful和RPC的比较也是一个很有意 思的话题。异步消息的方式在分布式系统中有特别广泛的应用,他既能减低调用服务之间的耦合,又能成为调用之间的缓冲,确保消息积压不会冲垮被调用方,同时能保证调用方的
服务体验,继续干自己该干的活,不至于被后台性能拖慢。不过需要付出的代价是一致性的减弱,需要接受数据最终一致性;还有就是后台服务一般要 实现幂等性,因为消息
发送出于性能的考虑一般会有重复(保证消息的被收到且仅收到一次对性能是很大的考验);最后就是必须引入一个独立的broker。
3、如此多的服务如何实现
在微服务架构中,一般每一个服务都是有多个拷贝,来做负载均衡。一个服务随时可能下线,也可能应对临时访问压力增加新的服务节点。服务之间如何相互感知?服务如何管理?
这就是服务发现的问题了。一般有两类做法,也各有优缺点。基本都是通过zookeeper等类似技术做服务注册信息的分布式管理。当服务上线时,服务提供者将自己的服务信息
注册到ZK(或类似框架),并通过心跳维持长链接,实时更新链接信息。服务调用者通过ZK寻址,根据可定制算法, 找到一个服务,还可以将服务信息缓存在本地以提高性能。
当服务下线时,ZK会发通知给服务客户端
客户端做:优点是架构简单,扩展灵活,只对服务注册器依赖。缺点是客户端要维护所有调用服务的地址,有技术难度,一般大公司都有成熟的内部框架支持,比如Dubbo。
服务端做:优点是简单,所有服务对于前台调用方透明,一般在小公司在云服务上部署的应用采用的比较多。
4、服务挂了,如何解决
Monolithic方式开发一个很大的风险是,把所有鸡蛋放在一个篮子里,一荣俱荣,一损俱损。而分布式最大的特性就是网络是不可靠的。通过微服务拆分能降低这个风险。
必须确保任一环节出问题都不至于影响整体链路,方法:
①重试机制
②限流
③熔断机制
④负载均衡
⑤降级(本地缓存)
二、spring boot概念
spring boot就是整合了很多优秀的框架,不用我们自己手动的去写一堆xml配置然后进行配置。从本质上来说,Spring Boot就是Spring,它做了那些没有它你也会去做的Spring Bean配置。它使用“习惯优于配置”(项目中存在大量的配置,此外还内置了一个习惯性的配置,让你无需手动进行配置)的理念让你的项目快速运行起来。
例如:以往我们采用SpringMVC+Spring+Mybatis框架进行开发的时候,搭建和整合三大框架,我们需要做很好工作,比如配置web.xml,配置Spring,配置Mybatis,并将它们整合在一起等,而Spring boot框架对此开发过程进行了革命性的颠覆,抛弃了繁琐的xml配置过程,采用大量的默认配置简化我们的开发过程。
1、动态语言:不需要编译,直接运行,比如:JS;
静态语言:先编译在运行。
三、WebJars
1、WebJars是将客户端(浏览器)资源(JavaScript,Css等)打成jar包文件,以对资源进行统一依赖管理。WebJars的jar包部署在Maven中央仓库上。
2、我们在开发Java web项目的时候会使用像Maven,Gradle等构建工具以实现对jar包版本依赖管理,以及项目的自动化管理,但是对于JavaScript,Css等前端资源包,我们只能采用拷贝到webapp下的方式,这样做就无法对这些资源进行依赖管理。那么WebJars就提供给我们这些前端资源的jar包形势,我们就可以进行依赖管理。
3、使用方式:
WebJars主官网 查找对于的组件,比如Vuejs:
<dependency>
< groupId>org.webjars.bower</groupId>
< artifactId>vue</artifactId>
< version>1.0.21</version></dependency>
页面引入:
<link th:href="@{/webjars/bootstrap/3.3.6/dist/css/bootstrap.css}" rel="stylesheet"></link>
(二)spring data
一、spring data概念
Spring Data 项目的目的是为了简化构建基于 Spring 框架应用的数据访问计数,包括非关系数据库、Map-Reduce 框架、云数据服务等等;另外也包含对关系数据库的访问支持。
Spring Data 是持久层通用解决方案,支持 关系型数据库 Oracle、MySQL、非关系型数据库NoSQL、Map-Reduce 框架、云基础数据服务 、搜索服务。
二、spring data的作用
Spring Data JPA 框架,主要针对的就是 Spring 唯一没有简化到的业务逻辑代码,至此,开发者连仅剩的实现持久层业务逻辑的工作都省了,唯一要做的,就只是声明持久层的接口,其他都交给 Spring Data JPA 来帮你完成。
三、spring date使用步骤
1.声明持久层的接口,该接口继承 Repository,Repository 是一个标记型接口,它不包含任何方法,当然如果有需要,Spring Data 也提供了若干 Repository 子接口,其中定义了一些常用的增删改查,以及分页相关的方法。
2.在接口中声明需要的业务方法。Spring Data 将根据给定的策略来为其生成实现代码。
3.在 Spring 配置文件中增加一行声明,让 Spring 为声明的接口创建代理对象。配置了 <jpa:repositories> 后,Spring 初始化容器时将会扫描 base-package 指定的包目录及其子目录,为继承 Repository 或其子接口的接口创建代理对象,并将代理对象注册为 Spring Bean,业务层便可以通过 Spring 自动封装的特性来直接使用该对象。
四、常用接口
1、Repository 接口
基础的 Repository提供了最基本的数据访问功能,其几个子接口则扩展了一些功能。它们的继承关系如下:
–Repository:仅仅是一个标识,表明任何继承它的均为仓库接口类
–CrudRepository:继承Repository,实现了一组CRUD相关的方法
–PagingAndSortingRepository:继承CrudRepository,实现了一组分页排序相关的方法
–JpaRepository:继承PagingAndSortingRepository,实现一组JPA规范相关的方法
–自定义的 XxxxRepository需要继承 JpaRepository,这样的XxxxRepository接口就具备了通用的数据访问控制层的能力。
–JpaSpecificationExecutor:不属于Repository体系,实现一组JPACriteria查询相关的方法
2、@Query 注解
这种查询可以声明在 Repository方法中,摆脱像命名查询那样的约束,将查询直接在相应的接口方法中声明,结构更为清晰,这是Springdata 的特有实现。
//查询id值最大的那个person//使用@Query注解可以自定义JPQL语句,语句可以实现更灵活的查询@Query(“SELECT p FROM Person p WHERE p.id=(SELECT max(p2.id) FROM Person p2)”)Person getMaxIdPerson();3、@Modifying 注解
@Query 与 @Modifying这两个annotation一起声明,可定义个性化更新操作,例如只涉及某些字段更新时最为常用,示例如下
//可以通过自定义的JPQL 完成update和delete操作,注意:JPQL不支持Insert操作//在@Query注解中编写JPQL语句,但必须使用@Modify进行修饰,以通知SpringData,这是一个Update或者Delete//Update或者delete操作,需要使用事务,此时需要定义Service层,在service层的方法上添加事务操作//默认情况下,SpringData的每个方法上有事务,但都是一个只读事务,他们不能完成修改操作@Modifying@Query(“update Person p set p.email=:email where id=:id”)void updatePersonEmail(@Param(“id”)Integer id,@Param(“email”)String email);
(三)spring cloud
一、spring cloud概念
Spring Cloud 是一套完整的微服务解决方案,基于 Spring Boot 框架,准确的说,它不是一个框架,而是一个大的容器,它将市面上较好的微服务框架集成进来,从而简化了开发者的代码量。
Spring Cloud为开发人员提供了快速构建分布式系统中的一些通用模式(例如:配置管理,服务发现,断路器,智能路由,微服务代理,控制总线,一次性令牌,全局锁,领导选举,分布式会话,群集状态等)。并且使用Spring Cloud的开发人员可以快速高效的构建出实现这些模式的服务和应用程序。
Spring Cloud 是一系列框架的有序集合,它利用 Spring Boot 的开发便利性简化了分布式系统的开发,比如服务发现、服务网关、服务路由、链路追踪等。Spring Cloud 并不重复造轮子,而是将市面上开发得比较好的模块集成进去,进行封装,从而减少了各模块的开发成本。换句话说:Spring Cloud 提供了构建分布式系统所需的“全家桶”。
二、spring cloud的优缺点
1、其主要优点有:
集大成者,Spring Cloud 包含了微服务架构的方方面面。
约定优于配置,基于注解,没有配置文件。
轻量级组件,Spring Cloud 整合的组件大多比较轻量级,且都是各自领域的佼佼者。
开发简便,Spring Cloud 对各个组件进行了大量的封装,从而简化了开发。
开发灵活,Spring Cloud 的组件都是解耦的,开发人员可以灵活按需选择组件。
2、它的缺点:
项目结构复杂,每一个组件或者每一个服务都需要创建一个项目。
部署门槛高,项目部署需要配合 Docker 等容器技术进行集群部署,而要想深入了解 Docker,学习成本高。
三、网站架构演变
集群:不同的机器,执行同一个计算问题。
一台机器累如狗,怎么办?来两台,负载均衡。
一台机器宕机,怎么办?来两台,灾备容错。
一台机器性能好,怎么办?让性能好的,加权轮询。
分布式:把一个复杂的计算问题,拆分多个子计算,分布到不同机器上,使其并行执行。
一个计算问题计算过长,怎么办?拆分成子计算,在不同机器并行执行,缩短计算时长。
一个计算问题涉及另一个机器的资源,怎么办?拷贝过来?那我100台都需要呢?所以,需要远程调用和协作。
四、spring cloud现状
目前,国内使用 Spring Cloud 技术的公司并不多见,不是因为 Spring Cloud 不好,主要原因有以下几点:
1、Spring Cloud 中文文档较少,出现问题网上没有太多的解决方案。
2、国内创业型公司技术老大大多是阿里系员工,而阿里系多采用 Dubbo 来构建微服务架构。(rpc:(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。)
3、大型公司基本都有自己的分布式解决方案,而中小型公司的架构很多用不上微服务,所以没有采用 Spring Cloud 的必要性。
但是,微服务架构是一个趋势,而 Spring Cloud 是微服务解决方案的佼佼者,这也是作者写本系列课程的意义所在。
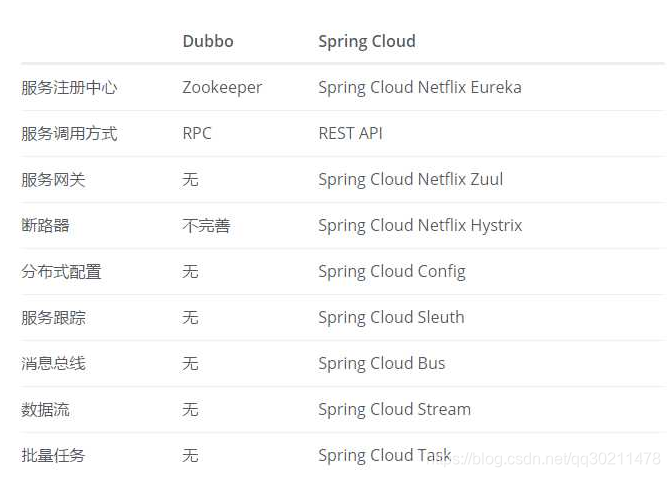
五、spring cloud和Dubbo对比
六、高级阶段技术点如下:
1.负载均衡Ribbon
2.声明式服务调用Feign
3.服务容错保护 Hystrix
4.如何设计微服务
5.服务网关Zuul
6.分布式配置中心Config
7.消息总线Bus
8.消息驱动Stream
9.分布式服务跟踪Sleuth
七、架构风格
架构风格是指项目的一种设计模式。和程序的23种设计模式区分开。
1、常见的架构风格
基于客户端和服务端的(例如:QQ、大型网络游戏)
基于组件模型的架构(EJB)
分层架构(MVC)
面向服务架构(SOA:电商)
微服务架构
单体架构(所有功能都在一个应用中)
八、Docker
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器上,也可以实现虚拟化,容器是完全使用沙箱机制,相互之间不会有任何接口。
Docker的思想来自于集装箱,集装箱解决了什么问题?在一艘大船上,可以把货物规整的摆放起来。并且各种各样的货物被集装箱标准化了,集装箱和集装箱之间不会互相影响。那么我就不需要专门运送水果的船和专门运送化学品的船了。只要这些货物在集装箱里封装的好好的,那我就可以用一艘大船把他们都运走。docker就是类似的理念。现在都流行云计算了,云计算就好比大货轮。docker就是集装箱。
1、docker的应用场景
1.不同的应用程序可能会有不同的应用环境,比如.net开发的网站和php开发的网站依赖的软件就不一样,如果把他们依赖的软件都安装在一个服务器上就要调试很久,而且很麻烦,还会造成一些冲突。比如IIS和Apache访问端口冲突。这个时候你就要隔离.net开发的网站和php开发的网站。常规来讲,我们可以在服务器上创建不同的虚拟机在不同的虚拟机上放置不同的应用,但是虚拟机开销比较高。docker可以实现虚拟机隔离应用环境的功能,并且开销比虚拟机小,小就意味着省钱了。
场景
2.你开发软件的时候用的是Ubuntu,但是运维管理的都是centos,运维在把你的软件从开发环境转移到生产环境的时候就会遇到一些Ubuntu转centos的问题,比如:有个特殊版本的数据库,只有Ubuntu支持,centos不支持,在转移的过程当中运维就得想办法解决这样的问题。这时候要是有docker你就可以把开发环境直接封装转移给运维,运维直接部署你给他的docker就可以了。而且部署速度快。
场景
3.在服务器负载方面,如果你单独开一个虚拟机,那么虚拟机会占用空闲内存的,docker部署的话,这些内存就会利用起来。
(四)微服务和SOA
面向服务架构中的服务应该脱离对对象实体的抽象,这样无法体现服务的多样性。因为面对对象的抽象已经默认约定了对象和服务之间的关系,即已经明确了具体服务。
微服务并不是什么新鲜事,至少SOA理念中几乎包含了所有微服务的理念。本质上说,微服务“微“的并不是服务,而是应用,其实SOA也是倡导服务系统走专业化的道路的,这我们在最开始做ESB的时候就在推销这个概念,比如将传统核心按业务条线拆分成不同的专业系统等。
相对应的,为了方便起见我们将WebServices时代的SOA称为”大服务“以示区别。
上述引用的文章中微服务架构推荐一个服务一个系统,事实上我们看到的是一个业务实体一个系统,这符合我们对业务系统内部用面向对象的方式进行建模的传统。
当然,也是因为传统的“服务“的概念和我们的提出的服务不是相同的,这一点上微服务和大服务对服务的概念是相同的,比如引用中的”行程管理服务“其实是由针对一个业务实体的多种操作来组成的。
如果服务依然是对对象实体的抽象,那么SOA所有这些概念不过都是在炒作,和面向对象没有任何实质上的进展和差异。事实上,我们知道WebServices本质上就是一种远程对象,与我们熟知的Corba、COM、EJB等几乎没有任何本质差异。如果说SOA已死,对大服务来说SOA就从来没活过,那不过是远程对象穿了个马甲而已;如果说微服务当立,我看不出与大服务有什么本质的差异,倒不如说微应用当立更好。
一、服务定义
服务的本质就是行为(业务活动)的抽象。
1、s++架构
S++(Service Plus Plus)要做的事情,就是通过服务的业务与技术分离(第一个+)、通过服务多态建模(第二个+),彻底的将传统服务中和业务无关的技术成分剥离出去,放到服务的外延中,让服务内涵成为纯粹的业务描述。
30年不断的和服务打交道,今天我们眼中的服务随着新技术、新思维方式的到来已变的和以往有很大不同。但是,服务本身真的变了么?
想想多年以前的缴费服务,和今天相比,由于所处环境不同,一定会有不同的流程和体验,但是,其中的服务参与者并没有改变,服务的要素也是相同的。实际上,服务要素就是服务的业务部分,而因环境变化的是技术部分。
二、soa概念和微服务概念
SOA的出现其实是为了解决历史问题:企业在信息化的过程中会有各种各样互相隔离的系统,需要有一种机制将他们整合起来,所以才会有上边所述的ESB的出现。同样的,也造成了SOA初期的服务是很大的概念,通常指定的一个可以独立运作的系统(这样看,好像服务间天然的松耦合)。这种做法相当于是「把子系统服务化」。
微服务没有历史包袱,轻装上阵,服务的尺寸通常不会太大,关于服务的尺寸,在实际情况中往往是一个服务应该能够代表「实际业务场景中的一块不可分割或不易分割的业务实体」。将服务的尺寸控制在一个较小的体量可以带来很多的好处:
更易于实现低耦合、高内聚
更易于维护
更易于扩展
更易于关注实际业务场景
1、ESB
ESB(enterprise service bus)叫企业服务总线, 从名称就能知道,它的概念借鉴了计算机组成原理中的通信模型——总线,所有需要和外部系统通信的系统,统统接入ESB,岂不是完美地兼容了现有的互相隔离的异构系统,可以利用现有的系统构建一个全新的松耦合的异构的分布式系统。
但,实际使用中,它还是会有很多的缺点,首先就是ESB的本身就很复杂,大大增加了系统的复杂性和可维护性。其次就是由于ESB想要做到所有服务都通过一个通路通信,直接降低了通信速度。
2、基础设施
任何软件系统都是要部署到具体的基础设施上去的,关于基础设施的部署也有很多的选择,如:PC vs Docker、Apache vs Nginx、Tomcat vs Jetty。
3、微服务框架
Spring全家桶,用起来很舒服,只有你想不到,没有它做不到。
Dubbox,很多国内的企业还在用,可以支持RESTful风格的API,但更多的还是会使用Dubbox的默认的基于RPC的API,调用远程API像调用本地API一样。这样做无疑带来了很多优势,但同时其基于接口的方式增加了服务间的耦合,怎么说呢,各有利弊。
Thrift,如果你比较高冷,完全可以基于Thrift自己搞一套抽象的自定义框架。
4、同步vs异步
在跨服务的业务逻辑的实现上,使用基于消息的异步调用,还是使用保证结果的同步方案。
数据服务
内存数据库 vs 持久化数据库(Redis vs MySQL)
关系型数据库 vs 非关系型数据库(MySQL vs Mongo)
传统数据库 vs 分布式数据库(MySQL vs F1)
非关系型数据库又有如KV数据库,文档数据库,图数据库等。
由于MSA提倡服务间的数据隔离,往往不同的服务使用不同的数据源,这就会直接导致数据聚合查询比较困难的问题。进行数据聚合又有几种不同的方案(如CQRS)。
5、日志分析
日志分析也是有很多的成熟解决方案(如ELK)。
九、互联网架构
(一)、linux系统
(二)maven技术
(三)Git学习
(四)svn学习
(五)高并发编程
(六)系统和虚拟机调优
(七)java编程规范
(八)高级网络编程
(九)Netty框架
一、Netty概念
Netty是一个高性能 事件驱动的异步的非堵塞的IO(NIO)框架,用于建立TCP等底层的连接,基于Netty可以建立高性能的Http服务器。支持HTTP、 WebSocket 、Protobuf、 Binary TCP |和UDP,Netty已经被很多高性能项目作为其Socket底层基础,如HornetQ Infinispan Vert.xPlay Framework Finangle和 Cassandra。其竞争对手是:Apache MINA和 Grizzly。
二、堵塞和非堵塞原理
传统硬件的堵塞如下,从内存中读取数据,然后写到磁盘,而CPU一直等到磁盘写完成,磁盘的写操作是慢的,这段时间CPU被堵塞不能发挥效率。
非堵塞的DMA如下图:CPU只是发出写操作这样的指令,做一些初始化工作,DMA具体执行,从内存中读取数据,然后写到磁盘,当完成写后发出一个中断事件给CPU。这段时间CPU是空闲的,可以做别的事情。这个原理称为Zero.copy零拷贝。Netty底层就是基于零拷贝原理实现的。
(十)ActiveMQ消息中间件
消息中间件是一种在分布式应用中互相交换信息的一种技术,常见的成熟消息中间件有:RabbitMQ、SonicMQ,activeMQ。下面正式进行activeMQ探索之旅。ActiveMQ 是Apache出品,最流行的,能力强劲的开源消息总线。
MOM面向消息中间件(Message-oriented middleware) 的总体思想是它作为消息发送器和消息接收器之间的消息中介。
JMS 叫做 Java 消息服务(Java Message Service),是 Java 平台上有关面向 MOM 的技术规范,旨在通过提供标准的产生、发送、接收和处理消息的 API 简化企业应用的开发,类似于 JDBC 和关系型数据库通信方式的抽象。
(十一)单点登录SSO
单点登录(Single Sign On),简称为 SSO,是目前比较流行的企业业务整合的解决方案之一。SSO的定义是在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统。
(十二)数据库和sql优化
(十三)数据库集群和高并发
(十四)Dubbo
(十五)Redis
Redis是一个开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
它通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Map), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
(十六)VSFTPD+Nginx
vsftpd 是一个 UNIX 类操作系统上运行的服务器的名字,它可以运行在诸如 Linux, BSD, Solaris, HP-UX 以及 IRIX 上面。它支持很多其他的 FTP 服务器不支持的特征。
Nginx (engine x) 是一个高性能的HTTP和反向代理服务器,也是一个IMAP/POP3/SMTP服务器。
(十七)soa架构(和微服务区分开)
(十八)jsonp
当通过ajax异步请求其他域名的服务时,存在跨域无权限访问的问题。
此时,可以通过JSONP来实现跨域请求。
2.JSONP原理
ajax异步请求无权限访问。但我们发现,web页面调用js文件时不存在跨域问题(如在我们的页面中引入百度地图API, <script type="text/javascript" src="http://api.map.baidu.com/api?v=2.0&ak=e3ZohdqyB0RL98hFOiC29xqh"></script>),总结发现,凡是拥有“src”属性的标签都拥有跨域的能力,如<script>,<img>,<iframe>等。
这种非正式的传输协议,就是JSONP。JSONP的一个要点是允许客户端传一个callback参数给服务器,然后服务器返回数据时会用这个callback参数作为函数名,包裹住JSON数据,返回客户端,客户端执行返回函数。
(十九)cms模块
cms是最常用的垃圾垃圾回收器,下面分析下CMS垃圾回收器工作原理;
CMS 处理过程有七个步骤:
1. 初始标记(CMS-initial-mark) ,会导致swt;
2. 并发标记(CMS-concurrent-mark),与用户线程同时运行;
3. 预清理(CMS-concurrent-preclean),与用户线程同时运行;
4. 可被终止的预清理(CMS-concurrent-abortable-preclean) 与用户线程同时运行;
5. 重新标记(CMS-remark) ,会导致swt;
6. 并发清除(CMS-concurrent-sweep),与用户线程同时运行;
7. 并发重置状态等待下次CMS的触发(CMS-concurrent-reset),与用户线程同时运行;
(二十)solrj和solrcloud
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
Lucene是一个Java语言编写的利用倒排原理实现的文本检索类库;
Solr是以Lucene为基础实现的文本检索应用服务。Solr部署方式有单机方式、多机Master-Slaver方式、Cloud方式。
SolrCloud是基于Solr和Zookeeper的分布式搜索方案。当索引越来越大,一个单一的系统无法满足磁盘需求,查询速度缓慢,此时就需要分布式索引。在分布式索引中,原来的大索引,将会分成多个小索引,solr可以将这些小索引返回的结果合并,然后返回给客户端。
(二十一)CDN(内容分发网络)
一、CDN概念
CDN的全称是Content Delivery Network,即内容分发网络。CDN是构建在网络之上的内容分发网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。CDN的关键技术主要有内容存储和分发技术。
1、CDN原理
CDN的基本原理是广泛采用各种缓存服务器,将这些缓存服务器分布到用户访问相对集中的地区或网络中,在用户访问网站时,利用全局负载技术将用户的访问指向距离最近的工作正常的缓存服务器上,由缓存服务器直接响应用户请求。
(二十二)、幂等操作
1、幂等函数,或幂等方法,是指可以使用相同参数重复执行,并能获得相同结果的函数。
2、幂等操作特点是:其任意多次执行所产生的影响均与一次执行的影响相同。(尤其是支付功能,一定要注意幂等操作)
一、分布式事务原理
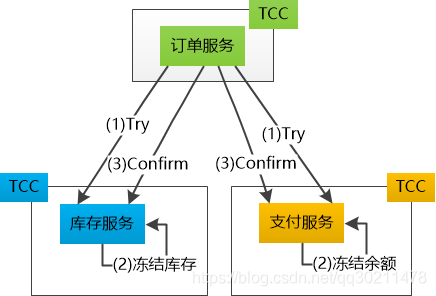
分布式事务原理的特点就是:冻结资源和幂等性。
冻结资源机制:Try(判断是否满足条件,冻结资源) - Confirm(验证资源) -Cancel(失败,恢复资源),简称TCC。
二、构建分布式系统主要注意的假设:
1、网络是可靠的
2、(调用)没有延迟
3、无限的带宽
4、网络是安全的
5、(系统)拓扑结构不会改变
6、有个管理员在管理这个系统
7、(数据)传输代价为零
8. 网络是同质的(同类的)
三、问题解决:
1、库存服务的Try操作完成, 支付服务的Try操作没有完成, 怎么办?
这很好处理,订单服务可以尝试去调用库存的Cancel操作(这应该是个幂等操作,可以多次调用),把冻结的库存释放。
2、那如果出现网络问题,订单服务无法联系库存服务了呢?
利用超时机制,库存服务的TCC组件能够发现冻结的时间已经超时,会自动把冻结的库存给释放。
3、调用支付服务进行Confirm时出错怎么办?
很简单,那就告诉库存服务和订单服务,都进行Cancel操作, 把冻结的数量进行恢复。
4、库存服务所在的机器已经挂掉了呢?怎么计算超时?
系统需要记录日志,把那些没有完成的事情记录下来,持久化到硬盘上。这样下次重启就可以接着执行了。
5、Try操作都已完成,资源已经冻结,在第三步中库存服务Confirm成功,库存做了扣减, 但是支付服务挂掉了,余额还处于冻结状态, 怎么办?
那可以多尝试几次, 让支付服务做Confirm操作(很明显,这个Confirm操作必须得是一个幂等操作才行)。如果实在是无法成功,那就可以让库存服务做Cancel操作。 如果还是不行,只有让人工介入了。
四、实现幂等操作
可以使用一个唯一的流水号ID,用来标识是不是同一个请求或者交易。这种ID通常都需要具备全局唯一性。假设让客户端来生成这个ID,每个创建订单的请求生成一个唯一的ID。
先将这个ID保存到一个流水表里面,并且流水表中将这个ID设置为UNIQUE KEY,如果插入出现冲突了,则说明这个创建订单的请求已经处理过了,直接返回之前的操作结果。
- 唯一索引或唯一组合索引来防止新增数据存在脏数据
- token机制(要申请一次有效,可限流),防止页面重复提交
- 使用锁(悲观锁、乐观锁、分布式锁等)乐观锁的更新操作,最好用主键或者唯一索引来更新,这样是行锁,否则更新时会锁表。某个长流程处理过程要求不能并发执行,可以在流程执行之前根据某个标志(用户ID+后缀等)获取分布式锁,其他流程执行时获取锁就会失败,也就是同一时间该流程只能有一个能执行成功,执行完成后,释放分布式锁(分布式锁要第三方系统提供)
- 状态幂等机在设计单据相关的业务,或者是任务相关的业务,肯定会涉及到状态机(状态变更图),就是业务单据上面有个状态,状态在不同的情况下会发生变更,一般情况下存在有限状态机,这时候,如果状态机已经处于下一个状态,这时候来了一个上一个状态的变更,理论上是不能够变更的,这样的话,保证了有限状态机的幂等。
- 对外提供接口为了支持幂等调用,接口有两个字段必须传,一个是来源source,一个是来源方序列号seq,这个两个字段在提供方系统里面做联合唯一索引,这样当第三方调用时,先在本方系统里面查询一下,是否已经处理过,返回相应处理结果;没有处理过,进行相应处理,返回结果。
五、Base原则
1、数据库 ACID,都不陌生:原子性、一致性、隔离性和持久性;保证了 ACID,效率就会大幅度下降,更要命的是,这么高的要求,不好扩展。因此有了CAP原则。
2、CAP 原则(Consistency(一致性)、Availability(可用性)、Partition tolerance(分区容错性));
3、BASE 原则(Basically Available(基本可用)、Soft state(软状态)、Eventually consistent(最终一致)),BASE 原则对 CAP 原则的进一步诠释。
3、数据库厂商在很久以前就认识到数据库分区的必要性,并引入了一种称为2PC(两阶段提交)的技术来提供跨越多个数据库实例的ACID保证.这个协议分为以下两个阶段:
- 第一阶段,事务协调器要求每个涉及到事务的数据库预提交(precommit)此操作,并反映是否可以提交.
- 第二阶段,事务协调器要求每个数据库提交数据.
强一致
当更新操作完成之后,任何多个后续进程或者线程的访问都会返回最新的更新过的值。这种是对用户最友好的,就是用户上一次写什么,下一次就保证能读到什么。根据 CAP 理论,这种实现需要牺牲可用性。
弱一致性
系统并不保证续进程或者线程的访问都会返回最新的更新过的值。系统在数据写入成功之后,不承诺立即可以读到最新写入的值,也不会具体的承诺多久之后可以读到。
最终一致性
弱一致性的特定形式。系统保证在没有后续更新的前提下,系统最终返回上一次更新操作的值。在没有故障发生的前提下,不一致窗口的时间主要受通信延迟,系统负载和复制副本的个数影响。DNS 是一个典型的最终一致性系统。
在工程实践上,为了保障系统的可用性,互联网系统大多将强一致性需求转换成最终一致性的需求,并通过系统执行幂等性的保证,保证数据的最终一致性。
六、保证分布式系统数据一致性
第一种方案:经典方案 - eBay 模式
此方案的核心是将需要分布式处理的任务通过消息日志的方式来异步执行。消息日志可以存储到本地文本、数据库或消息队列,再通过业务规则自动或人工发起重试。人工重试更多的是应用于支付场景,通过对账系统对事后问题的处理。
消息日志方案的核心是保证服务接口的幂等性。
考虑到网络通讯失败、数据丢包等原因,如果接口不能保证幂等性,数据的唯一性将很难保证。
BASE 的可用性是通过支持局部故障而不是系统全局故障来实现的。
基于以上方法,在第一阶段,通过本地的数据库的事务保障,增加了 transaction 表及消息队列 。
在第二阶段,分别读出消息队列(但不删除),通过判断更新记录表 updates_applied 来检测相关记录是否被执行,未被执行的记录会修改 user 表,然后增加一条操作记录到 updates_applied,事务执行成功之后再删除队列。
通过以上方法,达到了分布式系统的最终一致性。
第二种方案:支付宝及蚂蚁金融云的分布式服务 DTS 方案
分布式事务服务简介
分布式事务服务 (Distributed Transaction Service, DTS) 是一个分布式事务框架,用来保障在大规模分布式环境下事务的最终一致性。DTS 从架构上分为 xts-client 和 xts-server 两部分,前者是一个嵌入客户端应用的 JAR 包,主要负责事务数据的写入和处理;后者是一个独立的系统,主要负责异常事务的恢复。
核心特性
传统关系型数据库的事务模型必须遵守 ACID 原则。在单数据库模式下,ACID 模型能有效保障数据的完整性,但是在大规模分布式环境下,一个业务往往会跨越多个数据库,如何保证这多个数据库之间的数据一致性,需要其他行之有效的策略。在 JavaEE 规范中使用 2PC (2 Phase Commit, 两阶段提交) 来处理跨 DB 环境下的事务问题,但是 2PC 是反可伸缩模式,也就是说,在事务处理过程中,参与者需要一直持有资源直到整个分布式事务结束。这样,当业务规模达到千万级以上时,2PC 的局限性就越来越明显,系统可伸缩性会变得很差。基于此,我们采用 BASE 的思想实现了一套类似 2PC 的分布式事务方案,这就是 DTS。DTS在充分保障分布式环境下高可用性、高可靠性的同时兼顾数据一致性的要求,其最大的特点是保证数据最终一致 (Eventually consistent)。
简单的说,DTS 框架有如下特性:
- 最终一致:事务处理过程中,会有短暂不一致的情况,但通过恢复系统,可以让事务的数据达到最终一致的目标。
- 协议简单:DTS 定义了类似 2PC 的标准两阶段接口,业务系统只需要实现对应的接口就可以使用 DTS 的事务功能。
- 与 RPC 服务协议无关:在 SOA 架构下,一个或多个 DB 操作往往被包装成一个一个的 Service,Service 与 Service 之间通过 RPC 协议通信。DTS 框架构建在 SOA 架构上,与底层协议无关。
- 与底层事务实现无关: DTS 是一个抽象的基于 Service 层的概念,与底层事务实现无关,也就是说在 DTS 的范围内,无论是关系型数据库 MySQL,Oracle,还是 KV 存储 MemCache,或者列存数据库 HBase,只要将对其的操作包装成 DTS 的参与者,就可以接入到 DTS 事务范围内。
实现过程:
- 一个完整的业务活动由一个主业务服务与若干从业务服务组成。
- 主业务服务负责发起并完成整个业务活动。
- 从业务服务提供 TCC 型业务操作。
- 业务活动管理器控制业务活动的一致性,它登记业务活动中的操作,并在活动提交时确认所有的两阶段事务的 confirm 操作,在业务活动取消时调用所有两阶段事务的 cancel 操作。(利用TCC机制)
TCC机制:Try(判断是否满足条件,冻结资源) - Confirm(验证资源) -Cancel(失败,恢复资源),简称TCC。
与 2PC 协议比较
- 没有单独的 Prepare 阶段,降低协议成本
- 系统故障容忍度高,恢复简单


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











