







weight_decay越大越好的原因
研究发生的问题特此记录
之前在用神经网络来做一个回归问题,回归的数值范围是0~1之间。然后进行网格搜参(搜索最好的weight_decay和学习率)的时候发现一个不合常理的现象,就是一般往往最好的weight_decay 一般是很小的一个数值(0.001或者0.0001),但是我的最优weight_decay反而很大,这就给我造成很大的困扰,还好经过一番探索,最终锁定了问题,下面我将一一道来
现象
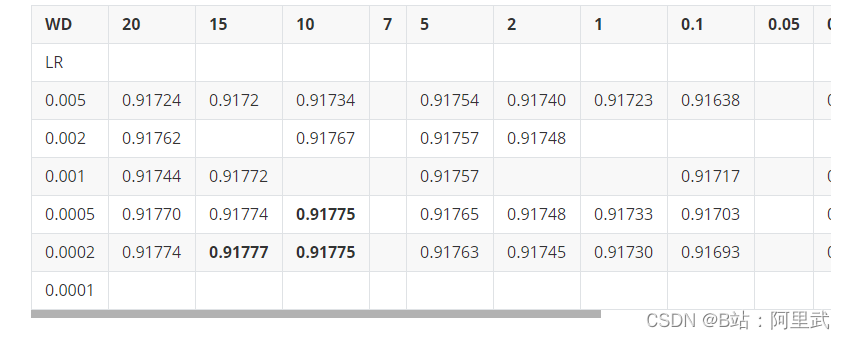
发现weight_decay 取得一个比较大的值的时候 模型效果最好
分析
这显然是不合理的 weight _decay 往往是小于1, 一般取10^-3 这种数量级 没道理这么大,而且最好的结果出现在这里显然是不合常理的
原因
首先weight _decay本质上是一个L2正则化系数
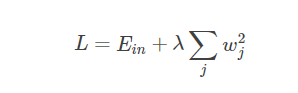
可以理解为加上这个L2正则化,会限制模型的权重都会趋近于0(理解就是当w趋近与0时, w平方和 会小, 模型损失也会变小),而weight_decay的大小就是公式中的λ,可以理解为λ越大,优化器就越限制权重变得趋近与0
这里重点注意
由于我模型最后输出的是一个0~1的结果,而神经网络的最后一次输出是一个 权重之和,这就要求我们得到的权重必然是要比较小的才能符合输出结果
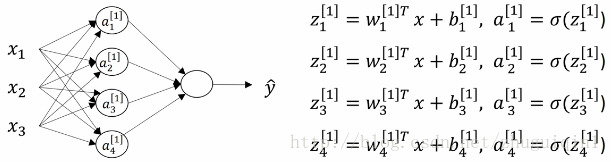
也就是图中的w1 w2 w3 w4 要趋近于0, 这样加权值才会比较小
实验分析
经过上面的原理分析, 于是我做了下面两组实验
当weight_decay 设置为1时, 模型的参数迭代如下
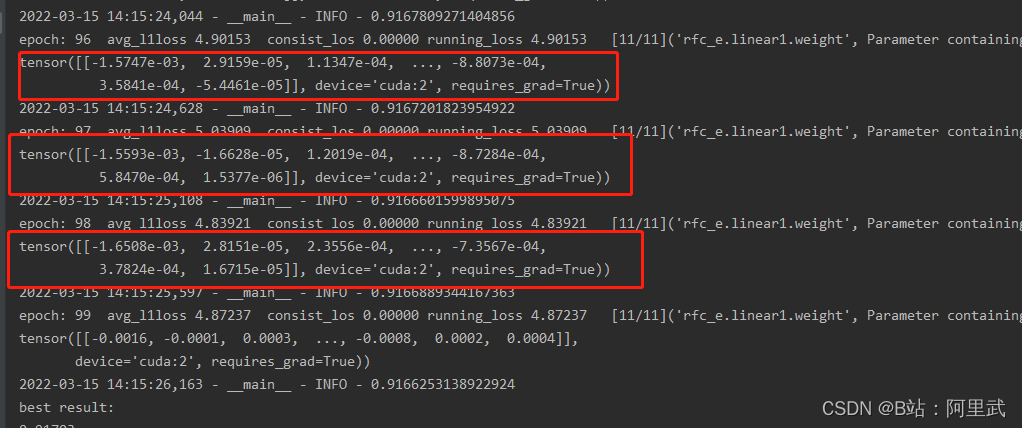
当weight_decay 设置为0.001时, 模型的参数迭代如下

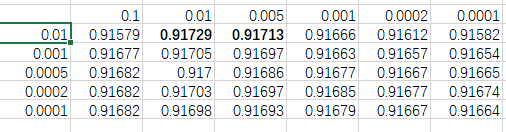
可以明显看出 weight_decay 越大, 模型权重则会在训练地越小,这说明在我们模型中确实需要设置这么大的weight_decay
但是我查看发现竟然需要是的权重变成10^-4 次方,是不是有点过于小了, 我通过全连接层计算,理论上也就是只有1500个权重和,乘上10的-4次方的权重 范围反而应该小于0.15。而且其他这样做也没有出现这么大的weight_decay。
经过查找。我最终发现了原因,原因是在真实值输入的时候,为了使得loss更大一点,我将每个真实值都放大100倍,也就是说输出的范围是0~100, 这就更加加重了我模型需要学习到更趋近于0的权重, 也可以和我前面分析出权重为什么过于小对于上来, 问题解决!
总结
最终问题是解决了 ,将模型放缩100取消后,weight_decay也成为了一个正常值
教训是
-
别瞎改改输出格式
-
从公式根源出发 寻找问题
-
学会打印模型参数来查问题
-
神经网络不好做回归, 使得权重很小
-
或许多加几层 由于层数的增加使得输出变小,可能会缓解这种问题
其实也是一种启发: 神经网络做回归,需要考虑权重问题,不能像做传统分类问题一样,因为传统分类会经过sigmoid函数来进行概率变换,
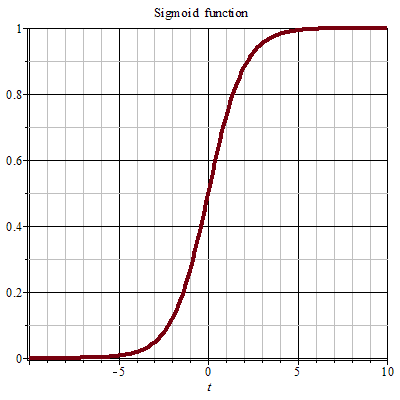
就算很大或者很小的输出值, 也会被合理的放缩到0~1之间,不用考虑权重值过大或过小的问题














 5015
5015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









