







背景:
赛题数据由约62万条训练集、20万条测试集数据组成,共包含13个字段。其中uuid为样本唯一标识,eid为访问行为ID,udmap为行为属性,其中的key1到key9表示不同的行为属性,如项目名、项目id等相关字段,common_ts为应用访问记录发生时间(毫秒时间戳),其余字段x1至x8为用户相关的属性,为匿名处理字段。target字段为预测目标,即是否为新增用户。
比赛链接: https://challenge.xfyun.cn/topic/info?type=subscriber-addition-prediction&option=ssgy
用户新增预测挑战赛(讯飞) 高分baseline:0.85+,前10%代码
EDA部分:
原始数据:
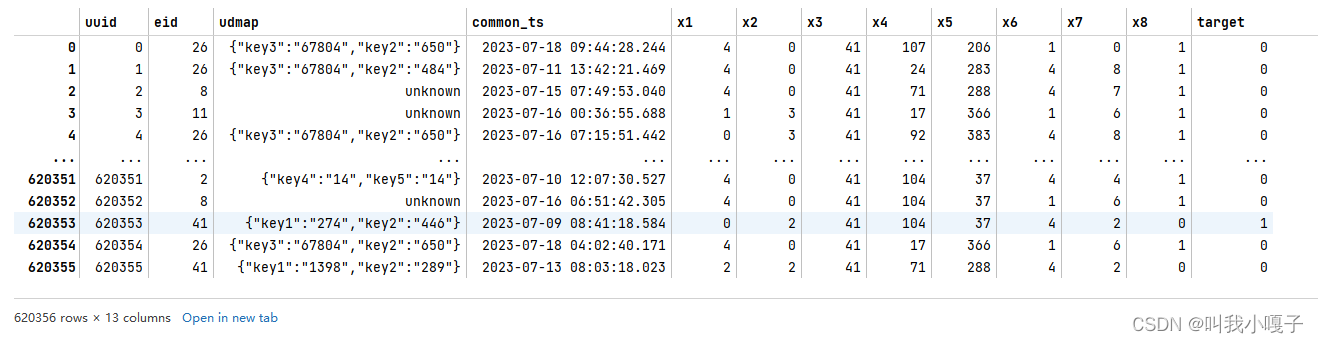
可以看到原始数据包含60w+行数据,共13列数据;
数据初步统计
def resumetable(df):
print(f"Dataset Shape: {df.shape}")
summary = pd.DataFrame(df.dtypes,columns=['dtypes'])
summary = summary.reset_index()
summary['Name'] = summary['index']
summary = summary[['Name','dtypes']]
summary['Missing'] = df.isnull().sum().values
summary['Uniques'] = df.nunique().values
summary['First Value'] = df.loc[0].values
summary['Second Value'] = df.loc[1].values
summary['Third Value'] = df.loc[2].values
for name in summary['Name'].value_counts().index:
summary.loc[summary['Name'] == name, 'Entropy'] = round(stats.entropy(df[name].value_counts(normalize=True), base=2),2)
return summary
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vntu6CZh-1692781371104)(C:\Users\1212214\AppData\Roaming\Typora\typora-user-images\image-20230823163553104.png)]](https://img-blog.csdnimg.cn/3f0760d9988a43109bab6dfa7b212132.png)
针对数据名、类型、缺失情况、数值个数等进行统计分析,了解数据的总体分布;
相关思考:
- eid|x1|x2|x3|x4|x6|x6|x8 的个数在100左右,可以认为是类比变量,x5认为是连续性变量;
- 发现common_ts 为时间变量,后续可以提取相关数据特征;
- udmap可以拆分获取每个key的数值作为单独的特征列,进行模型的训练;
数据处理函数
1.此为处理udmap 的函数,用于拆分各个key;
def udmap_onethot(d):
v = np.zeros(9)
if d == 'unknown':
return v
d = eval(d)
for i in range(1, 10):
if 'key' + str(i) in d:
v[i-1] = d['key' + str(i)]
return v
train_udmap_df = pd.DataFrame(np.vstack(train_data['udmap'].apply(udmap_onethot)))
test_udmap_df = pd.DataFrame(np.vstack(test_data['udmap'].apply(udmap_onethot)))
train_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
test_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
train_data
2.此为获取时间特征代码(小时/天)
train_data['common_ts_hour'] = train_data['common_ts'].dt.hour
test_data['common_ts_hour'] = test_data['common_ts'].dt.hour
train_data['common_ts_day'] = train_data['common_ts'].dt.day
test_data['common_ts_day'] = test_data['common_ts'].dt.day
可视化分析
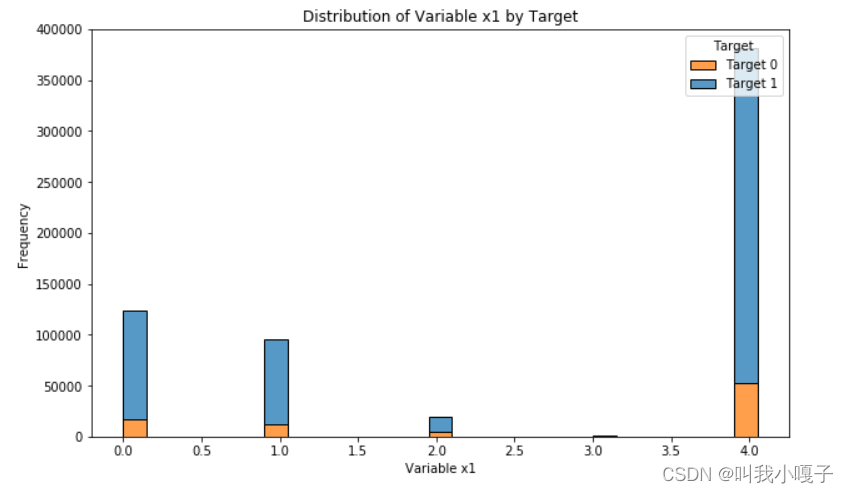
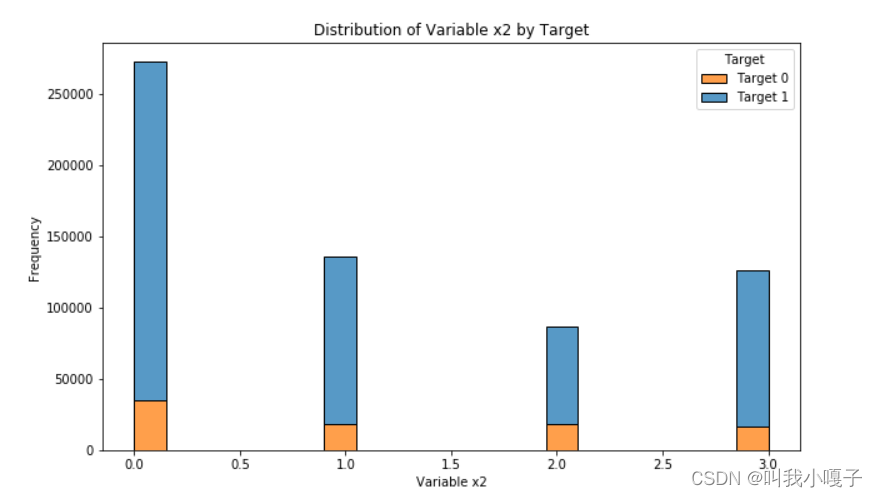
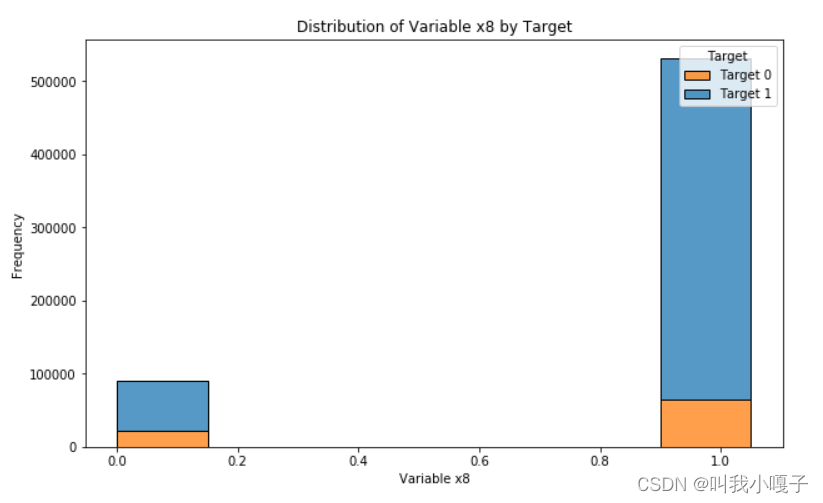
代码链接:https://github.com/guoliangxie123/competition_2023/blob/main/best_lgb_home.ipynb















 1709
1709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









