







文章目录
逻辑回归 (Logistic Regression)
问题的引出
假设使用线性回归来解决分类问题
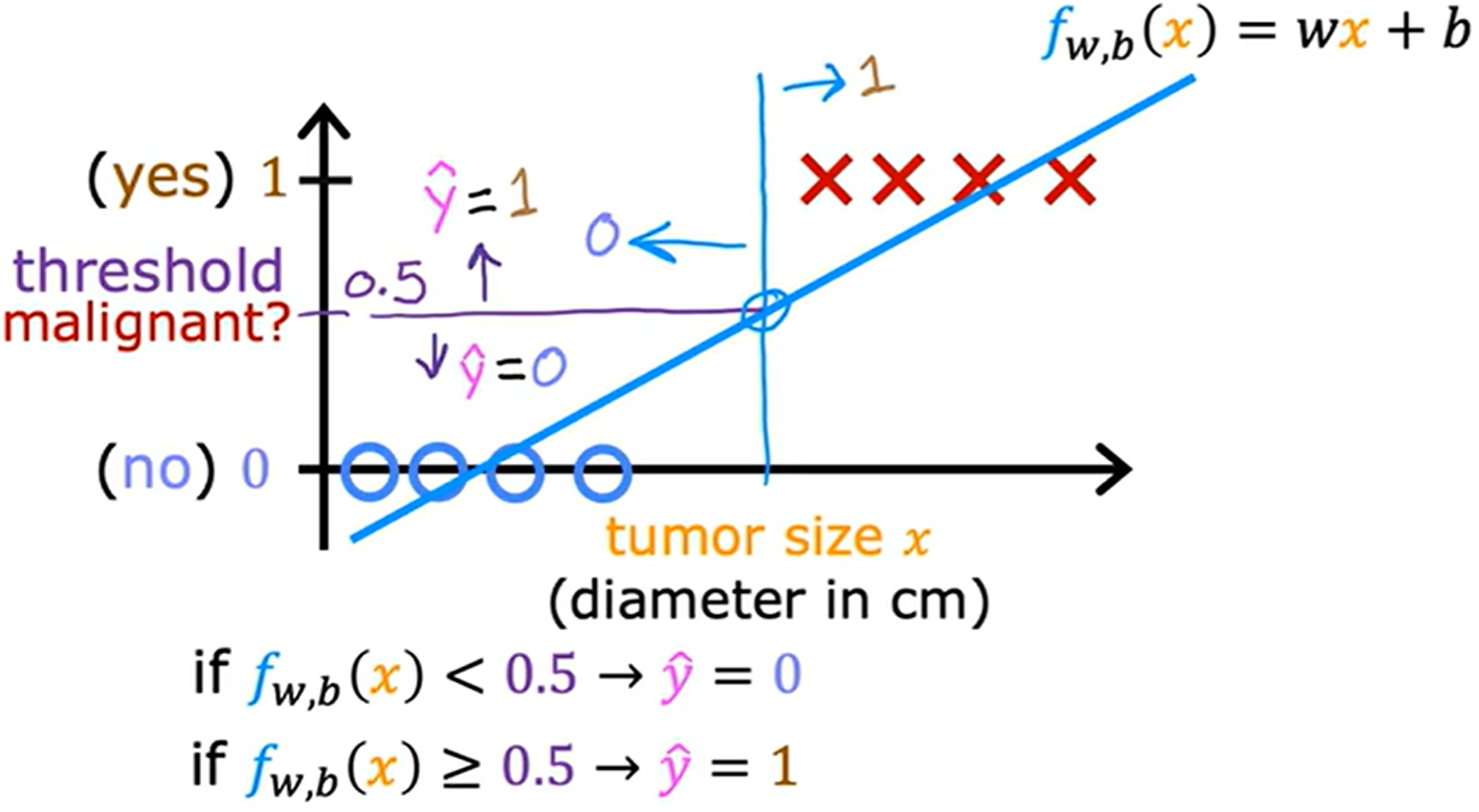
看起来还不错,但若是沿横轴正方向的远处加入训练样本,就会导致线性回归的拟合线偏移,如下图所示。
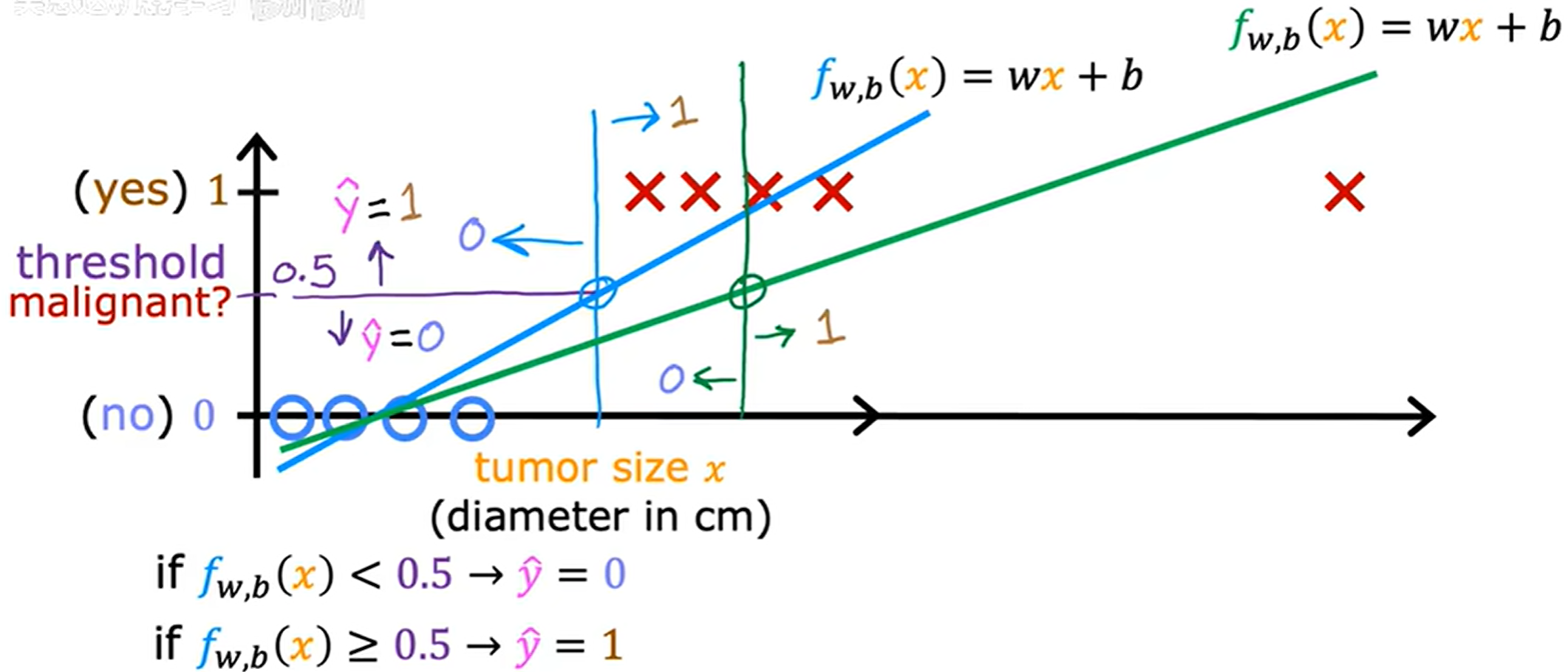
图中决策边界右移,这样就会导致先前的部分训练样本预测值从 yes 变为 no。
整个模型变的很糟糕。
分类问题的目标是找到一个决策边界,能够正确区分不同类别的样本。理想情况下,决策边界应该由靠近边界的样本(支持向量)决定,而不是由远处的样本点决定。
在分类问题中,增加新的训练样本(尤其是远离决策边样的样本)不应显著改变原有的分类结论。
由此引入逻辑回归来解决分类问题。
Sigmoid function
为了更好拟合训练样本,整个线条呈现 s 型,由此引入 Sigmoid function(又常称为 logistic函数)。
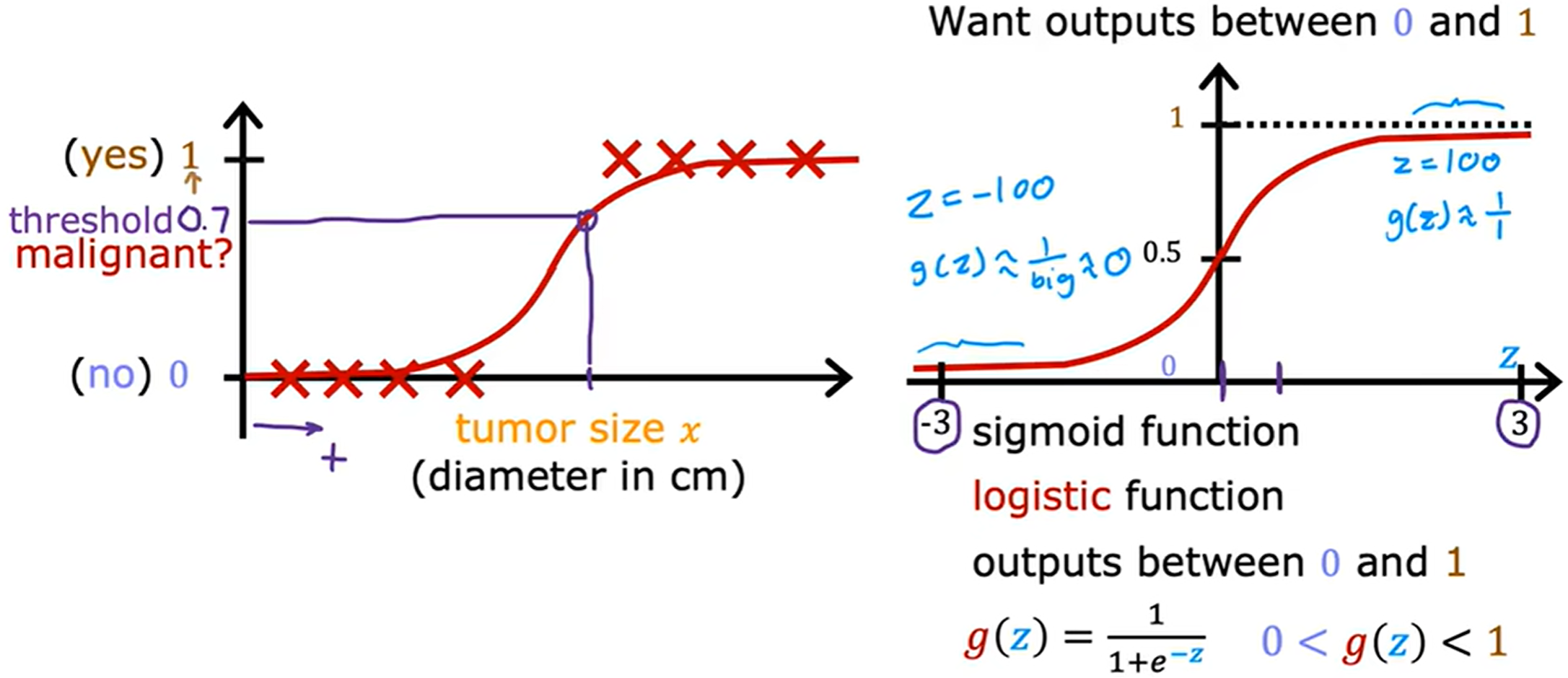
Sigmoid函数,又称logistic函数,是最早使用的激活函数之一。但是由于其固有存在的一些缺点,如今很少将其作为激活函数,但是依然常用于二分类问题中的概率划分。
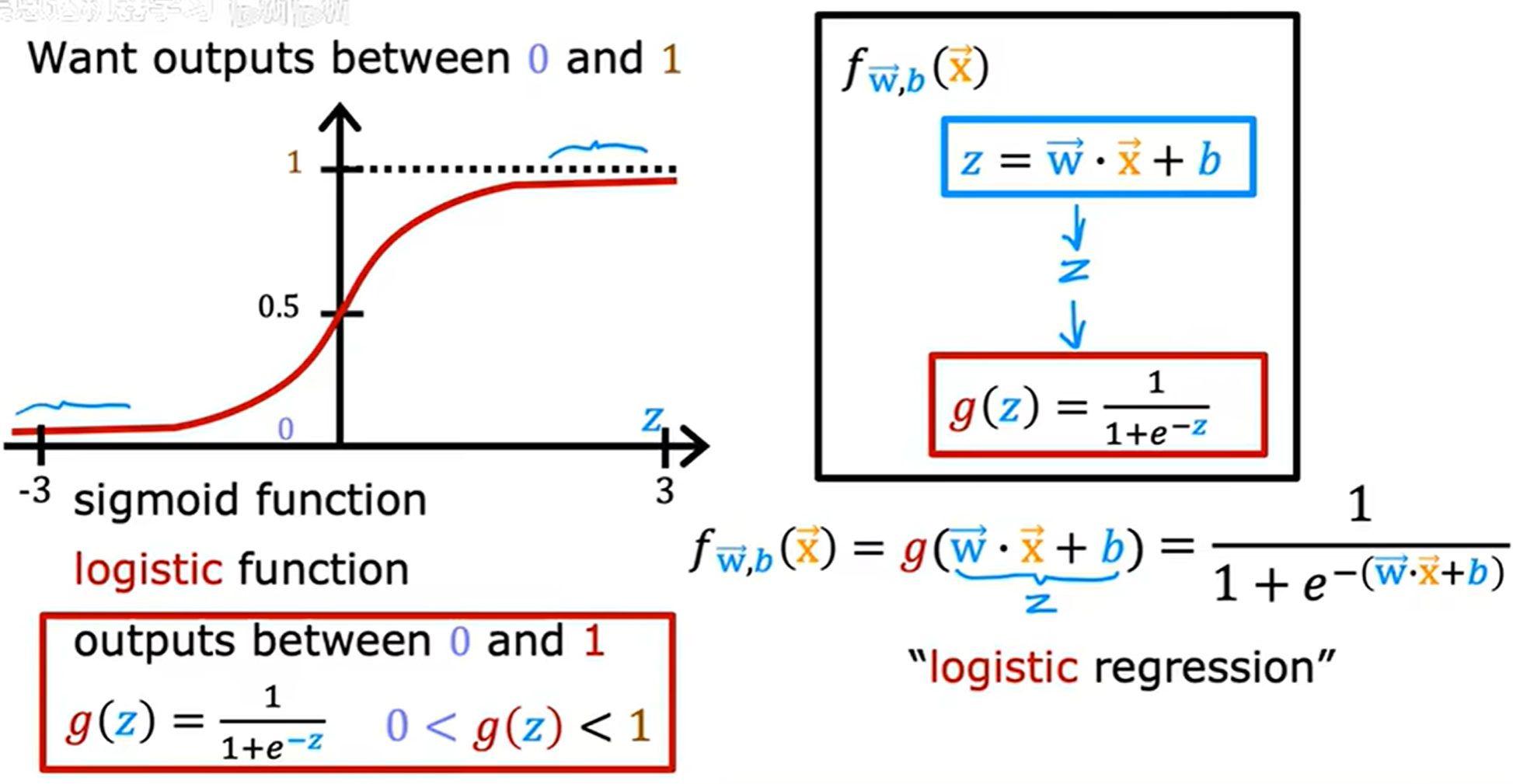
将线性回归的结果,通过sigmoid函数转换到0-1的范围,实现分类。
逻辑回归的解释

f
w
⃗
,
b
(
x
⃗
)
=
P
(
y
=
1
∣
x
⃗
;
w
⃗
,
b
)
f_{\vec{w}, b}(\vec{x}) = P(y = 1|\vec{x};\vec{w},b)
fw,b(x)=P(y=1∣x;w,b)
表示为给定输入特征为
x
x
x,
y
y
y 等于
1
1
1 的概率。
(given x, and with parameters w and b)
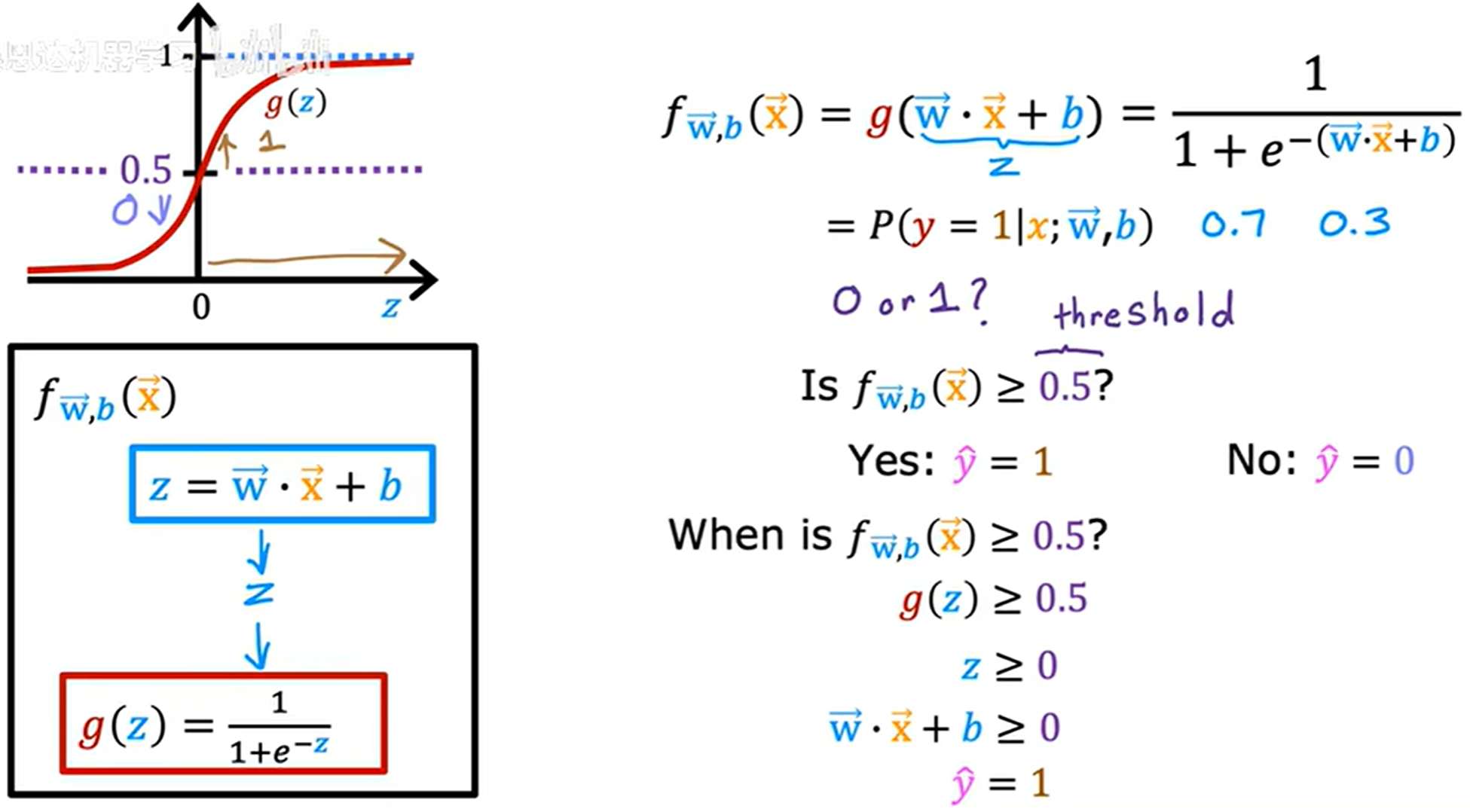
threshold 阈值
通过与阈值进行比较来决定 y ^ \hat{y} y^ 为 0 0 0 还是 1 1 1,通常将 0.5 0.5 0.5 作为阈值。
决策边界 (Decision boundary)
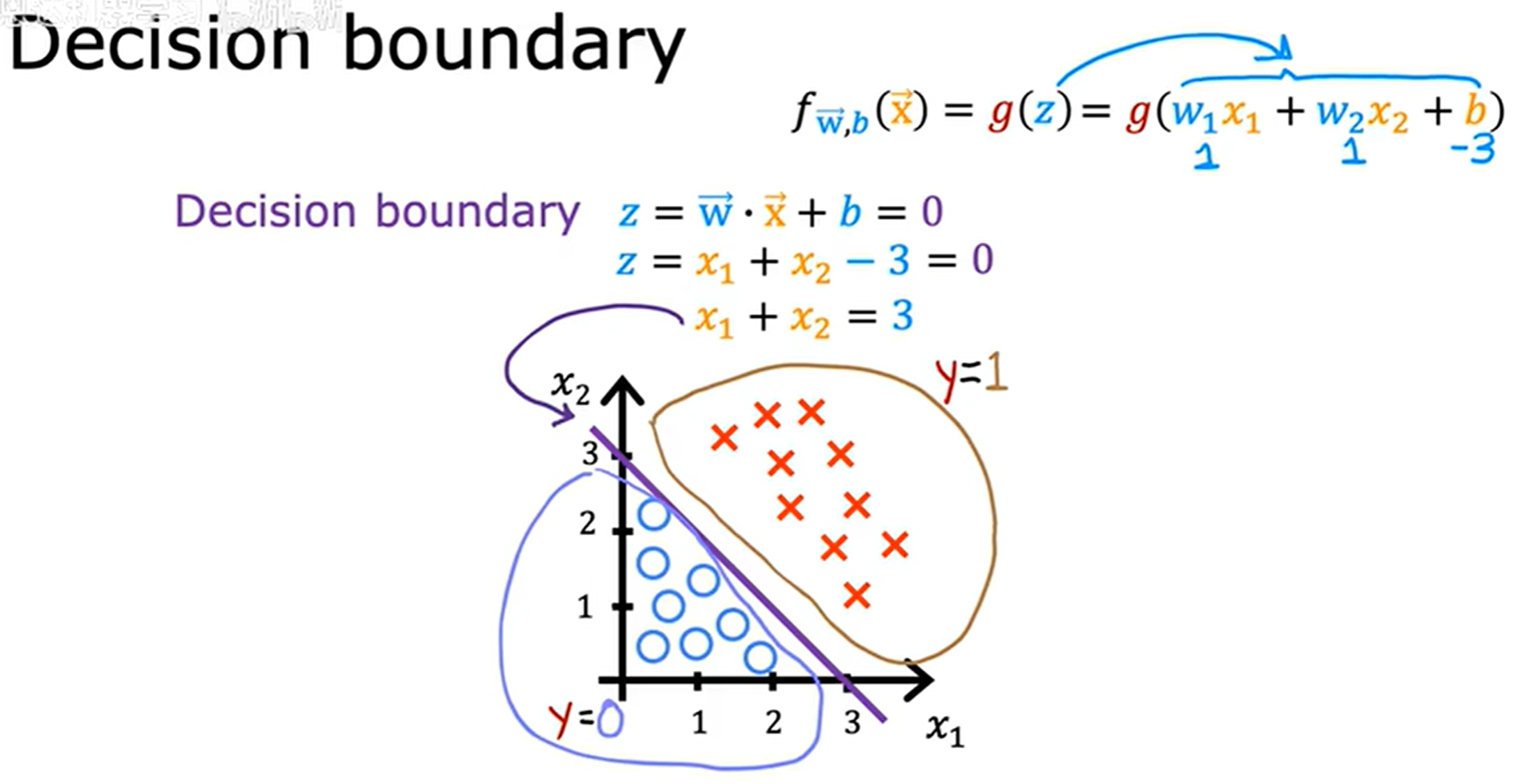
决策边界便是让 z = 0 z = 0 z=0 的地方,在这里设 w ⃗ = [ 1 , 1 ] \vec{w} = [1, 1] w=[1,1],由此令 z = 0 z = 0 z=0,则 x 1 + x 2 = 3 x_1 + x _ 2 = 3 x1+x2=3,在这个例子中通过线性规划可以做出对应的直线,如上图所示。
决策边界也不一定是直线,通过前面学过的多项式回归,可以得到下图关系。

先通过梯度下降算法对样本拟合出曲线或者曲面或者更高纬度,然后对其进行分类。

通过多项式特征,可以获得非常复杂的决策边界,换句话说逻辑回归可以拟合非常复杂的数据。
逻辑回归的代价函数

线性回归中,通过平方误差作为代价函数来决定 w ⃗ \vec{w} w 和 b b b 的取值,同理逻辑回归也可以去寻找对应的代价函数来决定 w ⃗ \vec{w} w 和 b b b 的取值。
convex function 下凸函数
concave function 上凸函数
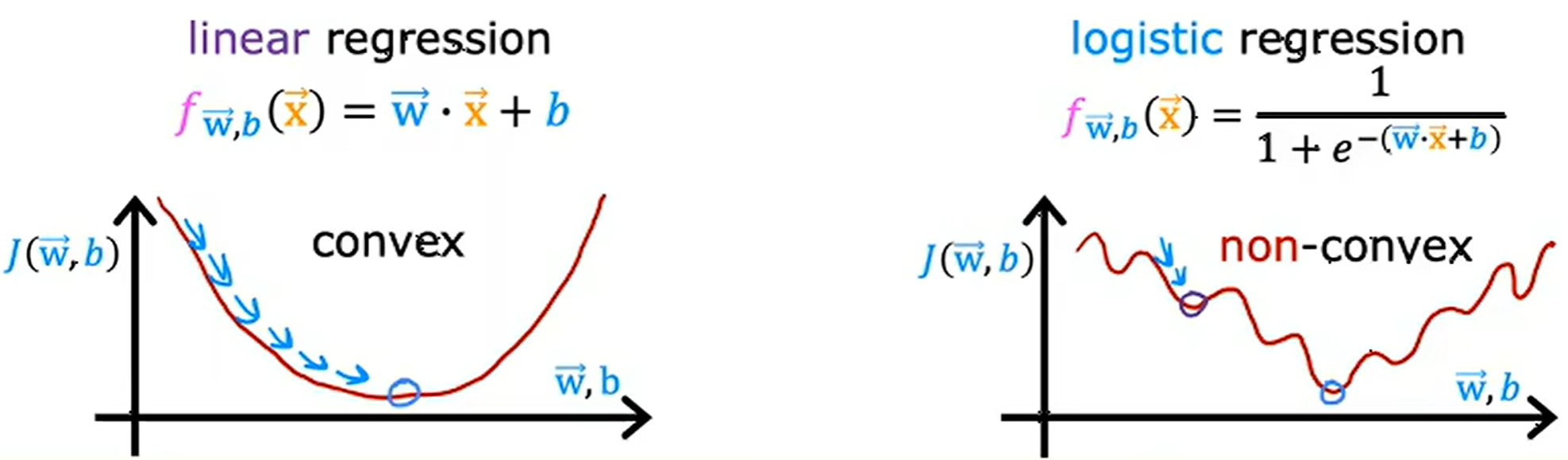
如果同样使用前面平方误差作为代价函数的话,从上图结果来看,这将导致代价函数为非下凸函数 (non-convex function),使用梯度下降会导致很容易陷入局部最小值,而非全局最小值。因此,平方误差代价函数对于逻辑回归并不是一个好的选择。
将以下符号称为单个训练实例的损失 (loss)。
L
(
f
w
⃗
,
b
(
x
⃗
(
i
)
)
,
y
(
i
)
)
L(f_{\vec{w}, b}(\vec{x}^{(i)}), y^{(i)})
L(fw,b(x(i)),y(i))
例如,在之前学到的线性回归中,代价函数形式如下。
J
(
w
,
b
)
=
1
2
m
∑
i
=
1
m
(
y
^
(
i
)
−
y
(
i
)
)
2
J(w, b) = \frac{1}{2m} \sum_{i=1}^m (\hat y^{(i)} - y^{(i)}) ^ 2
J(w,b)=2m1i=1∑m(y^(i)−y(i))2
因此单个训练实例的损失定义如下。(
1
2
\frac{1}{2}
21 要提到内部单项)
L
(
f
w
⃗
,
b
(
x
⃗
(
i
)
)
,
y
(
i
)
)
=
1
2
(
f
w
⃗
,
b
(
x
⃗
(
i
)
)
−
y
⃗
(
i
)
)
L(f_{\vec{w}, b}(\vec{x}^{(i)}), y^{(i)}) = \frac{1}{2}(f_{\vec{w}, b}(\vec{x}^{(i)}) - \vec{y}^{(i)})
L(fw,b(x(i)),y(i))=21(fw,b(x(i))−y(i))
另外可以得到,以下定义。
J
(
w
,
b
)
=
1
m
∑
i
=
1
m
L
(
f
w
⃗
,
b
(
x
⃗
(
i
)
)
,
y
(
i
)
)
J(w, b) = \frac{1}{m} \sum_{i = 1}^{m}L(f_{\vec{w}, b}(\vec{x}^{(i)}), y^{(i)})
J(w,b)=m1i=1∑mL(fw,b(x(i)),y(i))
这里选用以下函数作为逻辑回归的代价函数,感觉是一种针对sigmoid函数的
e
x
e^x
ex 的特殊构造。
L
(
f
w
⃗
,
b
(
x
⃗
(
i
)
)
,
y
(
i
)
)
=
{
−
log
(
f
w
⃗
,
b
(
x
⃗
(
i
)
)
)
i
f
y
(
i
)
=
1
−
log
(
1
−
f
w
⃗
,
b
(
x
(
i
)
)
)
i
f
y
(
i
)
=
0
L(f_{\vec{w}, b}(\vec{x}^{(i)}), y^{(i)}) = \begin{cases} -\log(f_{\vec{w}, b}(\vec{x}^{(i)})) &if \quad y^{(i)} = 1\\ -\log (1 - f_{\vec{w}, b}(x^{(i)})) &if \quad y^{(i)} = 0 \end{cases}
L(fw,b(x(i)),y(i))={−log(fw,b(x(i)))−log(1−fw,b(x(i)))ify(i)=1ify(i)=0
称为二分类交叉熵损失(Binary Cross-Entropy, BCE)
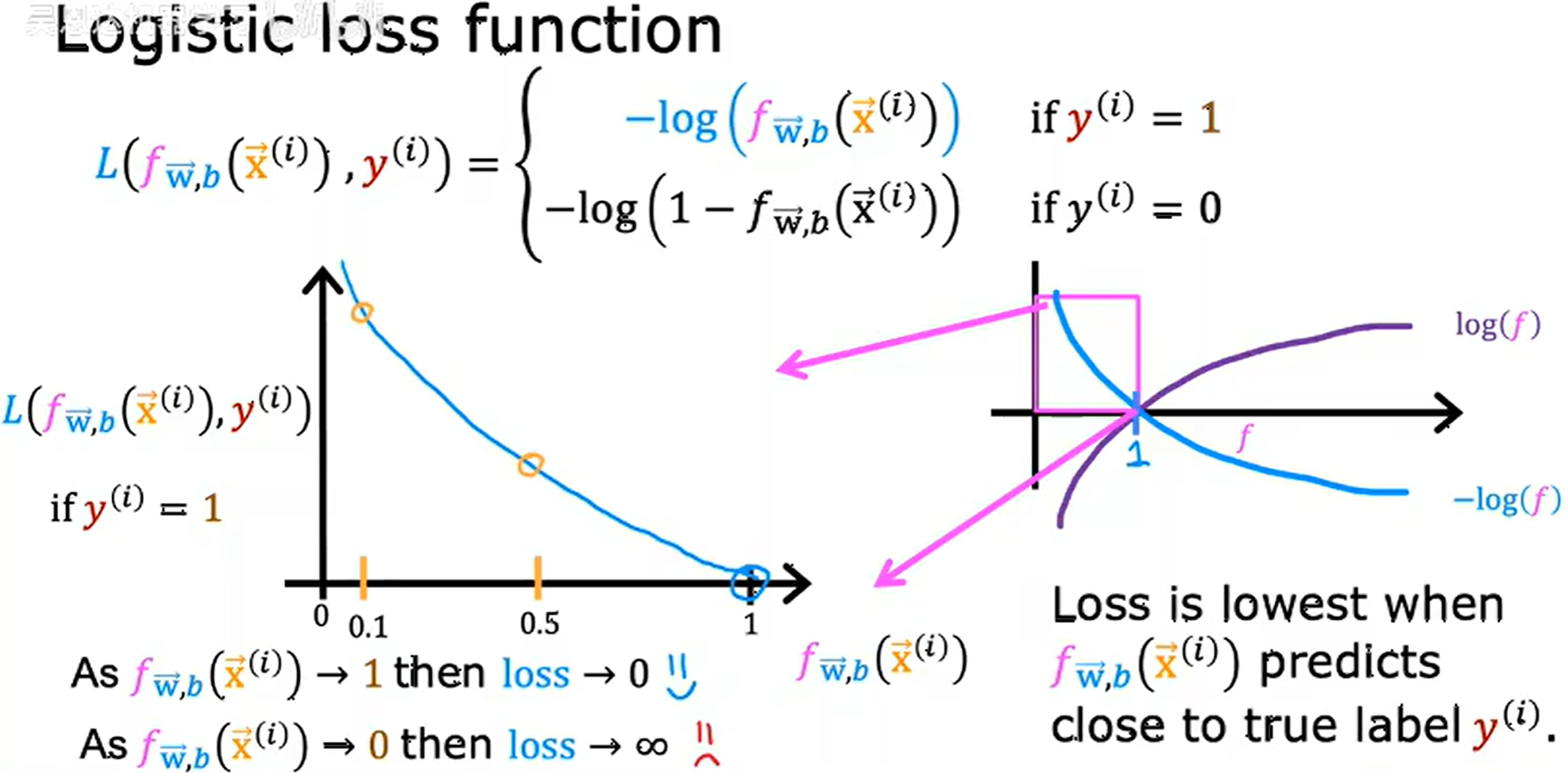
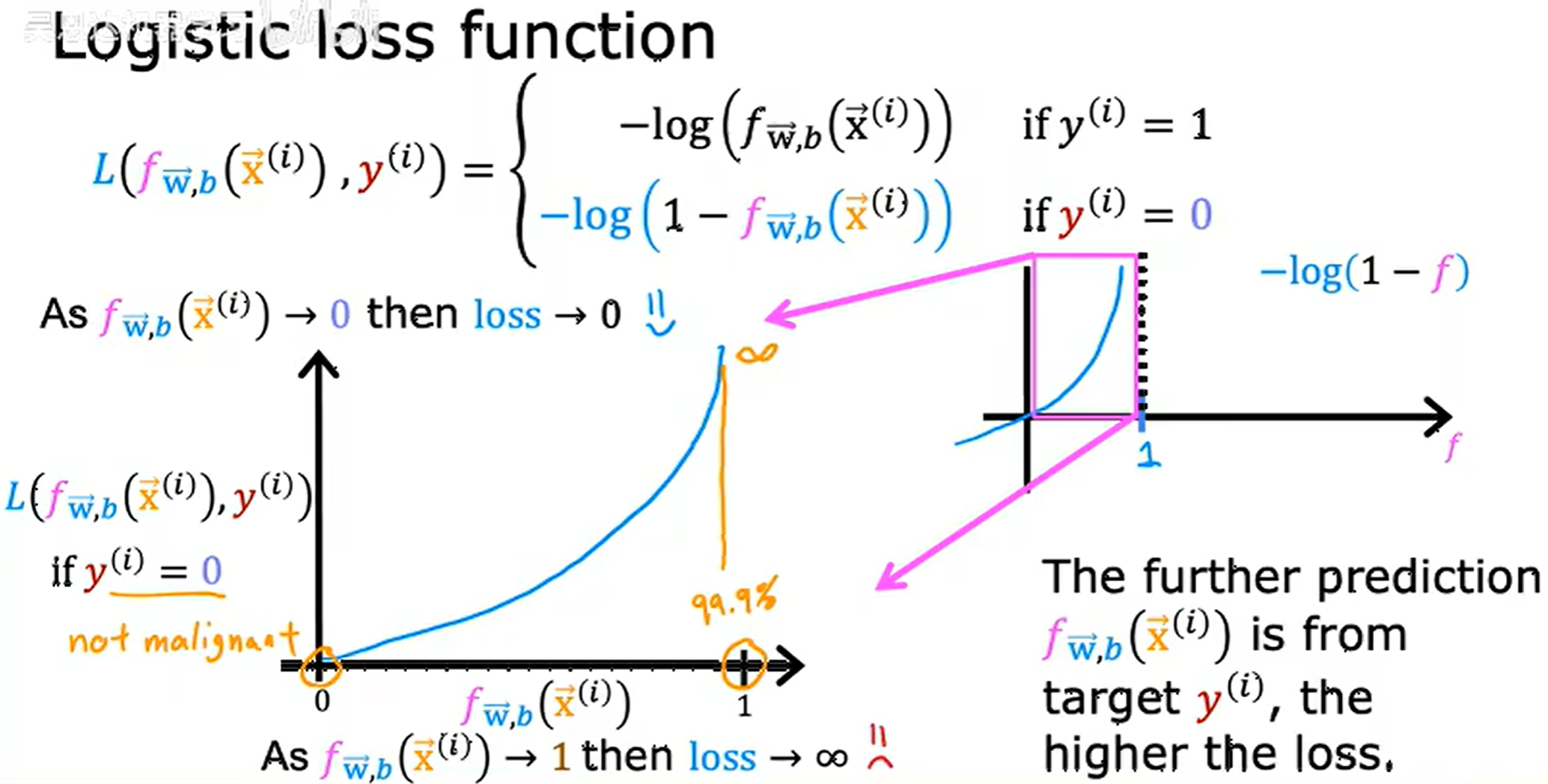
如果模型预测 99.9% 的概率为恶性肿瘤,但是结果为非恶性肿瘤,loss 就会非常高用来惩罚模型。
用原来的平方和的损失函数导致在逻辑回归情况下,函数是非凹非凸的,会落入局部最小值。两个拆开的凸函数达到局部最优,也就是整体的全局最优,而改用为这个,把逻辑回归分为训练事例 y y y 的真实值为 0 0 0,为 1 1 1,依据log形成两个拆开的凸函数。

事实证明选择这个损失函数,整体函数为下凸函数 (convex function),这个构型是高斯误差方程。
机器学习中代价函数的设计
1. 代价函数的来源
(1)从概率模型推导而来(统计学习视角)
- 核心思想:假设数据服从某种概率分布,通过极大似然估计(MLE) 或 最大后验估计(MAP) 推导出损失函数。
- 典型例子:
- 均方误差(MSE):假设噪声服从高斯分布(线性回归)。
- 交叉熵损失:假设标签服从伯努利/多项分布(逻辑回归、Softmax分类)。
- 泊松损失:假设数据服从泊松分布(计数数据回归)。
- 为什么有效:
这类损失函数天然具备概率解释,优化它们等价于最大化数据似然或后验概率。
(2)直接针对算法目标设计(优化视角)
- 核心思想:不依赖概率假设,而是直接定义优化目标(如间隔最大化、稀疏性等)。
- 典型例子:
- Hinge Loss(SVM):目标是最大化分类间隔,无显式概率模型。
- 0-1损失:直接优化分类错误率(但不可导,实际常用替代损失)。
- 自定义损失:如Focal Loss(解决类别不平衡)、Huber Loss(鲁棒回归)。
- 为什么有效:
这些函数直接反映算法的核心目标(如分类准确性、鲁棒性),即使没有概率解释。
2. 代价函数与算法的适配性
不同算法使用不同的代价函数,因为它们的目标和假设不同:
| 算法 | 典型代价函数 | 设计依据 |
|---|---|---|
| 线性回归 | 均方误差(MSE) | 高斯噪声假设 + MLE |
| 逻辑回归 | 交叉熵损失 | 伯努利分布 + MLE |
| 支持向量机(SVM) | Hinge Loss | 最大化分类间隔(几何目标) |
| 决策树 | 基尼系数/信息增益 | 分割纯度的直接度量 |
| 神经网络 | 多种(MSE/交叉熵等) | 根据任务选择(回归/分类) |
总结
- 回归问题:常用MSE(高斯假设)、MAE(拉普拉斯假设)、Huber Loss(鲁棒性)。
- 分类问题:常用交叉熵(概率校准)、Hinge Loss(间隔最大化)。
- 特定需求:如类别不平衡用Focal Loss,稀疏性用L1正则。
逻辑回归的简化代价函数

合并二分类交叉熵损失(Binary Cross-Entropy, BCE)
L ( f w ⃗ , b ( x ⃗ ( i ) ) , y ( i ) ) = − y ( i ) log ( f w ⃗ , b ( x ⃗ ( i ) ) ) − ( 1 − y ( i ) ) log ( 1 − f w ⃗ , b ( x ( i ) ) ) L(f_{\vec{w}, b}(\vec{x}^{(i)}), y^{(i)}) = -y ^{(i)} \log(f_{\vec{w}, b}(\vec{x}^{(i)})) - (1 - y ^{(i)}) \log (1 - f_{\vec{w}, b}(x^{(i)})) L(fw,b(x(i)),y(i))=−y(i)log(fw,b(x(i)))−(1−y(i))log(1−fw,b(x(i)))

梯度下降实现


上述求导中,将 log \log log 默认看为了 ln \ln ln 然后进行。

上述形式看起来很像线性回归所求的,但是注意 f w ⃗ , b ( x ⃗ ( i ) ) f_{\vec{w}, b}(\vec{x}^{(i)}) fw,b(x(i)) 已经发生了改变。

















 1161
1161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









