 深度学习环境搭建指南
深度学习环境搭建指南





 本文详细介绍了深度学习环境的搭建过程,包括CUDA、cuDNN、PyTorch、jieba和Gensim等关键库的安装与验证。从CUDA和cuDNN的基础安装到PyTorch的环境配置,再到jieba和Gensim的中文处理能力,全面覆盖了深度学习项目启动所需的各种步骤。
本文详细介绍了深度学习环境的搭建过程,包括CUDA、cuDNN、PyTorch、jieba和Gensim等关键库的安装与验证。从CUDA和cuDNN的基础安装到PyTorch的环境配置,再到jieba和Gensim的中文处理能力,全面覆盖了深度学习项目启动所需的各种步骤。
目录
环境安装重要的就是细心,不然有的时候出BUG检查起来还是比较麻烦的,各种包要注意自己安装的版本。
CUDA安装验证
当我们要使用GPU进行计算任务时,就需要用到CUDA,CUDA的主要作用就是连接GPU和应用程序。直接进入官网找到对应于GPU的CUDA版本进行安装即可
这里一路点击下一步就好
安装好了CUDA,我们通常还需要安装cuDNN,否则计算效率会大幅下降。
cuDNN安装验证
cuDNN是一个为了优化深度学习计算的类库,能将模型训练的计算优化之后再通过CUDA调用GPU进行运算。
进入https://developer.nvidia.com/cudnn完成登录验证进行下载
对应上CUDA版本号,将下载下来的文件解压,并把解压后CUDA文件夹下面的bin、include、lib文件夹中的文件放到对应的CUDA安装目录下:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2对应文件夹中。
最后没有配置上环境变量的配置上环境变量:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\libnvvp
就ok了。
我们通过命令行命令nvcc -V可以查看到自己安装的CUDA版本
PyTorch安装验证
Pytorch的官网上提供了各种安装方法:https://pytorch.org/get-started/locally/
我使用的是用conda命令进行安装的方式(windows下可能需要管理员权限)
当然也可以用镜像源,将-C后面的pytorch改为镜像地址就行:
https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/

测试安装是否成功。
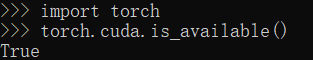
jieba安装验证
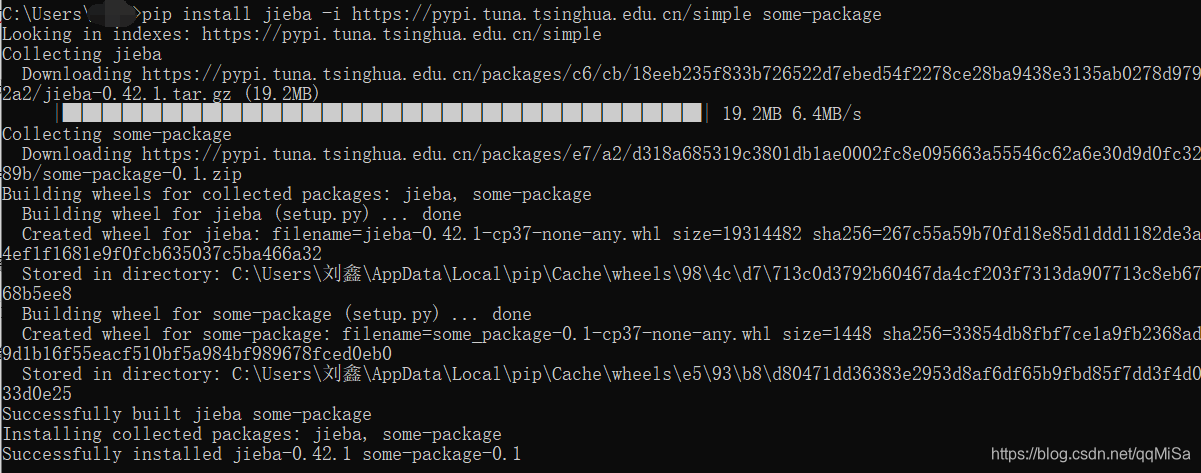
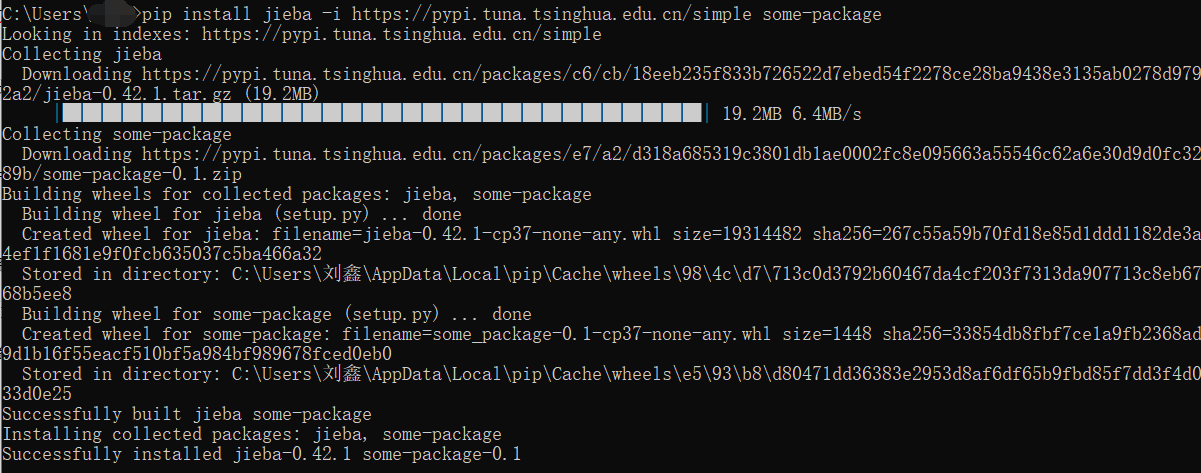
jieba是目前较好的中文分词组件,其安装过程也十分简单,直接使用pip命令安装即可:
pip install jieba
由于pip源比较慢,这里推荐使用清华的镜像源来安装
pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
也可以通过在jieba后面加==指定安装版本,这里我关于数据挖掘的所有环境都是装在base环境下的:
下面验证是否安装成功:
在python中导入jieba看是否报错
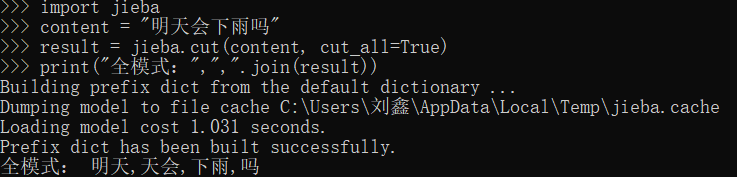
可以看到,jieba已经能够成功导入并进行分词操作了
Gensim安装验证
Gensim是一个NLP的python包,可以很方便的用于使用word2vec,同时还提供了很多其他的API,Gensim同样可以通过pip命令进行安装。
pip install Gensim -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
(清华源可以设置为默认的,就不用每次都在后面加上来进行暂时调用)

我们通过在python中调用Gensim包是否报错来检查是否安装成功
![]()

















 709
709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









