






我们都知道 Kafka 是基于磁盘进行存储的,但 Kafka 官方又称其具有高性能、高吞吐、低延时的特点,其吞吐量动辄几十上百万。
在座的靓仔和靓女们是不是有点困惑了,一般认为在磁盘上读写数据是会降低性能的,因为寻址会比较消耗时间。那 Kafka 又是怎么做到其吞吐量动辄几十上百万的呢?
《Kafka 高性能架构设计 7 大秘诀》系列已完结,今天带大家总结下 kafka 为什么这么快?提炼精华,开干。
Kafka Reactor I/O 网络模型
Kafka Reactor I/O 网络模型是一种非阻塞 I/O 模型,利用事件驱动机制来处理网络请求。更多细节详见《Kafka 高性能 7 大秘诀之 Reactor 网络 I/O 模型》
该模型通过 Reactor 模式实现,即一个或多个 I/O 多路复用器(如 Java 的 Selector)监听多个通道的事件,当某个通道准备好进行 I/O 操作时,触发相应的事件处理器进行处理。
这种模型在高并发场景下具有很高的效率,能够同时处理大量的网络连接请求,而不需要为每个连接创建一个线程,从而节省系统资源。
Reactor 线程模型如图 2 所示。
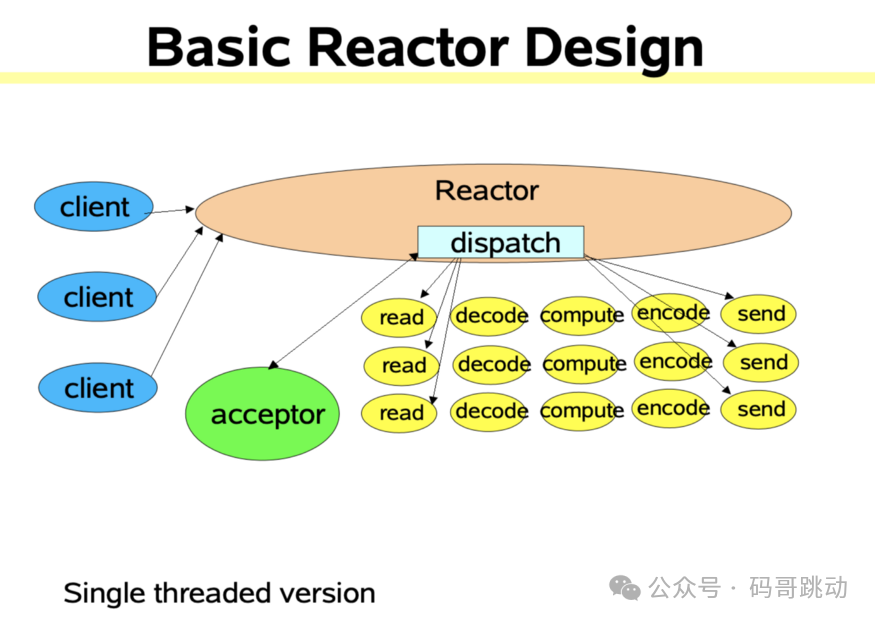
图 2
Reacotr 模型主要分为三个角色。
Reactor:把 I/O 事件根据类型分配给分配给对应的 Handler 处理。
Acceptor:处理客户端连接事件。
Handler:处理读写等任务。
Kafka 基于 Reactor 模型架构如图 3 所示。
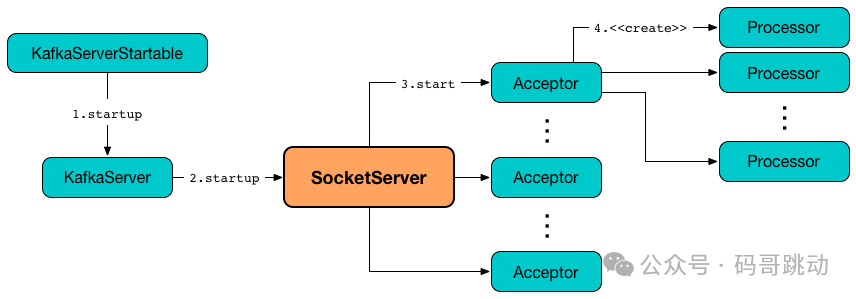
图 3
Kafka 的网络通信模型基于 NIO(New Input/Output)库,通过 Reactor 模式实现,具体包括以下几个关键组件:
SocketServer:管理所有的网络连接,包括初始化 Acceptor 和 Processor 线程。
Acceptor:监听客户端的连接请求,并将其分配给 Processor 线程。Acceptor 使用 Java NIO 的
Selector进行 I/O 多路复用,并注册 OP_ACCEPT 事件来监听新的连接请求。每当有新的连接到达时,Acceptor 会接受连接并创建一个SocketChannel,然后将其分配给一个 Processor 线程进行处理。Processor:处理具体的 I/O 操作,包括读取客户端请求和写入响应数据。Processor 同样使用
Selector进行 I/O 多路复用,注册 OP_READ 和 OP_WRITE 事件来处理读写操作。每个 Processor 线程都有一个独立的Selector,用于管理多个SocketChannel。RequestChannel:充当 Processor 和请求处理线程之间的缓冲区,存储请求和响应数据。Processor 将读取的请求放入 RequestChannel 的请求队列,而请求处理线程则从该队列中取出请求进行处理。
KafkaRequestHandler:请求处理线程,从 RequestChannel 中读取请求,调用 KafkaApis 进行业务逻辑处理,并将响应放回 RequestChannel 的响应队列。KafkaRequestHandler 线程池中的线程数量由配置参数
num.io.threads决定。
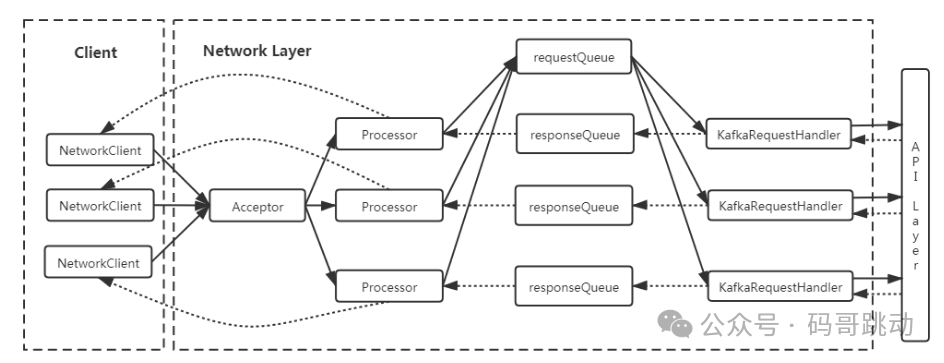
图 4
Chaya:该模型和如何提高 kafka 的性能和效率?
高并发处理能力:通过 I/O 多路复用机制,Kafka 能够同时处理大量的网络连接请求,而不需要为每个连接创建一个线程,从而节省了系统资源。
低延迟:非阻塞 I/O 操作避免了线程的阻塞等待,使得 I/O 操作能够更快地完成,从而降低了系统的响应延迟。
资源节省:通过减少线程的数量和上下文切换,Kafka 在处理高并发请求时能够更有效地利用 CPU 和内存资源。
扩展性强:Reactor 模式的分层设计使得 Kafka 的网络模块具有很好的扩展性,可以根据需要增加更多的 I/O 线程或调整事件处理器的逻辑。
零拷贝技术的运用
零拷贝技术是一种计算机操作系统技术,用于在内存和存储设备之间进行数据传输时,避免 CPU 的参与,从而减少 CPU 的负担并提高数据传输效率。详见《Kakfa 高性能架构设计之零拷贝技术的运用》
Kafka 使用零拷贝技术来优化数据传输,特别是在生产者将数据写入 Kafka 和消费者从 Kafka 读取数据的过程中。在 Kafka 中,零拷贝主要通过以下几种方式实现:
sendfile() 系统调用:在发送数据时,Kafka 使用操作系统的 sendfile() 系统调用直接将文件从磁盘发送到网络套接字,而无需将数据复制到应用程序的用户空间。这减少了数据复制次数,提高了传输效率。
文件内存映射(Memory-Mapped Files):Kafka 使用文件内存映射技术(mmap),将磁盘上的日志文件映射到内存中,使得读写操作可以在内存中直接进行,无需进行额外的数据复制。
比如 Broker 读取磁盘数据并把数据发送给 Consumer 的过程,传统 I/O 经历以下步骤。
读取数据:通过
read系统调用将磁盘数据通过 DMA copy 到内核空间缓冲区(Read buffer)。拷贝数据:将数据从内核空间缓冲区(Read buffer) 通过 CPU copy 到用户空间缓冲区(Application buffer)。
写入数据:通过
write()系统调用将数据从用户空间缓冲区(Application) CPU copy 到内核空间的网络缓冲区(Socket buffer)。发送数据:将内核空间的网络缓冲区(Socket buffer)DMA copy 到网卡目标端口,通过网卡将数据发送到目标主机。
这一过程经过的四次 copy 如图 5 所示。
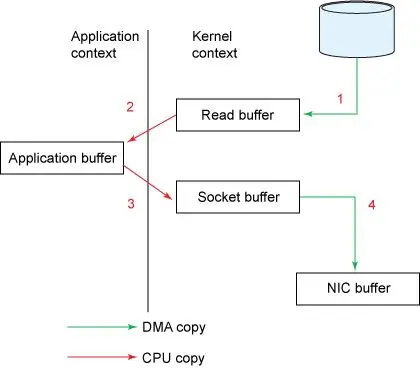
图 5
Chaya:零拷贝技术如何提高 Kakfa 的性能?
零拷贝技术通过减少 CPU 负担和内存带宽消耗,提高了 Kakfa 性能。
降低 CPU 使用率:由于数据不需要在内核空间和用户空间之间多次复制,CPU 的参与减少,从而降低了 CPU 使用率,腾出更多的 CPU 资源用于其他任务。
提高数据传输速度:直接从磁盘到网络的传输路径减少了中间步骤,使得数据传输更加高效,延迟更低。
减少内存带宽消耗:通过减少数据在内存中的复制次数,降低了内存带宽的消耗,使得系统能够处理更多的并发请求。
Partition 并发和分区负载均衡
在说 Topic patition 分区并发之前,我们先了解下 kafka 架构设计。
Kafka 架构
一个典型的 Kafka 架构包含以下几个重要组件,如图 6 所示。
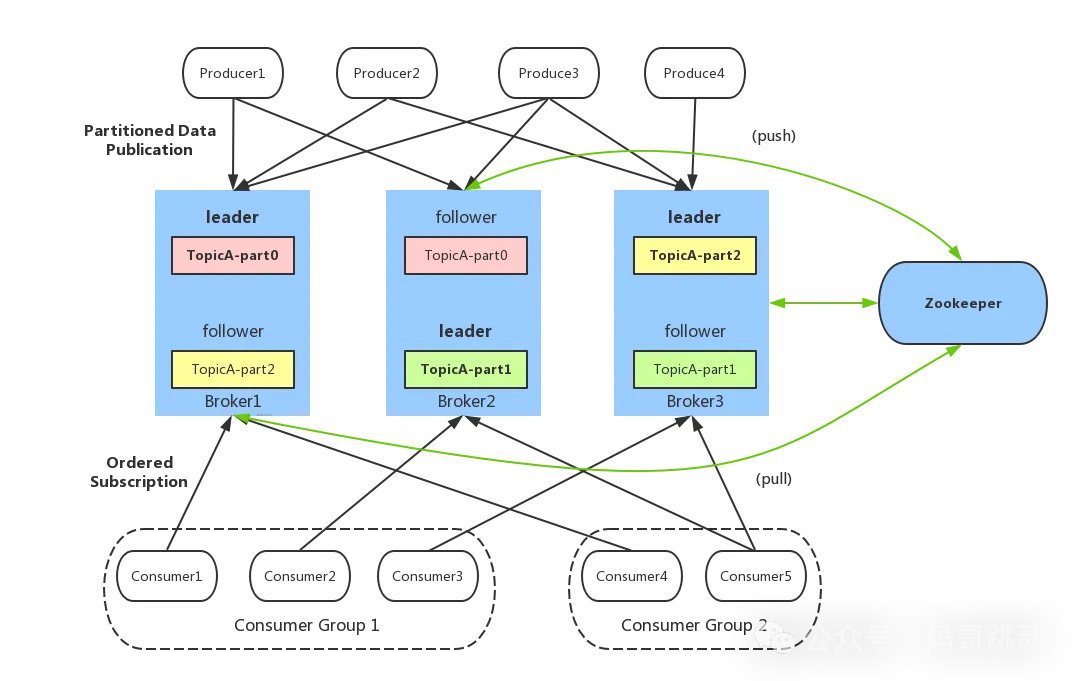
图 6
Producer(生产者):发送消息的一方,负责发布消息到 Kafka 主题(Topic)。
Consumer(消费者):接受消息的一方,订阅主题并处理消息。Kafka 有 ConsumerGroup 的概念,每个 Consumer 只能消费所分配到的 Partition 的消息,每一个 Partition 只能被一个 ConsumerGroup 中的一个 Consumer 所消费,所以同一个 ConsumerGroup 中 Consumer 的数量如果超过了 Partiton 的数量,将会出现有些 Consumer 分配不到 partition 消费。
Broker(代理):服务代理节点,Kafka 集群中的一台服务器就是一个 broker,可以水平无限扩展,同一个 Topic 的消息可以分布在多个 broker 中。
Topic(主题)与 Partition(分区) :Kafka 中的消息以 Topic 为单位进行划分,生产者将消息发送到特定的 Topic,而消费者负责订阅 Topic 的消息并进行消费。图中 TopicA 有三个 Partiton(TopicA-par0、TopicA-par1、TopicA-par2)
为了提升整个集群的吞吐量,Topic 在物理上还可以细分多个 Partition,一个 Partition 在磁盘上对应一个文件夹。
Replica(副本):副本,是 Kafka 保证数据高可用的方式,Kafka 同一 Partition 的数据可以在多 Broker 上存在多个副本,通常只有 leader 副本对外提供读写服务,当 leader 副本所在 broker 崩溃或发生网络异常,Kafka 会在 Controller 的管理下会重新选择新的 Leader 副本对外提供读写服务。
ZooKeeper:管理 Kafka 集群的元数据和分布式协调。
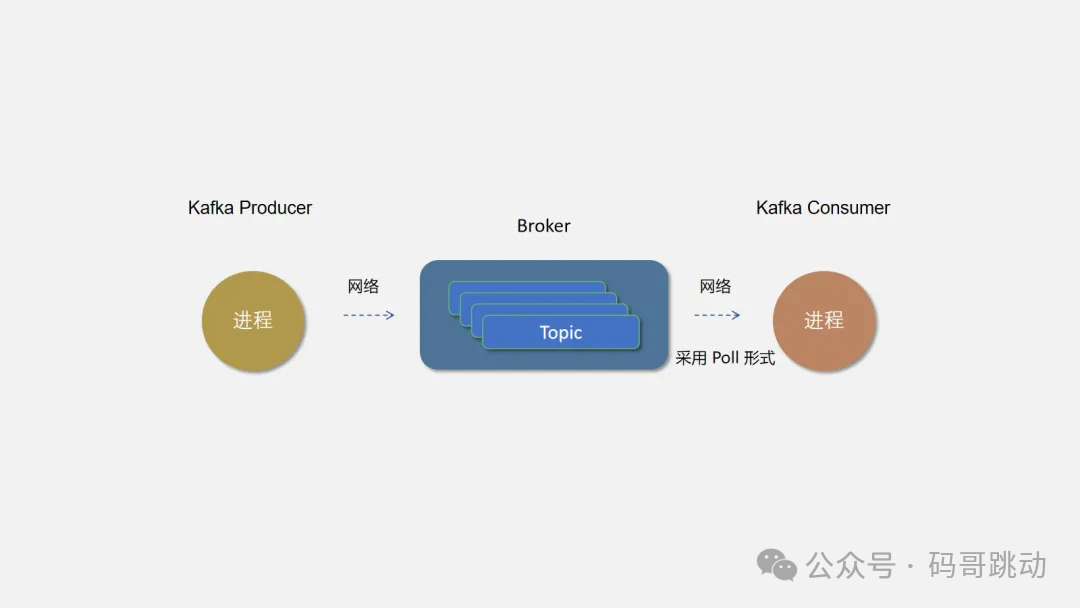
Topic 主题
Topic 是 Kafka 中数据的逻辑分类单元,可以理解成一个队列。Broker 是所有队列部署的机器,Producer 将消息发送到特定的 Topic,而 Consumer 则从特定的 Topic 中消费消息。
Partition
为了提高并行处理能力和扩展性,Kafka 将一个 Topic 分为多个 Partition。每个 Partition 是一个有序的消息队列,消息在 Partition 内部是有序的,但在不同的 Partition 之间没有顺序保证。
Producer 可以并行地将消息发送到不同的 Partition,Consumer 也可以并行地消费不同的 Partition,从而提升整体处理能力。
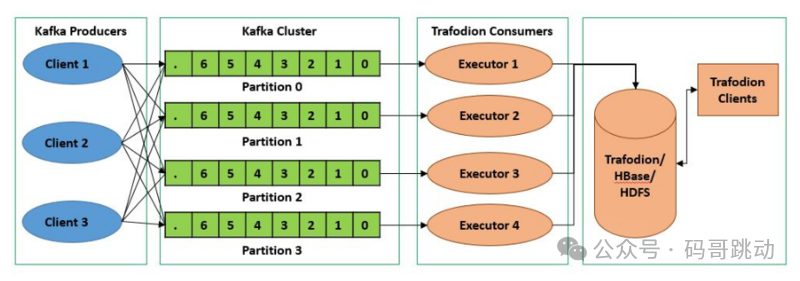
因此,可以说,每增加一个 Paritition 就增加了一个消费并发。Partition 的引入不仅提高了系统的可扩展性,还使得数据处理更加灵活。















 479
479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









