







Adaboost通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合来提高分类的性能。其基本思想是将多个专家的判断进行适当的综合所得到的判断比单个专家的判断结果更优。在日常的算法应用场景中,发现弱学习算法通常要比发现强学习算法容易的多,那么如何有效提升这些弱学习算法的性能便成为了重点研究课题。
对于分类问题,给定一个训练样本集,首先求得一些粗糙的分类规则即弱分类器,然后通过反复学习得到一系列弱分类器,最后组合这些弱分类器构成一个强分类器。大多数的提升方法都是通过改变训练数据的权值分布来训练提升的。
此时对于提升算法,面临两个关键问题需要解决;一是在每一轮如何改变训练数据的权值分布或概率分布,二是如何将这些弱分类器组合起来。对于第一个问题,提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被正确分类样本的权值,如此被错误分类的样本数据得到后一轮弱分类器的关注,于是分类问题得到分治。对于第二个问题,Adaboost采用加权表决的方法,加大分类误差率较小的弱分类器权值使其在最终表决中话语权更大,减小分类误差率较大的弱分类器权值,使其在最终表决中话语权较小。
假设二分类训练数据集:
T={(x1,y1),(x2,y2),(xn,yn)}
每个样本点由实例和标记组成,y的取值{-1,+1},AdaBoost利用以下算法从训练数据中学习一系列弱分类器,并将这些弱分类器线性组合成为一个强分类器G(x)。
1、初始化训练数据集权值分布D1=(w11,w12,……,w1n),w1i=1/n,i=1,2,……n。一开始的时候初始化样本点权值,此时每个样本点都是同等重要无差别的,所以初始值都为1/N
2、m=1,2,3,……M
(a)使用具有权值分布Dm的训练数据集学习得到基本分类器 Gm(x):{-1,+1}
(b)计算Gm(x)在训练数据集上的分类误差率

I()表示如果符合括号内的条件就计数加1。Gm(x)在加权的训练数据集上的分类误差率等于被Gm(x)误分类样本的权值之和!
(c)计算Gm(x)的系数 ,当前基本分类器的系数,即对最终结果的决定权重。
,当前基本分类器的系数,即对最终结果的决定权重。
(d)更新训练数据集的权值分布 Zm是规范化因子
Zm是规范化因子
被误分类的样本权重被加大,从而得到更多的关注!观察指数部分,预测值与实际值不相同时,即预测值和实际值的乘积为-1,计算之后指数值是被放大的,即被错误分类的样本点的权值被加大。
3、构建基本分类器的线性组合

说明:1假设训练数据集具有均匀的权值分布,即每个训练样本在基本分类器的学习作用相同,这一假设保证第1步能够在原始数据上学习基本分类器G1(x)。
AdaBoost反复学习基本分类器,在每一轮m=1,2,3……M执行操作。使用当前分布Dm加权的训练数据集学习基本分类器Gm(x)。计算基本分类器Gm(x)在加权训练数据集上的分类误差率;

Wmi表示在第m轮中第i个实例的权值,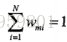

更新训练数据集的权值分布为下一轮做准备

被基本分类器Gm(x)误分类样本的权值得以扩大,而被正确分类样本的权值得以缩小。因此误分类样本在下一轮学习中起到更大的作用。不改变所给的训练数据,而不断改变训练数据权值的分布,使得训练数据在基本分类器的学习中起不同的作用,这是AdaBoost的一个特点。最后使用线性组合f(x)实现M个基本分类器的加权表决。

初始化数据权值分布,m=1 
(a)在权值分布为D1的训练数据上,阈值v=2.5时分类误差率最低,故基本分类器为:

(b)G1(x)在训练数据集上的误差率e1=P(G1(xi)≠yi)=0.3
(c)计算G1(x)的系数:

(d)更新训练数据的权值分布:

分类器sign[f1(x)]在训练数据集上有3个误分类点。
(a)在权值分布为D2的训练数据上,阈值v是8.5时分类误差率最低,基本分类器为

(b)G2(x)在训练数据上的误差率e2=0.2143
(c)α2=0.6496
(d)更新训练数据权值分布

分类器sign[f2(x)]在训练数据集上有3个误分类点。
(a)在权值分布为D3的训练数据上,阈值v=5.5时分类误差率最低,基本分类器为:

(b)G3(x)在训练样本集上的误差率e3=0.1820
(c)计算α3=0.7514
(d)更新训练数据的权值分布:

于是得到 ,分类器sign[f3(x)]在训练数据集上误分类点个数为0,于是最终分类器为:
,分类器sign[f3(x)]在训练数据集上误分类点个数为0,于是最终分类器为:
AdaBoost算法的训练误差分析
AdaBoost最基本的性质是它能够在学习过程中不断减少训练误差。最终训练误差界:

证:当G(x)≠yi时,yi*f(xi)<0,因而exp(-yi*f(xi))≥1,由此直接得出式子的前面部分。后面部分推导:

(注意1/N代表第一轮的数据权值):

这个证明表明,可以在每一轮选取适当的Gm使得Zm最小,从而使训练误差下降最快。
二分类问题AdaBoost训练误差界

证:


得到:

而后面的不等式:

推论:
由上面的等式推出  ,表明AdaBoost的训练误差是以指数速率下降的。
,表明AdaBoost的训练误差是以指数速率下降的。
AdaBoost算法的概率解释
可以认为AdaBoost算法是模型为加法模型、损失函数为指数函数、学习算法为前向分步算法时的二分类学习方法。
加法模型: 其中,b(x,γm)为基函数,γm为基函数的参数,βm为基函数的系数,显然该式子是一个加法模型。在给定训练数据及损失函数L(y,f(x))的条件下,训练加法模型成为经验风险极小化即损失函数极小化问题。
其中,b(x,γm)为基函数,γm为基函数的参数,βm为基函数的系数,显然该式子是一个加法模型。在给定训练数据及损失函数L(y,f(x))的条件下,训练加法模型成为经验风险极小化即损失函数极小化问题。

但是优化这个式子比较复杂,因为是加法模型,我们可以只优化每一步,逐步逼近目标函数式。
前向分步算法:训练数据集T={(x1,y1),(x2,y2),……(xn,yn)},损失函数L(y,f(x)),基函数集{b(x;γ)}
1、初始化加法模型f0(x)=0
2、对m=1,2,……M
(a)、极小化损失函数 得到参数βm,γm
得到参数βm,γm
(b)、更新加法模型
3、得到加法模型
这样前向分步算法从同时求解m=1到M所有参数βm,γm的优化问题简化为求解各个参数系数的优化问题。
前向分步算法与AdaBoost
AdaBoost算法是前向分步加法算法的特例,此时模型是由基本分类器组成的加法模型,损失函数是指数函数。
证明:前向分步算法的损失函数是指数损失函数
AdaBoost最终分类器为
前向分步加法算法逐一学习基函数,这一过程与AdaBoost算法是一致的,假设经过m-1轮迭代前向分步加法算法已经得到fm-1(x)
在第m轮迭代得到 ,目标是使前向分步算法得到的α和G使fm(x)在训练数据集上指数损失最小即:
,目标是使前向分步算法得到的α和G使fm(x)在训练数据集上指数损失最小即:


其中 不依赖α和G,所以与最小化无关。现在证明使上式达到最小的α*和G*就是AdaBoost算法所得到的α和G
不依赖α和G,所以与最小化无关。现在证明使上式达到最小的α*和G*就是AdaBoost算法所得到的α和G


此分类器G*即为AdaBoost算法的基本分类器Gm(x),因为它是使第m轮加权训练数据分类误差率最小的基本分类器。α*的求解可以参照前面的方法如下:

将求得的G*代入,求导并使导数为0,即可得到α*, 其中em是分类误差率
其中em是分类误差率

最后看一下每一轮样本权值的更新:

得到: ,这与AdaBoost算法样本权值更新式子也是等价的。
,这与AdaBoost算法样本权值更新式子也是等价的。
提升树
提升树是以分类树或回归树为基本分类器的提升方法。提升方法实际采用加法模型(即基函数的线性组合)与前向分步算法,以决策树为基函数的提升方法称为提升树。提升树可以表示为决策树的加法模型:
 ,其中T(x;θm)表示决策树,θm为决策树的参数,M为树的个数。
,其中T(x;θm)表示决策树,θm为决策树的参数,M为树的个数。
 其中fm-1(x)为当前模型,通过经验风险极小化即损失函数极小化确定下一个决策树的参数θm
其中fm-1(x)为当前模型,通过经验风险极小化即损失函数极小化确定下一个决策树的参数θm

对于二分类问题,提升树算法只需将AdaBoost算法的基本分类器限制为二分类树即可。
回归提升树
已知训练数据集T={(x1,y1),(x2,y2),……(xn,yn)},X为输入空间,Y为输出空间,如果将输入空间划分为J个互不相交的区域R1,R2,……Rj,并且在每个区域确定输出常量cj,那么树可表示为:
 J是回归树的复杂度即叶结点个数。
J是回归树的复杂度即叶结点个数。
回归树的前向分步算法:

在前向分步算法的第m步,给定当前模型fm-1(x),需求解 第m棵树的参数。
第m棵树的参数。
当采用平方误差损失函数时, 其损失为:
其损失为:

 是当前模型拟合数据的残差,对回归问题的提升树算法来说,只需要拟合当前模型的残差。
是当前模型拟合数据的残差,对回归问题的提升树算法来说,只需要拟合当前模型的残差。
回归问题的提升树算法:
输入训练数据集T={(x1,y1),(x2,y2),……(xn,yn)},输出提升树fM(x)
初始化f0(x)=0,对m=1,2……M,计算残差
拟合残差学习一个回归树,得到T(x,θm),更新fm(x)=fm-1(x)+T(x,θm),最后得到回归提升树
例子:

首先求解回归树T1(x),优化以下公式:

求解训练数据的切分点s, 容易求得在R1,R2内部使平方损失误差达到最小值的c1,c2为:
容易求得在R1,R2内部使平方损失误差达到最小值的c1,c2为:
 其中,N1,N2是R1,R2的样本点数。
其中,N1,N2是R1,R2的样本点数。
首先求训练数据的切分点,根据所给数据考虑如下切分点:
1.5 ,2.5 ,3.5 ,4.5 ,5.5 ,6.5 ,7.5 ,8.5 ,9.5
对各个切分点,不难求出相应的R1,R2,c1,c2


不同的切分点和对应的均方误差为:

由表可知,当s=6.5时,m(s)达到最小值,此时R1={1,2,……6},R2={7,8,9,10},c1=6.24,c2=8.91

用f1(x)拟合训练数据的残差表:r2i=yi-f1(xi)

用f1(x)拟合训练数据的平方损失误差:
第二步求T2(x),方法与求T1(x)一样,此时拟合的数据是上面的残差。

用f2(x)拟合训练数据的平方损失误差是:


用f6(x)拟合训练数据的平方损失误差是:
 若此时已满足误差要求,那么f(x)=f6(x)即为所求提升树。
若此时已满足误差要求,那么f(x)=f6(x)即为所求提升树。
梯度提升树
提升树利用加法模型与前向分步算法实现学习的优化过程,当损失函数是均方误差和指数损失函数时,每一步优化相对简单,但对于一般损失函数而言优化并不那么简单。针对这个问题我们提出了梯度提升算法。其核心是利用当前模型损失函数的负梯度作为回归提升树算法中残差的近似。

算法流程:训练数据集T={(x1,y1),(x2,y2),……(xn,yn)}
初始化:


对rmi拟合一个回归树,得到第m棵回归树的叶结点区域Rmj,j=1,2,3,…J,对第m棵回归树的不同叶节点区域计算:
其中Cmj表示第m棵回归树的第j个叶节点的回归值,fm-1(x)是前m-1棵树的累加。
更新:
最后得到回归树(各个叶节点上的回归值)
















 1368
1368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









