







文本表示:
文本表示的意思是把字词处理成向量或矩阵,以便计算机能进行处理。
文本表示按照细粒度划分
字级别、词语级别、句子级别的文本表示。
文本表示可分为
- 离散表示(离散、高维、稀疏):代表就是词袋模型,one-hot(也叫独热编码)、TF-IDF、n-gram都可以看作是词袋模型。
- 分布式表示(连续、低维、稠密): 词嵌入(word embedding),经典模型是word2vec、Glove、ELMO、GPT、BERT。
词袋模型(离散、高维、稀疏):
假如现在有1000篇新闻文档,把这些文档拆成一个个的字,去重后得到3000个字,然后把这3000个字作为字典,进行文本表示的模型,叫做词袋模型。这种模型的特点是字典中的字没有特定的顺序,句子的总体结构也被舍弃了。
其原理就是把句子看着若干个单词的集合,不会考虑单词的出现顺序,仅仅考虑单词出现没有或者出现的频率,这样看来每一个句子都可能有高维、稀疏和离散的情况,即使通过n-gram来表征单词间的关联也会造成高维、稀疏的情况发生。
one-hot


import pandas as pd
from numpy import array
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
data = ['cold', 'cold', 'warm', 'cold', 'hot', 'hot', 'warm', 'cold', 'warm', 'hot']
values = array(data)
label_encoder = LabelEncoder()
integer_encoded = label_encoder.fit_transform(values)
print(integer_encoded) # [0 0 2 0 1 1 2 0 2 1]
onehot_encoder = OneHotEncoder(sparse=False)
integer_encoded = integer_encoded.reshape(len(integer_encoded), 1)
integer_encoded
array([[0],
[0],
[2],
[0],
[1],
[1],
[2],
[0],
[2],
[1]], dtype=int64)
onehot_encoded = onehot_encoder.fit_transform(integer_encoded)
print(onehot_encoded)
[[1. 0. 0.]
[1. 0. 0.]
[0. 0. 1.]
[1. 0. 0.]
[0. 1. 0.]
[0. 1. 0.]
[0. 0. 1.]
[1. 0. 0.]
[0. 0. 1.]
[0. 1. 0.]]
第一个问题是数据稀疏和维度灾难。
数据稀疏也就是向量的大部分元素为0,如果词袋中的字词达数百万个,那么由每篇文档转换成的向量的维度是数百万维,由于每篇文档去重后字数较少,因此向量中大部分的元素是0。
第二个问题是没有考虑句中字的顺序性,假定字之间相互独立。这意味着意思不同的句子可能得到一样的向量。比如“我太可爱了,邓紫棋爱我”,“邓紫棋要看我的演唱会”,得到的one-hot编码和上面两句话的是一样的。
第三个问题是没有考虑字的相对重要性。这种表示只管字出现没有,而不管出现的频率,但显然一个字出现的次数越多,一般而言越重要(除了一些没有实际意义的停用词)。
TF-IDF
TF-IDF用来评估字词对于文档集合中某一篇文档的重要程度。字词的重要性与它在某篇文档中出现的次数成正比,与它在所有文档中出现的次数成反比。TF-IDF的计算公式为:
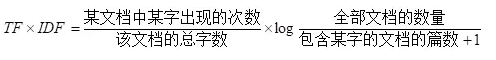
TF-IDF的思想比较简单,但是却非常实用。
然而这种方法还是存在着数据稀疏的问题,也没有考虑字的前后信息。
n-gram
上面词袋模型的两种表示方法假设字与字之间是相互独立的,没有考虑它们之间的顺序。于是引入n-gram(n元语法)的概念。n-gram是从一个句子中提取n个连续的字的集合,可以获取到字的前后信息。一般2-gram或者3-gram比较常见。
比如“邓紫棋太可爱了,我爱邓紫棋”,“我要看邓紫棋的演唱会”这两个句子,分解为2-gram词汇表:
{邓,邓紫,紫,紫棋,棋,棋太,太,太可,可,可爱,爱,爱了,了,了我,我,我爱,爱邓,我要,要,要看,看邓,棋的,的,的演,演,演唱,唱会,会}
于是原来只有14个字的1-gram字典(就是一个字一个字进行划分的方法)就成了28个元素的2-gram词汇表,词表的维度增加了一倍。
结合one-hot,对两个句子进行编码得到:
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0]
[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,1]
也可以结合TF-IDF来得到文本表示,这里不再计算。
这种表示方法的好处是可以获取更丰富的特征,提取字的前后信息,考虑了字之间的顺序性。
但是问题也是显而易见的,这种方法没有解决数据稀疏和词表维度过高的问题,而且随着n的增大,词表维度会变得更高。
分布式表示:连续、低维、稠密。
TODO
参考:
https://www.jianshu.com/p/cacd11ae7205















 468
468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









