









这篇博文,博主分享的是大数据集群的安装部署,简单实用,希望这篇文章能够帮助大家,在正式部署之前,我们需要提前做好准备工作。
准备好三台虚拟机,ip分别为192.168.2.112,192.168.2.113,192.168.2.114。
对应的主机名为hadoop002,hadoop003,hadoop004
部署规划:
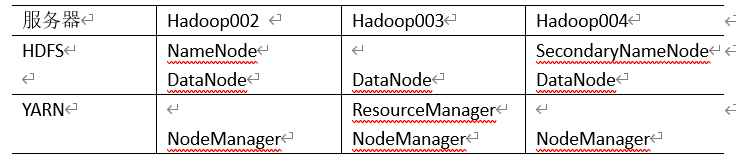
三台机器准备工作:
1.关闭防火墙 service iptables stop
chkconfig iptables stop
2.关闭selinux
3.修改主机名
4.ssh无密码拷贝数据
特别说明(在主节点无密码访问到从节点)
ssh-keygen
ssh-copy-id 192.168.2.112
ssh-copy-id 192.168.2.113
ssh-copy-id 192.168.2.124
5.设置主机名和IP对应
vi /etc/hosts
6.jdk1.8安装
7. hadoop2.7.2安装
因为在之前的博客在Linux中部署集群(零基础速学!)中,上述的准备操作均已详细描述,这里对于准备工作的内容就不做过多讲解。接下来正式开始进行集群环境的搭建
目录
一. 上传压缩包并解压
博主在此,先把需要用到的文档打包上传到百度云,需要的可以自取:
链接:https://pan.baidu.com/s/1raXTsh690-KLA9Pk2R-cIA
提取码:5u1g
# 创建两个文件夹
mkdir -p /opt/software 存放软件压缩包
mkdir -p /opt/module 存放压缩后的文件
创建完成下面就需要配置java和Hadoop
如何配置 Java 和 Hadoop 具体过程可以看博主以往的文章:
[Centos版]Hadoop运行环境的具体搭建过程(超详细)
二. 配置集群(重点)
声明:配置文件到在:
/opt/module/hadoop-2.7.2/etc/hadoop/
配置方式多样,在此我推荐通过Xshell同时操作

1. 核心配置文件
- 配置core-site.xml
[bigdata@hadoop002 root]$ cd /opt/module/hadoop-2.7.2/etc/hadoop/
[bigdata@hadoop002 hadoop]$ vim core-site.xml
将以下内容添至xml文件指定位置处
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop002:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>

2. HDFS配置文件
- 1. 配置hadoop-env.sh
[bigdata@hadoop002 hadoop]$ vim hadoop-env.sh
# 修改
export JAVA_HOME=/opt/module/jdk1.8.0_144

- 2. 配置hdfs-site.xml
[bigdata@hadoop002 hadoop]$ vim hdfs-site.xml
将以下内容添至xml文件指定位置处
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop004:50090</value>
</property>
3. YARN配置文件
- 1. 配置yarn-env.sh
[bigdata@hadoop002 hadoop]$ vim yarn-env.sh
# 修改
export JAVA_HOME=/opt/module/jdk1.8.0_144

- 2. 配置yarn-site.xml
[bigdata@hadoop002 hadoop]$ vim yarn-site.xml
将以下内容添至xml文件指定位置处
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop003</value>
</property>
4. MapReduce配置文件
- 1. 配置mapred-env.sh
[bigdata@hadoop002 hadoop]$ vim mapred-env.sh
# 修改如下
export JAVA_HOME=/opt/module/jdk1.8.0_144

- 2. 配置mapred-site.xml
[bigdata@hadoop002 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[bigdata@hadoop002 hadoop]$ vim mapred-site.xml
将以下内容添至xml文件指定位置处
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
5. 配置slaves
[bigdata@hadoop002 hadoop]$ vim slaves
在文件中增加如下内容
hadoop002
hadoop003
hadoop004
三. 集群启动
要启动 Hadoop 集群,需要启动 HDFS 和 YARN 两个集群。
注意: 首次启动HDFS时,必须对其进行格式化操作。本质上是一些清理和准备工作,因为此时的 HDFS 在物理上还是不存在的。
首先我们需要进行格式化:bin/hdfs namenode -format。但是不要轻易格式化集群,格式化后集群的数据丢失且无法恢复。
1. 单节点启动
- (1)如果集群是第一次启动,需要格式化NameNode
# 首次需要进行格式化
[bigdata@hadoop002 hadoop-2.7.2]$ hdfs namenode -format

- (2)在hadoop102上启动NameNode
[bigdata@hadoop002 hadoop-2.7.2]$ hadoop-daemon.sh start namenode
[bigdata@hadoop002 hadoop-2.7.2]$ jps
3461 NameNode
- (3)在hadoop102、hadoop103以及hadoop104上分别启动DataNode
[bigdata@hadoop002 hadoop-2.7.2]$ hadoop-daemon.sh start datanode
[bigdata@hadoop002 hadoop-2.7.2]$ jps
3461 NameNode
3608 Jps
3561 DataNode
[bigdata@hadoop003 hadoop-2.7.2]$ hadoop-daemon.sh start datanode
[bigdata@hadoop003 hadoop-2.7.2]$ jps
3190 DataNode
3279 Jps
[bigdata@hadoop004 hadoop-2.7.2]$ hadoop-daemon.sh start datanode
[bigdata@hadoop004 hadoop-2.7.2]$ jps
3237 Jps
3163 DataNode
但是如果用单节点启动会很麻烦。这是我们就需要用到群起节点了
2. 脚本一键启动HDFS、Yarn(推荐)
如果配置了 vim slaves 和 ssh 免密登录,则可以使用程序脚本启动所有Hadoop 两个集群的相关进程,在主节点所设定的机器上执行。
关于ssh 免密登录,如果有不会的小伙伴可以看我往期的在Linux中部署集群(零基础速学!)第九部分
- 1. 启动集群
在第一台机器执行以下命令
[bigdata@hadoop002 hadoop]$ cd /opt/module/hadoop-2.7.2/
# yarn启动要和RecourseManager在一起 ,博主的放在了hadoop003上
sbin/start-dfs.sh # 开启HDFS
sbin/start-yarn.sh # 开启Yarn
- 2.停止集群
没事不要随便停止
sbin/stop-dfs.sh
sbin/stop-yarn.sh
3. 脚本一键启动所有
- 一键启动集群
sbin/start-all.sh
- 一键关闭集群
sbin/stop-all.sh
四. web查看启动页面
- 1. hdfs集群访问地址
# 填写hadoop02的ip
http://hadoop002:50070/dfshealth.html#tab-overview

- 2. yarn集群访问地址
# 填写hadoop003的ip
http://hadoop003:8088/cluster

- 3. Web端查看SecondaryNameNode
# 填写hadoop004的ip
http://hadoop004:50090/status.html

如果看见以上画面,配置就全部成功了。
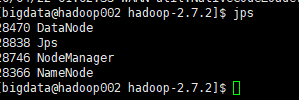
另外,我们通过命令jps也可以验证:
hadoop002:
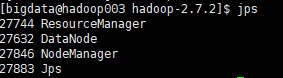
hadoop003:
hadoop004:
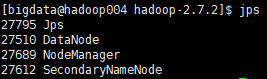
如果截图内容与上图不符,可能是在前面的步骤中哪里出错了,还需要重新检查一遍!
五. 验证集群是否可用
1.jps用于验证集群服务的启动情况
2.namenode所在节点的IP+50070端口查看HDFS的web界面是否可用
3.在HSFS系统中创建一个文件夹或文件,若能创建表示集群可以正常使用!
需要注意的是:
HDFS不支持目录或文件夹的切换,所有路径必须写成绝对路径
HDFS权限域linux的权限等完全相同
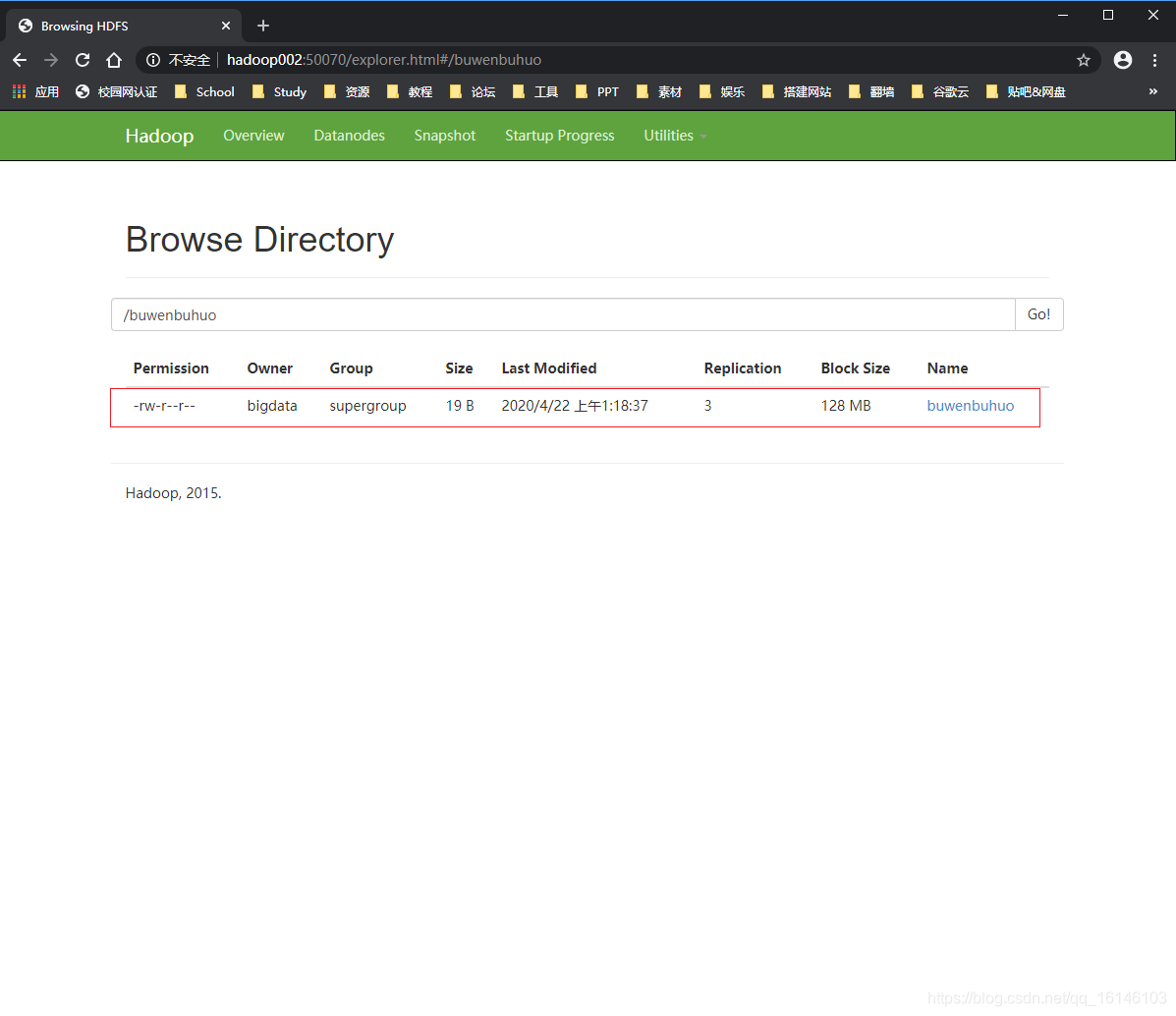
六. HDFS尝试运行
# 创建文件夹
[bigdata@hadoop002 hadoop-2.7.2]$ hadoop fs -mkdir /buwenbuhuo
# 上传文件(Linux --> HDFS):
[bigdata@hadoop002 module]$ hadoop fs -put /opt/module/buwenbuhuo /buwenbuhuo
Hadoop分布式环境搭建的过程总体来说还算是比较的繁琐,需要大家在搭建的过程中拥有足够的细心与充足的耐心(博主早前第一次搭建的时间其实踩过不少的坑。本次的分享就到这里了,下次的文章博主将会分享关于HDFS的内容,喜欢的各位小伙伴们希望你们能够点赞和关注呀!















 6747
6747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









