







1.2 面向对象与内存的高性能编码
每当我们在代码中创建一个新对象的时候,系统就会尝试分配一个空间将它保存到内存中,但每个应用可以分配的内存空间是有限的。上一节我们已经阐述了如何避免内存泄露,本节我们主要阐述如何在编码中控制内存的占用,提升效率并减少垃圾回收。
1.2.1 Data types数据类型
1.2.1.1 Autoboxing
自动装箱特性,使得基本数据类型自动转为对应的包装类型。
比如Integer i = 0;
等同于Integer i = new Integer(0);
但是很明显,自动状态也带来性能的开销。
首先是内存方面,比如相比int数据的16bits,Integer对象需要16bytes;其次是运算时,每次都经历一次拆箱和装箱,极大的降低了效率。
因此,尽可能声明使用基本数据类型,避免不必要的自动装箱。
1.2.1.2 Sparse array family
在上一节,我们阐述了尽量避免使用基本数据的包装类型,但是确实有很多场景无法避免这个问题,比如集合泛型。
List<Integer> list;
Map<Integer, Object> map;
针对这个问题,Android提供了一组有用的类,可以替代Map对象,同事避免装箱问题,这就是Sparse arrays,可以替代的Map类如下:
SparseBooleanArray: HashMap<Integer,Boolean>
SparseLongArray: HashMap<Integer,Long>
SparseIntArray: HashMap<Integer,Integer>
SparseArray<E>: HashMap<Integer,E>
LongSparseArray<E>: HashMap<Long,E>
SparseArray内部采用了两个不同的数组来分别保存hash值和键值对。在使用时,同Map的用法类似,调用put()和get()进行存取。但是SparseArray在删除的时候,会进行重新排列,带来一定的开销。综合以上,SparseArray的使用场景是:
1 需要操作的对象数量级在1000一下,并且不会有非常频繁的增删操作;
2 如果使用了Map,但是只有少数几个元素,而又有很多的读。
1.2.1.3 ArrayMap
ArrayMap是SDK提供的实现了Map接口的类,相比HashMap具有更高效的内存利用率,从AndroidKitKat (API Level 19)开始支持,同时V4包提供了低版本兼容类。
它使用了与SparseArray类似的结构,但是更进一步,提供了泛型Key对象,可以替代一般意义上的HashMap。
1.2.2 遍历与for循环
集合遍历是开发中常见的操作,遍历方式主要包括Iterator、while和for循环。
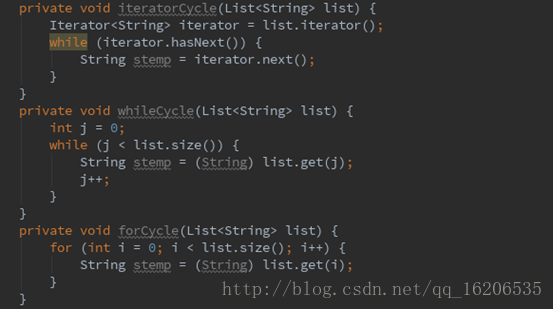
其中,for循环方式是最高效的。上述示例中的for循环是传统的写法,而Java5以后,我们可以使用高级for循环来进一步提高性能,这也是Efficient JAVA中的推荐。
1.2.3 Enumerations枚举替换为static常量
JAVA在JDK5.0之后定义了枚举类型,枚举类型和类常量(或者是接口常量)在Android中的使用场景比较相似。
1.2.3.1 Enum与static常量对比
当要处理一个常量遍历集合的时候,枚举型是一个很好的选择,最常见的使用方式是声明若干枚举值对象。
枚举写法一:
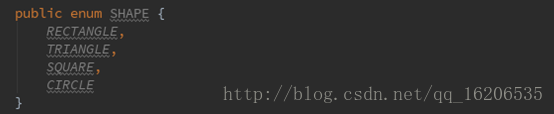
类同于如下static常量写法二:
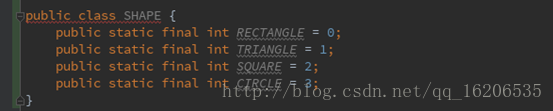
两者的写法都比较类似,不仅如此,枚举类型在编译之后,每一个枚举对象也是被编译为一个静态值,因此定义时也建议作大写。但是如果深入细节,枚举相对来说有以下优缺点。
①优点:
A 枚举常量更简单
枚举常量只需定义枚举项,不需要定义枚举值,而接口常量或类常量必须定义初始值,如上述示例,枚举相对可以更简洁优雅。
B 枚举常量属于稳态型
先看下普通接口或类常量:
interface Season{
private static final int Summer = 1;
private static final int Winter = 2;
};
public void decribe(int s){
if(s>0 && s<5){
switch(s){
case Season.Summer:
Log.d("tag", "Summer");
break;
case Season.Winter:
Log.d("tag", "Winter");
break;
default:
break;
}
}
}再看看枚举型常量
enum Season{
Summer(1), Winter(2);
private int value;
private Season(int value){}
public int getValue() {
return value;
}
};
public void decribe(Season s){
switch (s) {
case Summer:
Log.d("tag", "Summer");
break;
case Winter:
Log.d("tag", "Winter");
break;
default:
break;
}
}对比可见,不用校验已经限定了Season枚举,如果想要输入一个越界的值,在编码时都是不通过的,这也是我们最看重枚举的地方:在编译期限定类型,不允许发生越界。
C 枚举具有内置方法以及自定义扩展属性
如果要列出所有季节常量,如何实现?接口或者类常量可以通过反射实现,但是实现起来会很繁琐。如果用枚举就很简单。
enum Season{
Summer(1), Winter(2);
private int value;
private Season(int value){}
public int getValue() {
return value;
}
};
public void decribe(){
for(Season s: Season.values()){
//...
}
}其次,枚举是一个class,如果需要还可以进一步扩展内部成员变量,如上所示。
②枚举常量的缺点:
不可继承,无法扩展。
但是一般常量在构件时就定义完毕了,不需要扩展,同时也是稳态的体现。
1.2.3.2 Enum与static常量的性能取舍
那么从性能的角度应该如何选择呢?Android官方网站有专门的描述:

枚举写法一的DEX size增加是常量写法二的13倍之多,运行时的占用还包括:每个枚举值转化为integer值和一个对应的String名称的占用,生成一个对象数组用于保持对原enum值的引用,以及其它的一些封装占用。
因此,Android中避免使用枚举类型。
1.2.4 Constants常量final修饰
我们经常需要一个全局变量,使其脱离当前实例对象,实现数据共享,这就是static变量。
静态变量在类初始化(通过 VM 的<clinit> 方法)的时候得到加载,因此在应用启动的时候,就得到初始化。
但如果我们给它们加上final修饰,它们将存入DEX文件中,如此再使用它们的时候,不在需要开辟内存,前提是它们声明为基本数据类型或String类型。
因此,如果声明一个基本数据或String常量,应该修饰为static final类型,已利用其内存节省方面的优势。
1.2.5 Object management对象控制
尽可能少的创建对象,一方面,是因为内存是非常宝贵的;另一方面,内存开辟和内存回收的处理的开销也是很大的。
这里特别指那些临时的对象,因为它们更容易引来GC,这将中断所有应用层的线程,可能造成用户体验问题。
本节将从以下几个典型实践场景进行阐述,但是避免不必要的对象创建和回收的问题,应该在每一个开发环节中自我规范。
1.2.5.1 创建String对象
String对象本身是不可变的,因此,当你像如下示例声明一个String的时候,实际上是让虚拟机为两个对象开辟空间:
String string = newString("example");
其一为"example"这个对象,其二为string这个对象;
因此,规范的做法是:String string = "example";
1.2.5.2 Strings拼接
我们经常为了语法方便,对String进行拼接,而不考虑其创建新的String对象而带来的性能和内存开销。
String string = "This is ";
string += "a string";
StringBuffer和StringBuilder是更加高效的字符串拼接工具,因为其基于字符character数组进行操作,从而避免了对象创建的问题。前者是线程安全的,所以会稍慢一点,如果确定当前线程是安全,不妨使用后者。
另外,两者初始化的空间是16个characters,后续拼接字符超过时,空间将双倍的扩展。所以,如果明确需要处理的字符串大小,不妨在初始化时进行声明,否则可能存在较大的浪费。
上述示例使用StringBuffer修改如下:
StringBuffer stringBuffer = newStringBuffer(64);
stringBuffer.append("This is ");
stringBuffer.append("a string");
stringBuffer.append…
如此,如果整体的String的大小低于64个character,既没有新对象的创建,也没有带来回收问题,除非不再引用。
1.2.5.3 Local variables重复创建
我们有时候会发现一个方法中创建的对象,跟在其它方法中创建的对象是重复的,这时可以将该局部变量改为成员变量,如此,可以避免多次内存开销。
其中比较常见的示例如下:
示例①:多个方法中重复定义同一类对象
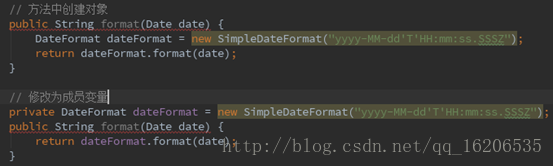
示例②:循环体中定义新的对象
这是一种更加严重的重复定义问题,除非能确定需要多个对象封装不同的值进行集合性返回,否则要将循环体中的对象定义放到block之外,如下所示:
Object obj = null;
for (int i = 0; i < 10000; ++i) {
obj = new Object();
Log.d("tag", obj.toString());
}1.2.5.4 Arrays versus collections数组vs集合
集合类型经常被优先使用,因为它们有便捷的增删改查接口;但是这也带来较大的开销。
如果需要处理的一组数据是比较固定的,原始的数组类型在内存利用上,将会比集合更优,这是一个值得自我规范的问题。
1.2.6 低效的getters和setters
创建私有属性,随后通过IDE自动生成所有这些属性的getters和setters方法,接下来就可能开始通过这些方法来访问私有属性,这是最常见的滥用getters、setters的场景。
在类内使用get(),set()是一种过度封装,带来了性能上的消耗。根据官方Guide文档,直接访问属性,比使用getter方式要快3倍以上。
因此,即使有必要保留对私有属性的封装,但是如果可以的话,尽可能直接访问,特别是在类内部进行调用的场景。
1.2.7 Inner Classes访问外部类
我们已经在上述章节讨论过内部类的泄露问题,内部类在Android中使用得非常普遍,但是也带来了一个隐藏的开销。
示例:
public class OuterClass {
private int id;
public OuterClass() {
}
private void doSomeStuff() {
InnerClass innerObject = new InnerClass();
innerObject.doSomeOtherStuff();
}
private class InnerClass {
private InnerClass() {
}
private void doSomeOtherStuff() {
OuterClass.this.doSomeStuff();
}
}
}当编译为class文件时
外部类:
class OuterClass {
private int id;
private void doSomeStuff() {
OuterClass$InnerClass innerObject = new
OuterClass$InnerClass();
innerObject.doSomeStuff();
}
int access$0() {
return id;
}
}内部类:
class InnerClass {
OuterClass this$0;
void doSomeOtherStuff() {
InnerClass.access$100(this$0);
}
static void access$100(OuterClass outerClass) {
outerClass.doSomeStuff();
}
static int access$0(OuterClass outerClass) {
return outerClass.id;
}
}可以看到,外部类为每一个属性都生成一个包级访问方法,以供内部类调用,而内部类也为外部类的成员调用生成静态方法,这样对属性的过度封装,上节已阐述,是降低调用性能的。
尽管我们强烈建议内部类做成static,但是仍有一些场景可能要维持非静态,使得外部类的实例,可以作为和外部类语义不同的实例来查看(访问),比如Collection内部的Iterator类。
public Iterator<E> iterator() {
return new Itr();
}
/**
* An optimized version of AbstractList.Itr
*/
private class Itr implements Iterator<E> {如果我们需要保持内部类的非静态生命,又需要高效的访问外部类,那么可以直接将对应的外部类的属性和方法声明为包级访问;或者将内部类声明为静态类。
1.2.8 耗时线程与外部资源
由于线程没有直接的方式将其完全停止,当我们退出界面时,至少需要停止内部耗时线程再调用外部资源。
此时要求做好线程停止Flag的标记和扩展。例如使用AsyncTask时,利用其提供的cancel()接口将内部的Flag字段进行标记
privatefinal AtomicBoolean mCancelled = new AtomicBoolean();
public finalboolean cancel(boolean mayInterruptIfRunning){
mCancelled.set(true);
return mFuture.cancel(mayInterruptIfRunning);
}在实现其doInbackground,onPostExecute,或者onProgressUpdate方法中,调取Flag进行判断,示例:
@Override
protected void onProgressUpdate(Integer... values) {
If(!isCancel()){
int vlaue =values[0];
progressBar.setProgress(vlaue);
}
} 1.2.9 内存相关patterns
针对避免创建大量新对象的场景,还应该从设计模式的角度加以考虑。
单例模式和享元模式,是比较推荐的模式,其目的都是复用我们内存中已存在的对象,降低系统创建对象实例的性能消耗。
在开发中,对于一些全局的工具类或策略类,应该尽可能考虑使用这些内存友好的模式。
单例模式比较常见,主要针对单对象的复用;享元模式主要针对多个相似对象的复用,参考文章:设计模式系列-享元模式
1.3 扩展
1.3.1 内存不足回调API的使用
SDK提供了两个低内存回调的方法,可以让应用获得内存不足的系统通知:
OnLowMemory是Android提供的API,在系统内存不足,所有后台程序(优先级为background的进程,不是指后台运行的进程)都被杀死时,系统会调用OnLowMemory。
OnTrimMemory是Android 4.0之后提供的API,系统会根据不同的内存状态来回调。我们可以根据不同的内存状态,来响应不同的内存释放策略,依次考虑释放的资源包括Bitmap、数组、控件资源等。
1.3.1.1 OnLowMemory
OnLowMemory是Android提供的API,在系统内存不足,所有后台程序(优先级为background的进程,不是指后台运行的进程)都被杀死时,系统会调用OnLowMemory。
系统提供的回调有:
l Application.onLowMemory()
l Activity.OnLowMemory()
l Fragement.OnLowMemory()
l Service.OnLowMemory()
l ContentProvider.OnLowMemory()
1.3.1.2 OnTrimMemory
OnTrimMemory是Android 4.0之后提供的API,系统会根据不同的内存状态来回调。系统提供的回调有:
l Application.onTrimMemory()
l Activity.onTrimMemory()
l Fragement.OnTrimMemory()
l Service.onTrimMemory()
l ContentProvider.OnTrimMemory()
OnTrimMemory的参数是一个int数值,代表不同的内存状态:
1. TRIM_MEMORY_COMPLETE:内存不足,并且该进程在后台进程列表最后一个,马上就要被清理
2. TRIM_MEMORY_MODERATE:内存不足,并且该进程在后台进程列表的中部;
3. TRIM_MEMORY_BACKGROUND:内存不足,并且该进程是后台进程;
4. TRIM_MEMORY_UI_HIDDEN:内存不足,并且该进程的UI已经不可见了;
以上4个是Android4.0增加的。
5. TRIM_MEMORY_RUNNING_CRITICAL:内存不足(后台进程不足3个),并且该进程优先级比较高,需要清理内存;
6. TRIM_MEMORY_RUNNING_LOW:内存不足(后台进程不足5个),并且该进程优先级比较高,需要清理内存;
7. TRIM_MEMORY_RUNNING_MODERATE:内存不足(后台进程超过5个),并且该进程优先级比较高,需要清理内存;
以上3个是4.1增加的。














 2305
2305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









