







基础知识准备
强化学习入门简单实例 DQN
强化学习入门 第一讲 MDP
随笔分类 - 0084. 强化学习
目标函数
首先需要定义目标函数来优化模型参数,此处使用的REINFORCE算法解决RL问题:

求导证明参考
OFF-POLICY纠偏
OFF-POLICY指的是要更新的策略和生成训练数据的策略并不是同一个策略,也就是除了存在一个RL算法外,还有其他算法也会产生推荐。那么这些策略混合在一起会生成训练数据,但生成的训练数据只在RL算法上用于更新。因此二者之间存在分布差异。作者引入 importance weighting 来解决该问题。

beta是混合策略,pai是RL策略。为解决bata策略与pai策略分布的差异,使用importance weight来纠偏。但是importance weight是一个链式乘法项。其会导致推测器的高方差。所以采用降低importance weight精准度(忽略项+一阶近似)来降低高方差。由公式(3)生成最终的梯度计算方法。
模型化策略PAI
policy gradient方法是输入状态S,输出动作A的分布。作者使用的chaos free rnn。


简而言之,模型初始状态服从一个初始分布,然后根据每一步的action,由rnn输出新的状态,在预测时,使用新状态特征与action特征内积形式输入softmax来输出动作分布。在实验中初始分布为0,context包括页数、设备、时间差等信息。对于0-reward的行为将不会用于参数更新。
混合策略beta的预测
在off-policy中,梯度计算涉及到beta分布值。但是在实际情况中,很多策略是无法控制的或者就是一些规则策略。因此作者重用了RNN模型,对于RNN模型输出的状态添加一个额外的head来预测beta分布,并且block该head的梯度传播。

Top-K Off-Policy纠偏
推荐系统需要一次性推荐K个item。作者采用迭代采样k个item来实现。



在梯度更新的纠偏上又加入了一项因素lamba。
其他方差降低方法

代码
非官方开源
这份代码只能走个过程,和论文差别很大。
Trick原理
log-derivative推导:

一阶近似公式:
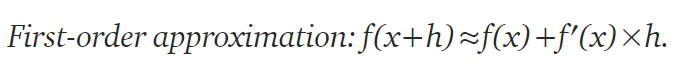















 821
821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









