









Top-K Off-Policy Correction for a REINFORCE Recommender System
创新点
具体方法
1. 解决on-policy与off-policy中数据有偏的问题
采用 importance sampling来对
π
\pi
π 进行加权
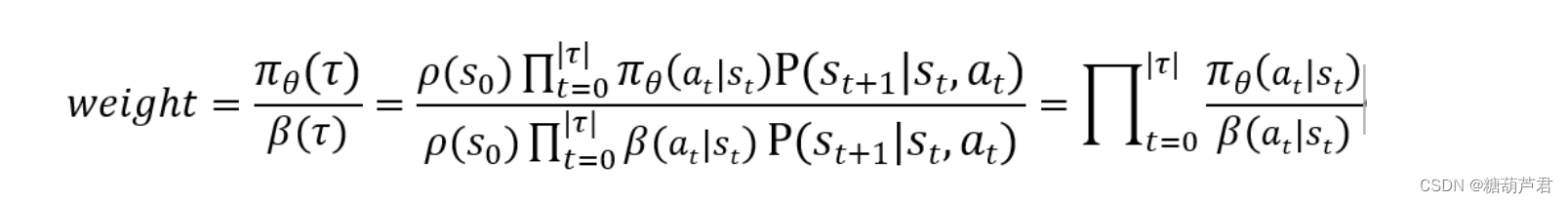
得到off-policy的gradient estimator后:
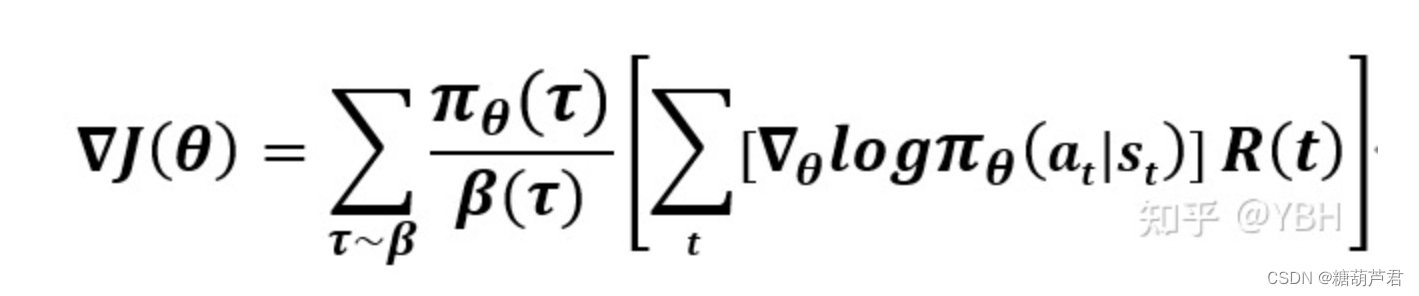
虽然偏差没有了,但是方差很大,为了减少方差,只考虑0-t时刻的,再做一阶近似:
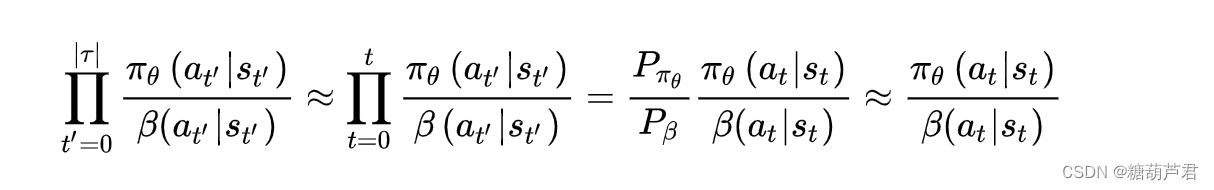
最终得到一个有偏但是方差更小的estimator:
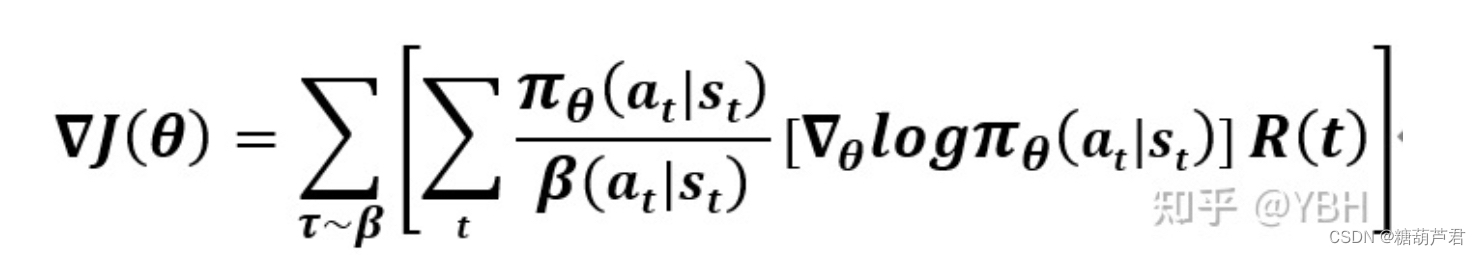
2. Parametrising the policy 𝜋𝜃
利用一个rnn网络来建模状态变化:
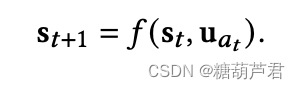
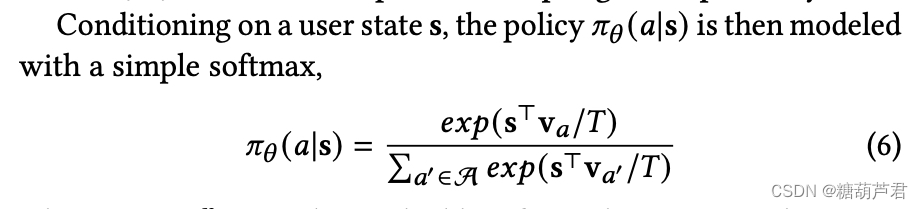
根据从behavior policy
β
\beta
β观测得到的trajctory ,根据rnn网络生成用户状态,得到
π
(
a
∣
s
)
\pi(a|s)
π(a∣s),进而计算policy gradient来更新policy.
3. Estimating the behavior policy 𝛽
off-policy 策略校正的一个困难是日和获得行为策略
β
\beta
β?

对于收集的每个状态-动作对 (𝑠,𝑎),使用另一个 softmax 的混合policy 来估计选择该动作的概率𝛽^𝜃′(𝑎|𝑠)。 如图 1 所示,从主策略重用 RNN 模型生成的用户状态𝑠,并使用另一个 softmax 层对混合策略进行建模。 为了防止行为干扰主策略的用户状态,阻止它的梯度回流到 RNN。
尽管 π ( a ∣ s ) \pi(a|s) π(a∣s)与 β \beta β共享了大量的参数,但是他们主要有两个区别:
- main policy π ( a ∣ s ) \pi(a|s) π(a∣s) 会使用long-term reward进行训练,而 behavior policy 只基于 state-action pairs进行训练;
- main policy head 𝜋𝜃 is trained using only items on the trajectory with non-zero reward 3, the behavior policy 𝛽𝜃′ is trained using all of the items on the trajectory to avoid introducing bias in the 𝛽 estimate.
4. TOP-K
每次选择K个action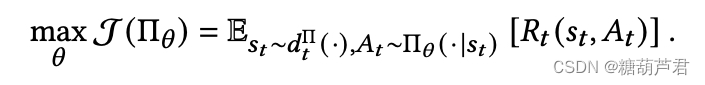
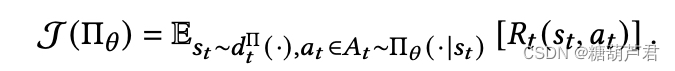
α
θ
(
a
∣
s
)
=
1
−
(
1
−
π
θ
(
a
∣
s
)
)
K
\alpha_{\theta}(a|s) = 1- (1-\pi_{\theta}(a|s))^K
αθ(a∣s)=1−(1−πθ(a∣s))K
梯度更新可以被简化为:
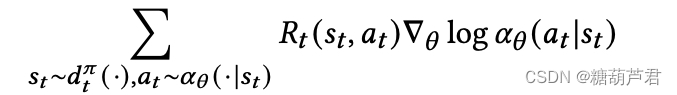
通过替代
π
\pi
π为
α
\alpha
α:
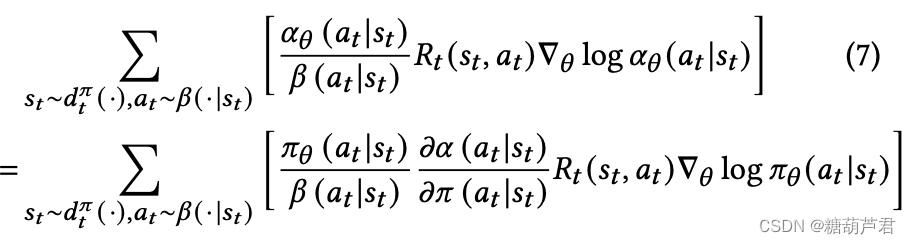
Top-K policy相比原先的policy增加了一项:
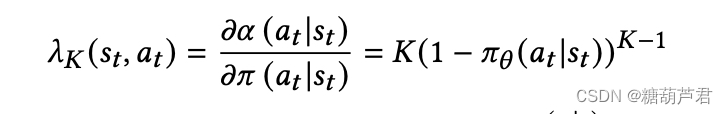
该方法具有如下性质:

起到的作用就是:当期望的item在 softmax 策略𝜋𝜃 (·|𝑠) 中的质量较小时,top-𝐾 校正比标准校正更积极地推高其可能性。 一旦 softmax 策略𝜋𝜃 (·|𝑠) 对期望的item 施加了合理的质量(以确保它可能出现在顶部-𝐾),然后校正会将梯度归零并且不再试图推高其可能性 . 这反过来允许其他可能感兴趣的item 在 softmax 策略中占据一些分量。
5. 降低方差
- Weight Capping
- Normalized Importance Sampling (NIS)
- TRPO:加入一个正则化项
相关方法
参考
- https://zhuanlan.zhihu.com/p/445564398














 1675
1675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









