







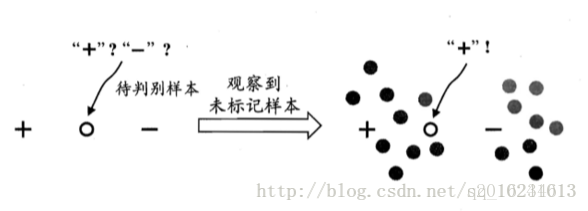
半监督学习有种思想:如下图,如果一个未标记样本所在空间附近只有一个正样本和一个负样本,不好判断到底该样本是正是负。但如果该样本周围存在一堆正负样本,那么我们可以根据它所处位置的远近来判断其属于置信度更大的类别。
co-training:

协同训练(co-training)算法是多视图(multi-view)学习的代表。首先解释下视图含义:以电影为例,它拥有多个属性集:图像、声音、字幕等。每个属性集就构成了一个视图。协同训练认为单凭一个视图,训练器就能取得一个很好的性能。如上图流程如下:
1. 从未标记数据集U上随机的选取u个示例放入集合U’中
2. 开始迭代k次:
在标记数据集L的不同视图x1和x2上训练出两个分类器h1和h2
用h1对U’中所有未标记元素进行标记,从中选出置信度高的p个正标记和n个负标记,加入到x2集合中
用h2对U’中所有未标记元素进行标记,从中选出置信度高的p个正标记和n个负标记,加入到x1集合中
随机从U中再选取2p+2n个数据补充到U’中
之所以将预测的未标记数据集加到另一个分类器的训练集中,因为对于本分类器来说,已经能够准确预测该未标记样本,再训练没有必要。
协同训练法要求数据具有两个充分冗余且满足条件独立性的视图。充分是指每个视图都包含足够产生最优学习器的信息,此时对其中任一视图来说,另一个视图则是冗余的; 同时,对类别标记来说这两个视图条件独立。然而现实生活中很难满足。Goldman 和Zhou提出了一种可用于单视图数据的协同训练法变体,通过使用两种不同的决策树算法在相同属性集上生成两个不同的分类器,然后按协同训练法的方式来进行分类器增强。
tri-training:
tri-training是单视图学习模型。流程如下:
1. 对有标记训练集进行重采样(bootstrap sampling)以获得三个有标记训练集
2. 从每个训练集产生一个分类器
3. 利用三个分类器以“少数服从多数”的形式来产生伪标记样本。若两个分类器将某个未标记样本预测为正类, 而第三个分类器预测为反类, 则该样本被作为伪标记正样本提供给第三个分类器进行学习
4. 最终三个分类器通过投票机制作为一个分类器集成进行使用
active-learning:
主动学习思想很简单,先使用已有的标记样本学习一个简单模型,然后使用该模型对未标记样本进行预测,根据预测结果选择一些模型认为比较难分的样本,如loss较高,置信度较低样本,把这些样本送给专业人士进行标记,然后将这些标记后的样本继续给模型训练。
原作者文章














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









