






目录
一、为什么用RNN
为了更好处理具有依赖关系序列数据,当前时刻的输出不仅需要考虑当前时刻的输入,同时也要考虑前面时刻的输入,序列数据模型
需要“知晓”序列全局的信息,也就是说模型需要有一定的“记忆能力”二、RNN结构、公式、缺点
2.1、RNN的两种图解
(1)图解一
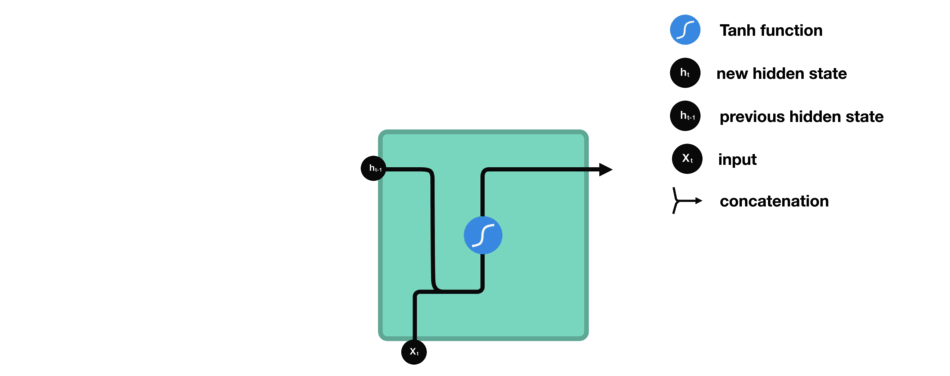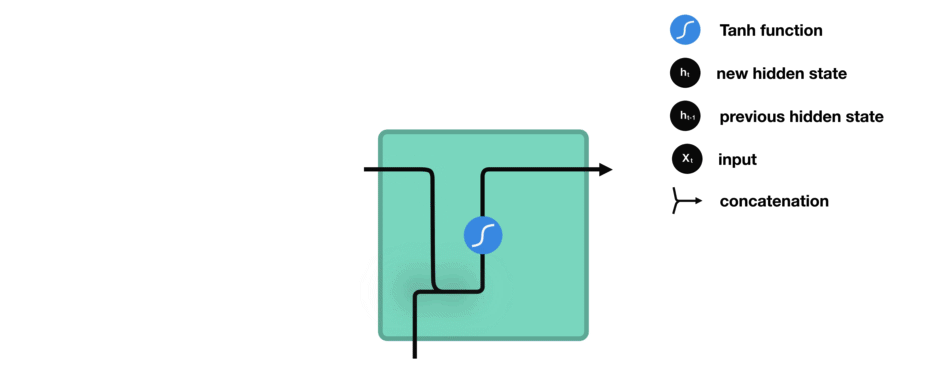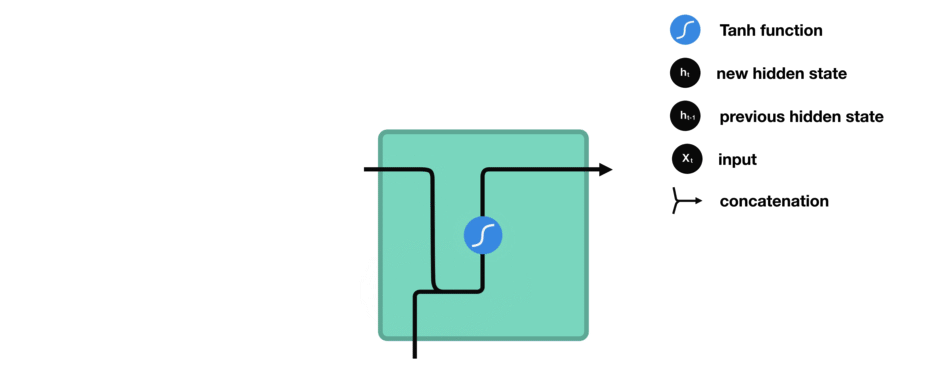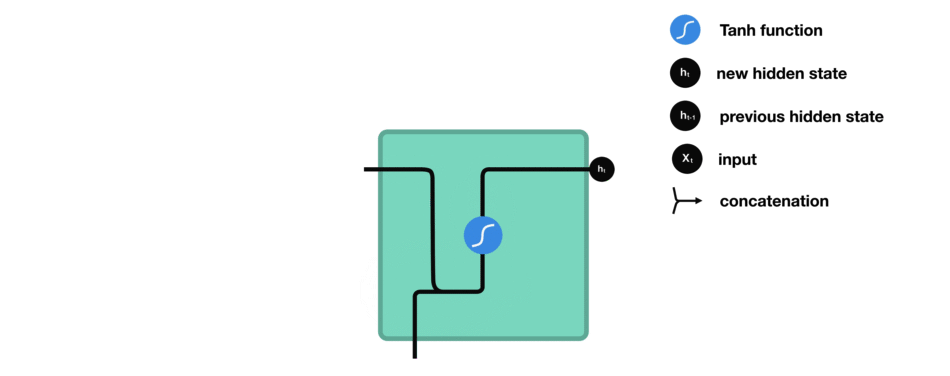

RNN网络的特点:
上一时刻的输入需要进行一次“激活”才能“添加”到当前时刻信息中,这就造成了RNN梯度消失短时间记忆问题,具体原因下文有
RNN梯度传导公式推导过程解答。具体可以参看这篇文章:LSTM和GRU的解析从未如此清晰(动图+视频)
(2)图解二

以上图解需要知道的点:
① 传统的RNN有3组参数 U、W、V,但实际上rnncell只有U、W两组参数,其中U参数计算当前时刻的输入信息,W参数计
算前面时刻的影藏状态信息。而V不属于rnncell的参数,它是输出层的参数,相当于全连接FC层,根据任务分类的标
签个数映射至相应的维度,激活函数通常为softmax,具体可以看下面的代码
② RNN 实际上计算时通常会将U、W参数进行合并
③ RNN、LSTM 通常不使用 relu函数进行激活,这是因为relu函数在多次时刻循环后可能会得到一个非常庞大的值,模型不稳定。
实际上 RNN 采用的是 tanh 激活 hidden state:
output layer:
2.2、RNN公式推导
2.2.1、RNN计算公式
hidden state:
output layer :
2.2.2、RNN梯度导链
① 这里假设t=3,O3的计算方式如下:

② 我们可以看到当t=3时,U的导链应当由3个部分构成:

③ 所以的梯度应该由三个导链的加和来完成

④ 从上面的式子可以看出链乘 是造成链式求导结果大小的决定项

从上式可以看出,求导的结果主要受到 tanh导数 与 W参数矩阵初始化值两者乘积影响:
① 梯度消失:一般情况下W的参数初始化都是较小的值,tanh的导数基本都小于1,两者相乘后的结果通常小于1,当t的
时刻较大时,前面信息的导链传导经过多次小于1的值进行相乘,导致整个导链的分支较小,所以当前时刻的梯度仅仅受
“紧挨”的时刻的导数值影响,这就是RNN“短记忆”的原因,分支梯度消失
解决方式:使用LSTM细胞状态开关门的结构
② 梯度爆炸:当 W 参数初始化较大时,容易产生梯度爆炸
解决方式:① 较小的 W 参数初始化 ② 使用梯度截取2.3、RNN的问题与缺点
1.RNN的两个结构图的画法
上文两种结构图
2.RNN公式推导
上文RNN计算的两个公式
3.RNN 多条支路导链公式(重点)
上文RNN导链推导公式(重点)
4.RNN为什么只能短期记忆?梯度消失与梯度爆炸的理解?怎么解决梯度消失与梯度爆炸?
RNN 所谓梯度消失的真正含义是,梯度被近距离梯度主导,模型难以学到远距离的依赖关系
- 怎么理解梯度消失: 由导链的推导公式可得,
的梯度是由所有时刻的梯度导链叠加而成,其中影响每条支路导链决定性项为
,它的值为
,W较小且导链较长时容易造成支链梯度消失,而那些距离输出时刻距离较近的时刻由于导链较短,受
梯度之和并不会消失。RNN 所谓梯度消失的真正含义是,梯度被近距离 梯度主导,导致模型难以学到远距离的依赖关系
- 怎么理解梯度爆炸:当
- 怎么理解RNN短期记忆:当
2.4、RNN手写代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class RNNCELL(nn.Module):
"""
定义一个rnn cell单元
"""
def __init__(self,input_size,hidden_size):
super(RNNCELL,self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.x2h = nn.Linear(input_size,hidden_size)
self.h2h = nn.Linear(hidden_size,hidden_size)
def forward(self,x,hx):
"""
x 维度:(B,D)
"""
hx = torch.tanh(self.x2h(x) + self.h2h(hx))
return hx
class RNN(nn.Module):
"""
定义 rnn网络 + Fc激活层
"""
def __init__(self,input_size,hidden_size,output_size):
super(RNN,self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
# rnn cell
self.rnn_cell = RNNCELL(input_size,hidden_size)
# 输出层fc层
self.fc = nn.Linear(hidden_size,output_size)
def forward(self,x):
"""
x 的维度 (B,T,D)
"""
if torch.cuda.is_available():
hx = torch.zeros((x.size(0),self.hidden_size)).cuda()
else:
hx = torch.zeros((x.size(0),self.hidden_size))
# 保存每一个时刻rnncel的输出,注意rnncell内部没有使用V矩阵参数
outs = []
for t in range(x.size(1)):
hx = self.rnn_cell(x[:,t,:],hx)
outs.append(hx)
# 输出层FC
ot = F.softmax(self.fc(outs[-1]),dim=-1)
return hx,outs,ot
if __name__ == '__main__':
input_size = 64
hidden_size = 128
output_size = 10 # 10分类的任务
model = RNN(input_size,hidden_size,output_size)
x = torch.rand((3,10,64))
hx,ot,outs = model(x)
print(hx) # 打印最后一个时刻的隐藏状态
print(outs) # 打印rnncell所有时刻的输出,注意rnncell内部没有使用V矩阵参数
print(ot) # 打印输出层softmax预测结果2.5、双向RNN

三、LSTM引入
3.1、RNN ——> LSTM图解

3.2、LSTM公式推导
六个公式如下
① 遗忘门、输入门、“候选门”、输出门
遗忘门:
输入门:
候选门:
输出门:
② 细胞状态
细胞状态更新:
③ 隐藏状态
输出:
3.3、LSTM问题与缺点
1.从结构上来说,为什么LSTM比RNN更容易记忆的更“深”【缓解了长序列梯度消失】?
- RNN梯度消失的真正含义是总梯度值总是近距离时刻梯度主导,模型较难学习到较远时刻的序列信息【原因见上文】
- 由RNN与LSTM的结构图来看,LSTM使用“门”控制贯穿整个序列的细胞状态C来进行信息传递,细胞状态C没有额外的参数与激活函数,因此不受激活函数梯度
2.LSTM一定解决了梯度消失与梯度爆炸吗?如果还存在怎么解决
1、梯度消失
1.1、是否解决梯度消失?
① LSTM仅仅缓解了水平方向的梯度消失,如果序列长度过长,依然可能会出现梯度消失
② LSTM垂直方向层次过深,会出现垂直方向梯度消失
2.2、LSTM解决梯度消失的思路
① 垂直方向不宜过深
② 序列过长时可以截取序列
2、梯度爆炸
LSTM 可以通过梯度截取来解决梯度爆炸3.4、LSTM手写代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class LSTMCELL(nn.Module):
"""
定义一个lstm cell
"""
def __init__(self,input_size,hidden_size):
super(LSTMCELL,self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# 输入xt 4组参数合并
self.x2h = nn.Linear(input_size,4*hidden_size)
# hidden state 4组参数合并
self.h2h = nn.Linear(hidden_size,4*hidden_size)
def forward(self,x,hx,cx):
"""
x 维度:(B,D)
"""
gates = self.x2h(x) + self.h2h(hx) # 维度:( B,4*hidden_size)
# 将gates 分成4份,分别为:遗忘门、输入门、候选门、输出门
forget_gate,input_gate,cell_gate,output_gate = gates.chunk(4,dim=-1)
forget_gate = torch.sigmoid(forget_gate)
input_gate = torch.sigmoid(input_gate)
cell_gate = torch.tanh(cell_gate)
output_gate = torch.sigmoid(output_gate)
# 细胞状态
cx = torch.mul(cx,forget_gate) + torch.mul(input_gate,cell_gate)
# hidden state
hx = torch.mul(torch.tanh(cx),output_gate)
return hx,cx
class LSTM(nn.Module):
"""
定义 lstm网络 + Fc激活层
"""
def __init__(self,input_size,hidden_size,output_size):
super(LSTM,self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
# lstm cell
self.lstm_cell = LSTMCELL(input_size,hidden_size)
# 输出层fc层
self.fc = nn.Linear(hidden_size,output_size)
def forward(self,x):
"""
x 的维度 (B,T,D)
"""
# 定义 hidden state 初始值
if torch.cuda.is_available():
hx = torch.zeros((x.size(0),self.hidden_size)).cuda()
else:
hx = torch.zeros((x.size(0),self.hidden_size))
# 定义 细胞状态初始值
if torch.cuda.is_available():
cx = torch.zeros((x.size(0),self.hidden_size)).cuda()
else:
cx = torch.zeros((x.size(0),self.hidden_size))
outs = [] #保存每一个时刻lstmcell的输出,其实就是对应每个时刻的 hidden state,注意lstmcell内部没有使用V矩阵参数
for t in range(x.size(1)):
hx,cx = self.lstm_cell(x[:,t,:],hx,cx)
outs.append(hx)
# 输出层FC
ot = F.softmax(self.fc(outs[-1]),dim=-1)
return hx,cx,outs,ot
if __name__ == '__main__':
input_size = 64
hidden_size = 128
output_size = 10 # 10分类的任务
model = LSTM(input_size,hidden_size,output_size)
x = torch.rand((3,10,64))
hx,cx,ot,outs = model(x)
print(model)
print(hx) # 打印最后一个时刻的隐藏状态
print(cx) # 打印最后一个时刻的细胞状态
print(outs) # 打印lstmcell所有时刻的输出,其实就是对应每个时刻的 hidden state,注意lstmcell内部没有使用V矩阵参数
print(ot) # 打印输出层softmax预测结果四、GRU引入
4.1、GRU 结构图

五、RNN与LSTM、GRU问题总结
1、RNN在训练过程中存在什么问题? 公式推导解释?如何解决?
- RNN容易出现梯度消失与梯度爆炸;【RNN公式推导见上文】;使用LSTM结构缓解
2、RNN梯度消失的本质是什么? 推导公式解释
- RNN梯度消失的真正含义是总梯度值总是近距离时刻梯度主导,模型较难学习到较远时刻的序列信息【原因见上文】
3、为什么RNN不用relu激活
- RNN具有循环过程,使用relu可能获得一个非常大的值。
4、 LSTM与RNN相比,有哪些特点?
- RNN梯度消失的真正含义是总梯度值总是近距离时刻梯度主导,模型较难学习到较远时刻的序列信息【原因见上文】
- 由RNN与LSTM的结构图来看,LSTM使用“门”控制贯穿整个序列的细胞状态C来进行信息传递,细胞状态C没有额外的参数与激活函数,因此不受激活函数梯度
5、请画出LSTM的基本结构与六个公式














 6258
6258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









