







一、线性回归的概念
1、线性的概念:将求 x --> y的映射关系 转化为 关于 θ 的线性回归,权重系数 θ 最高次幂是 1(与特征属性 X 的次数无关)。
2、线性回归的类型:有监督学习(y标签是连续的)
3、线性回归本质:构造一个函数,使得样本点均匀分布在该函数图像(二维:线、三维:面 ..... )的两侧
4、求解回归方程本质:求 最优 权重系数 θ 矩阵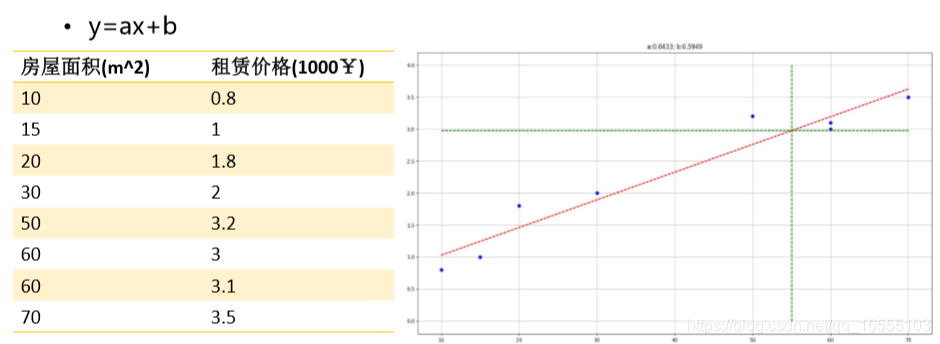
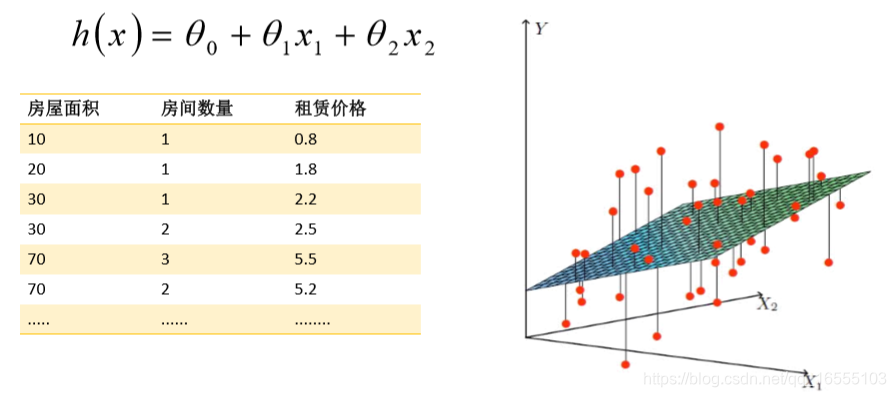
二、线性回归理论
1、前提:认为数据中存在线性关系,也就是特征属性X和目标属性Y之间 的关系是满足线性关系(暂定的概念)。
2、目的:在线性回归算法中,找出的模型对象是期望所有训练数据比较均 匀的分布在直线或者平面的两侧。
3、方法:在线性回归中,最优模型也就是所有样本(训练数据)离模型的直 线或者平面距离最小。
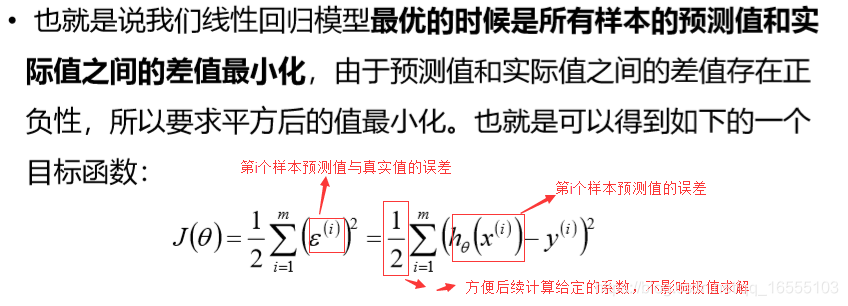
4、理论公式推导:① 最小二乘法 ② 极大似然估计1、构建回归方程
求最优函数 h(xi)与 样本真实值yi 误差平方和最小,其中未知权重系数参量 θ(它一个列向量)

2、求函数 h(x)未知参量 θ最优解
(1)最小二乘法
https://blog.csdn.net/qq_16555103/article/details/84862737 -------- 没有截距项的最小二乘法
- 过程推导

- 过程理解


θ 的最优解:

(2)极大似然估计
思想:
第i个样本在特征向量xi的条件下样本真实值yi的条件概率 P(yi|xi) 概率最大时即为ε ---> 0(此时 预测值 = 真实值,预测最优)
的时候,由中心极限定理知ε属于正态分布,又因为ε均匀分布在回归方程两侧,即ε属于标准正态分布,ε -> 0此时P(ε)最大,反之由
P(ε)最大 >>> P(yi|xi) 最大,令 P(yi|xi) = P(ε)求所有样本(样本之间独立)似然函数最大值即可。
- 理论推导


3、目标函数(损失函数)
- 没有正则项的目标函数

- 带有正则项的目标函数
L2正则项线性回归:Ridge回归
L1正则项线性回归:Lasso回归
=============================== L1正则、L2正则线性回归理解 ===========================================
1、理解:Ridge回归、Lasso回归本质上还是线性回归,只是在基础的LinearRegression模型求目标函数最小值结果上加上了一个需
要满足L1和L2正则项的条件。
2、l1 与 l2 正则缓解过拟合的原因是:约束了 w参数的大小,从而减少了噪声特征对整个线性式子的影响。

三、Python代码实现线性回归基础实现
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
X = np.array([
[10,1],
[20,1],
[30,1],
[30,2],
[70,3],
[70,2]
],dtype = 'float64')
Y = np.array([
[0.8],
[1.8],
[2.2],
[2.5],
[5.5],
[5.2]
],dtype = 'float64')
def func(X,Y,intercept = True): ------- intercept 是否预测截距
if intercept:
X0 = np.ones(shape=(X.shape[0],1),dtype='float64') ------ 根据特征属性矩阵的维度添加截距项
X_train = np.mat(np.hstack((X0,X))) ------ 转化为 矩阵类型
# X_train = [
# [1,10,1],
# [1,20,1],
# [1,30,1],
# [1,30,2],
# [1,70,3],
# [1,70,2]]
theta = (X_train.T * X_train).I * (X_train.T * Y) ---- 这里必须是matrix(矩阵数据类型)才可以进行操作; xxx.I xxx的转置(xxx必须是矩阵)
# θ = [[θ0],[θ1],[θ2]] ----- θ0 是回归方程的截距(是一个3*1列向量)
return theta,intercept,'截距为:{}'.format(theta[0,0]),'回归方程的权重参数为:'+ '、'.join([str(i[0]) for i in np.array(theta)]),\
'截距为:{}'.format(theta[0,0])
else:
X = np.mat(X,dtype= 'float64')
Y = np.mat(Y,dtype='float64')
theta = (X.T*X).I*(X.T*Y)
return theta,intercept,'回归方程的权重参数为:'+ '、'.join([str(i[0]) for i in np.array(theta)])
tmp = func(X,Y,False)
print(tmp)
theta = tmp[0]
intercept = tmp[1]
if intercept:
X0 = np.ones(shape=(X.shape[0], 1), dtype='float64')
X_train = np.mat(np.hstack((X0, X)))
X = X_train
print(X)
Y_train = np.mat(X) * theta
print(Y_train)
plt.plot(np.arange(len(Y_train)),Y_train)
plt.plot(np.arange(len(Y)),Y,'bo')
plt.show()四、sklearn库线性回归模型
https://scikit-learn.org/0.18/modules/classes.html#module-sklearn.linear_model -------- 线性模型API
1、基于sklearn库线性回归模型步骤
步骤:
1、收集数据、加载数据
2、数据清洗
3、提取特征属性矩阵 X 与 目标属性矩阵 Y
4、数据分割(测试集与训练集)
5、特征工程
6、构建模型
7、训练模型
8、模型测试预评估
9、模型部署与持久性
"""
方式一:直接将模型的预测结果保存数据库,应用的时候直接从数据库中获取预测结果。
方式二:直接将模型参数保存数据库,应用的时候直接从数据库中获取模型参数,然后根据算法原理还原模型。
方式三:通过sklearn的相关API将模型持久化为磁盘文件,应用的时候使用sklearn的相关API加载恢复模型。
"""2、基于sklearn库线性回归模型内置方法
线性回归常用的方法:
======================================================================================
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression,Ridge,Lasso
from sklearn.model_selection import train_test_split
--------------------------------------------------------------------------------------
class sklearn.linear_model.LinearRegression(fit_intercept=True, normalize=False, copy_X=True, n_jobs=1)
1、分割训练集: from sklearn.model_selection import train_test_split,KFold
1.1、X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.2,random_state=10)
# test_size 测试集占比;
# random_state 设置随机数种子
注意:train_test_split 对X、Y数据类型没有要求(矩阵、数组、DataFrame、Series均可)
特点:分割后的数据类型仍是原数据类型
2、构建模型对象 from sklearn.linear_model import LinearRegression,Ridge,Lasso
模型名 = LinearRegression(fit_intercept=True)
# fit_intercept表示是否训练截距项
3、训练模型对象
模型名.fit(训练集X, 训练集Y [, sample_weight=None])
4、模型评估:
结果 = 模型名.score(训练集X,训练集Y [, sample_weight=None])
结果 = 模型名.score(测试集X,测试集Y [, sample_weight=None])
特点:得出结果是R^2
5、模型预测:
结果 = 模型名.predict(预测集X) ---------- 这里的X必须写成二维数组的形式
注意:预测结果是一个一维数组(y多维是 矩阵),因此在与真实值进行画图比较时需要转化为二维的形式(.reshape(-1,1))
6、获取模型属性参数:
6.1 获取截距项
结果 = 模型名.intercept_ -------- 这里的结果是一个一维数组(y一维是一个值)
6.2 获取权重参数矩阵 θ
结果 = 模型名.coef_ -------- 这里的结果是一个二维向量(y多维时是 矩阵),因此做矩阵积时需要改变维度(.reshape(-1,1))
================================= 基于sklearn 模型下载 ===================================
from sklearn.externals import joblib
joblib.dump(模型名, './model/linear.pkl') --------- 模型下载(填写路径,大多用pkl做文件后缀)
模型名 = joblib.load('./model/linear.pkl') --------- 模型加载
3、最简单sklearn库线性回归模型实例:
'''基于sklearn库实现线性回归模型'''
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
mpl.rcParams['font.sans-serif'] = ['SimHei']
import time
#1、加载数据
path = r'./household_power_consumption_1000.txt'
df_data = pd.read_csv(path,sep=';')
# print(df_data.info())
#2、数据清洗
df_data.dropna(inplace=True)
df_data.loc[:,'Global_active_power':] = df_data.loc[:,'Global_active_power':].astype('float64')
# print(df_data.info())
# 3、根据需求提取特征属性矩阵X与目标属性矩阵Y
============== apply分割年月日 第一种方法(思想:两列分割后合并) -------------------------------------
def mkDay(once):
time_tuple = time.strptime(once,'%d/%m/%Y')
return pd.Series(time_tuple[0:3])
def mkHour(once):
time_tuple = time.strptime(once, '%H:%M:%S')
return pd.Series(time_tuple[3:6])
X = df_data.loc[:,'Date']
X1 = df_data.loc[:,'Time']
Y = np.array(df_data['Global_active_power']).reshape(-1,1)
X = np.array(pd.DataFrame(X.apply(mkDay))) ----------- 将原数据(DataFrame)中的时间分解开
X1 = np.array(pd.DataFrame(X1.apply(mkHour)))
X = np.hstack((X,X1))
#print(X,Y)
-----------------------------------------------------------------------------------------
===== apply分割年月日 第二种方法(思想:利用参数axis=1控制传入每次是一行;本质:将两列Series合为一列处理)-------
def format_time(row):
str_time = ' '.join(row) --------------- 传入行两列 Series 合并为 一列 Series
print(str_time)
tuple_time = time.strptime(str_time,'%d/%m/%Y %H:%M:%S')
return pd.Series((tuple_time.tm_year,tuple_time.tm_mon,tuple_time.tm_mday,tuple_time.tm_hour,tuple_time.tm_min,tuple_time.tm_sec)) #,
X = df_data[['Date', 'Time']]
X = X.apply(func = lambda row: format_time(row),axis=1)
Y = df_data['Global_active_power']
# X =
# 2006 12 16 17 24 0 -------- 年、月、日、时、分、秒
# 2006 12 16 17 25 0
# 2006 12 16 17 26 0
-------------------------------------------------------------------------------------
# 另一个预测,预测两个功率与电流的关系
# Y = df_data.loc[:,'Global_intensity']
# X = df_data.loc[:,['Global_active_power','Global_reactive_power']]
-------------------------------------------------------------------------------------
#4、数据分割
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.2,random_state=10)
#5、特征工程
"""
将数据从某个数据转换为另外的数据, eg:(1,2) --> (3,4)
这个变换的内部是存在一个转换的函数的。
这个转换函数需要根据当前操作的定义以及训练数据来得到。
并且在模型训练的时候,需要将训练数据和测试数据都用这个转换函数进行转换。
"""
#6、模型构建
linearModel = LinearRegression(fit_intercept=True)
#7、模型训练
linearModel.fit(X_train,Y_train)
#8、模型评估
print('训练集数据模型的R^2评测参数为:{}'.format(linearModel.score(X_train,Y_train)))
print('训练集数据模型的R^2评测参数为:{}'.format(linearModel.score(X_test,Y_test)))
# 查看模型参数:
print('线性回归模型截距为:{}'.format(linearModel.intercept_))
print('线性回归模型权重参数θ为:{}'.format(linearModel.coef_))
# 预测数据
结果 = 模型名.predict(测试集特征属性矩阵)
#图形化展示
一般将测试集的数据预测 与 真实值 数据作对比
------------------------- 手动计算 -------------------------------------------
# y_test = np.dot(X_test,linearModel.coef_.reshape(-1,1))+linearModel.intercept_
-------------------------- model.predict(测试集) -----------------------------
y_test = linearModel.predict(X_test).reshape(-1,1) ------------ 由于预测值是一维数组,所以画图时需要做
相应的转换。
y = np.array(Y_test).reshape((-1,1)) ------------ 将Series类型的y标签转化为二维数组。
print(y,type(y))
fig = plt.figure()
plt.plot(y,'r-',label = '真实值')
plt.plot(y_test,'g-',label = '预测值')
plt.xticks()
plt.legend()
plt.show()
#9、模型部署、持久化
五、线性回归过拟合、欠拟合
1、过拟合和欠拟合概念、原因、策略
一般情况下,模型的训练需要考虑两个方面:
1. 模型训练准不准(是否欠拟合) --- 可以通过模型的效果评估
2. 模型复杂度高不高(是否过拟合) --- 可以通过模型在训练数据和测试数据上的效果差异情况来比较 欠拟合、过拟合的直观表现:
1. 欠拟合 ---- 模型在训练数据上的效果都不佳
2. 过拟合 ---- 模型在训练数据上效果不错,但是在测试数据上效果不佳----------------------------------------------------------------------------------------
欠拟合:
体现:模型在训练数据上的效果都不佳
产生原因:模型没有学习到训练数据样本上的特征信息(特征属性X和目标属性Y之间的映射关系),所以效果不佳。
-1. 算法学习能力不强;
-2. 算法的模型参数可能不太合适;
-3. 样本数据量过少(数据中各种类型均有,只是数据量太少机器无法学习特征)或者过多;
-4. 可能训练数据中的特征属性X和目标属性Y之间的映射关系本身就不明显(特征属性太少了).
解决方案:
-1. 换一种强学习能力的算法;
-2. 进行交叉验证或者网格交叉验证来进行模型参数选择;
-3. 增加或者减少样本数据量;
-4. 利用集成学习的思想来解决欠拟合问题,主要是Boosting思想;
-5. 对训练用的特征属性做一定的分析,然后根据业务场景选择一些合适的特征属性进来(特征选择)。
-6. 可以考虑将特征数据映射到高维空间中,然后进行模型训练。(多项式扩展+线性回归)
• 加大模型规模(例如神经元/层的数量)
• 根据误差分析结果修改输入特征
• 减少或者去除正则化(L2 正则化,L1 正则化,dropout)
• 修改模型架构(比如神经网络架构)
---------------------------------------------------------------------------------------
过拟合:
体现:模型在训练数据上效果不错,但是在测试数据上效果不佳
产生原因:简单理解:模型学习到了过多无用的特征
详细理解:因为模型学习了太多的训练数据上的数据特征,把一些不是特别泛化的、大众的特征信
息也学习到了,所以导致模型最终在其它未知数据上效果不佳(未知数据不满足模型学习到的特征信息) ---> 有可能是训练
数据中存在噪音样本/异常样本,而训练模型将这个异常样本上的特征信息给学到了,但是未知的待预测样本上这个特征信
息是不存在(待预测样本不是异常样本)
-1. 算法的学习能力太强;
-2. 算法的模型参数可能不太合适;
-3. 样本数据量过少(样本量少,且样本过于特殊化);
-4. 训练数据特征属性过少,或者过于特殊化
-5. 训练数据中可能存在一些异常的特征属性/噪音特征属性
解决方案:
-1. 换一个弱学习模型(限制一下模型的学习能力);
-2. 进行交叉验证或者网格交叉验证来进行模型参数选择;
-3. 增加样本数据量;
-4. 利用集成学习的思想来解决过拟合问题,主要是Bagging思想;
-5. 加入正则:
① 加入 L2 正则 || W ||^2 或 L1 正则 | w | ,用于约束 w 参数的大小
② 对数据正则化,详见特征工程
-6. ADD noise 、dropout
• 添加更多的训练数据
• 加入正则化(L2 正则化,L1 正则化,dropout)
• 加入提前终止(Early stopping,例如根据开发集误差提前终止梯度下降)
• 通过特征选择减少输入特征的数量和种类
• 减小模型规模(比如神经元/层的数量
六、多项式线性回归
多项式线性回归:进行多项式扩展(特征工程)后再 进行线性回归(LinearRegression、Ridge、Lasso、弹性网络)1、多项式扩展 ----- 特征工程
理解:样本特征属性矩阵X的高维度扩展,为了模型能够更加清晰学习各个特征属性联合特征属性对目标矩阵的影响,样本点在
高维空间上会更加离散,
特点:多项式回归依然是线性回归,因为 θ 权重的最高次幂依然是1。
目的:解决由特征属性较少所引起的模型欠拟合问题(提高R^2指标),使低维空间原本样本数据线性关系弱 就有可能在高维空间
存在强的线性关系了。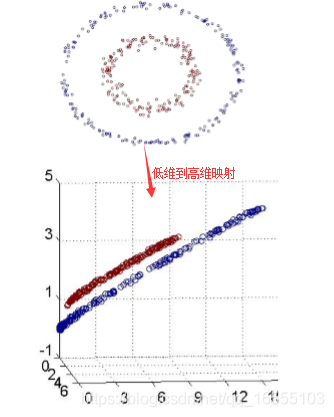
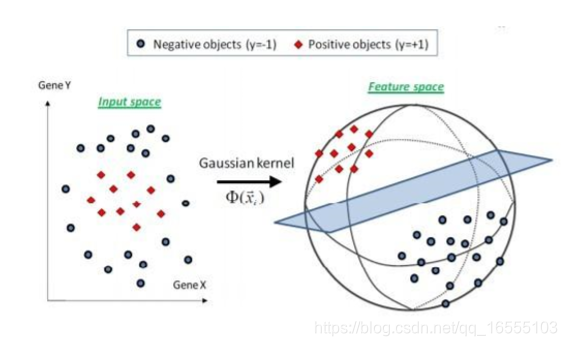
管道流模型 --------- 管道流只能有一个模型对象(最后一个),其他全部是特征工程对象。
因为sklearn中,所有的模型(特征工程+算法模型)的API基本是一致的,而且代码结构一般都是:
特征工程1 --> 特征工程2 --> 特征工程3 --> ..... --> 特征工程n --> 模型训练
因为Pipline中对于API做了一些简化,不需要我们主动的每个过程都调用fit以及transform,管道流对象中会主动的进行
API的调用。
sklearn API讲解:
fit:基于给定的训练数据进行模型/转换函数训练
transform: 基于训练好的转换函数对输入的数据进行转换操作
fit_transform: fit和transform的功能合并,首先使用给定的数据训练模型,然后用训练好的模型对数据做一个转换并输出
predict: 在算法模型中,用于模型数据的预测。- 多项式扩展后的特征效果(扩展前的特征属性: x0,x1,x2,x3,x4,x5 )

- 多项式扩展过拟合的原因 ------- 较高维度扩展时引起的参数 θ 过大
1、多项式过拟合的原因:多项式线性模型参数 θ 比较大的时候,也就是多项式维度扩展比较高的情况,是比较容易过拟合的。
2、解决方法:也就是使用L1正则或者L2正则来解决过拟合。
例:
9阶的时候的参数值:
[-2465.54964763 6108.55208593 -5111.92006214 974.73477787 1078.88147964 -829.49081668
266.12839436 -45.71673313 4.11576507 -0.15280829]
当x为-1的时候,预测值为:
y_predict = -2465.54964763 - 6108.55208593 -5111.92006214 - 974.73477787 + 1078.88147964 + 829.49081668
+ 266.12839436 + 45.71673313 + 4.11576507 + 0.15280829 = -12436.2705764 ---- 过拟合
七、Ridge回归、Lasso回归
0、l1 与 l2 正则缓解过拟合的原因是:① 约束了 w参数的大小,从而减少了噪声特征对整个线性式子的影响。
② 加入正则相当于加入了先验知识,在数据量越少的时候,先验概率越重要,因此,数据
较少的时候加入正则模型的效果提升越多. 例如加入 L2 正则相当于模型加入了
模型参数属于正态分布的先验知识.
1、概念:
Ridge回归:L2正则项的回归
Lasso回归:L1正则项的回归
弹性网络:L2、L1正则的混合
2、L2、L1正则项的作用: ------- 它们都可以解决过拟合问题,他还可以解决多重线性特征模型的空间不稳定性(通过减小多
重共线特征的权重大小)。
其中 L1 正则还可以用于 特征选择
2.1 L2、L1 代表损失函数屈最小值时必须满足 L2、L1所围成的面积,类似 拉格朗日函数约束条件。
2.2 L2正则通常用作解决模型的过拟合问题。L1正则也可以解决过拟合问题,但是它通常用作特征提取。
2.3 惩罚项系数λ越大,表示模型对 θ 允许的 大小越小,反之,对 θ 约束越小。
3、L2、L1正则的区别:
最主要的区别: L2 是 no sparse, L1 是 sparse
3.1 L2正则( no sparse ), 各个参数的范围是缩放到一个圆内的,因此极难出现某个维度θ出现为0的情况,即不会产生稀释解。
L2 Ridge模型效果稳定,鲁棒性强(Lasso去除噪声特征)
在最小二乘中,X.T * X可能是不可逆的矩阵,加入 L2正则的损失函数,w = (X.T * X + λ * I)^ -1 * X.T * Y
3.2 L1(sparse) 各个参数的范围是缩放到一个折线内的,因此很容易出现稀释解,常作为特征提取后用 Ridge回归模型 预测。
L1 Lasso回归模型计算速度快
3.3 L1 正则 特征选择的出现的问题:
Grouping Effect:对一个相关性特征的组中,Lasso 随机选择一个特征作为该组的特征,有可能该特征并非是该组最好的特征。
解决手段:
使用Elasitc Net,同时,考虑稳定性也考虑求解的速度
4、稀释解:稀释解可以帮助模型去除冗余的噪声特征,可以增加模型的鲁棒性(泛化能力)
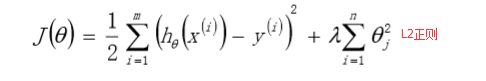
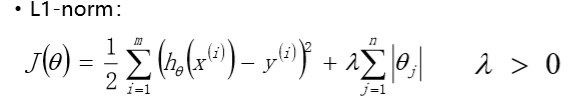
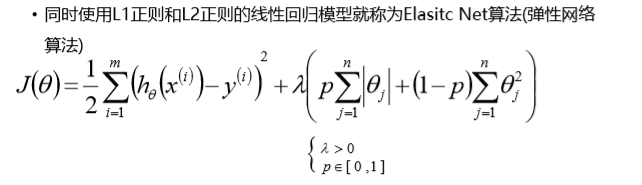
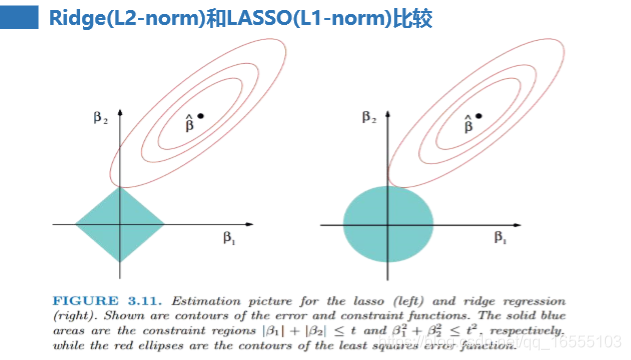
1、常见LOSS优化方法与 Lasso Ridge 损失函数优化方式
1、常见 LOSS 优化方法:
① 基于 一阶 梯度优化(gradient descent) LOSS:代表 GD BGD SGD MBGD
② 基于 二阶 梯度优化LOSS:代表 牛顿法,拟牛顿法
② 基于 坐标轴下降法(coordinate descent) :
有些 LOSS 函数 可能中间存在这不可导的点,而这些点就不能使用基于梯度下降的算法,例如 Lasso 回归的LOSS,因而可以
使用 坐标轴下降法
2、Ridge LOSS 优化:
处处可导,可以使用 梯度下降
3、Lasso LOSS 优化:
存在不可导的点,需要使用一部分 坐标轴下降法八、k折交叉验证、网格交叉验证
1、模型参数:
需要在训练数据上根据某种既定的算法来模型训练找出来的特征参数,是和数据有关的一个参数,也就是需要训练的参数,比如:线性回归中的θ
2、超参数:
在模型训练过程中算法需要使用到的参数值,和数据是没有直接关系的,但是该参数值会影响最终的模型效果,所以需要开发人员给定,比如:Ridge算法中的正则项系数lambda....
3、给定方式:
-1. 可以根据对算法模型理解、业务背景的理解来给定;
-2. 使用sklearn的中支持交叉验证的相关API来做模型参数的选择(所有正常API后面加CV这两个单词的都是支持交叉验证的)
-3. 使用网格交叉验证来给定模型的超参数(内部实际上就是交叉验证)
交叉验证:
交叉验证一般处于模型训练阶段,一般用于模型参数的选择。
--------------------------------------------------------------------------------------------
4、K折交叉验证:
步骤:
-1. 将fit传入的train数据划分为K份;
-2. 使用其中K-1份数据作为训练数据,使用另外一份数据作为测试数据;使用训练数据训练模型,然后使用测试数据来验证模型效果;
-3. 更改不同的数据组合,产生不同的训练数据和测试数据,分别训练在当前模型参数情况下的摸效果;
-4. 将当前参数在当前所有训练数据组合上的模型效果求一个均值作为当前模型参数在当前数据上的效果评估;
-5. 将效果做一个输出,就完成K折交叉验证。
5、留一交叉验证:
实际上就是n折交叉验证(n是样本数目)
含义:每次使用n-1条数据训练模型,然后使用另外1条数据来验证模型效果。
6、网格交叉验证:
步骤:
-1. 计算出所有的参数组合;
-2. 将fit传入数据train划分为K份;
-3 对于当前参数组合,使用其中K-1份数据作为训练数据,使用另外一份数据作为测试数据;使用训练数据训练模型,然后使用测试数据来验证模型效果;
-4. 更改不同的数据组合,产生不同的训练数据和测试数据,分别训练在当前模型参数情况下的摸效果;
-5. 将当前参数在当前所有训练数据组合上的模型效果求一个均值作为当前模型参数在当前数据上的效果评估;
-6. 更改参数组合(选一组新的参数),分别重复上述3、4、5步,得到每个参数组合的效果评估;
-7. 选择效果最好的模型参数输出作为最优的模型参数。九、梯度下降
1、梯度下降的使用场景:
1.1、梯度下降用凸函数的求解。
1.2、梯度下降用于无约束条件求极值的问题。
2、坐标轴下降法:
pass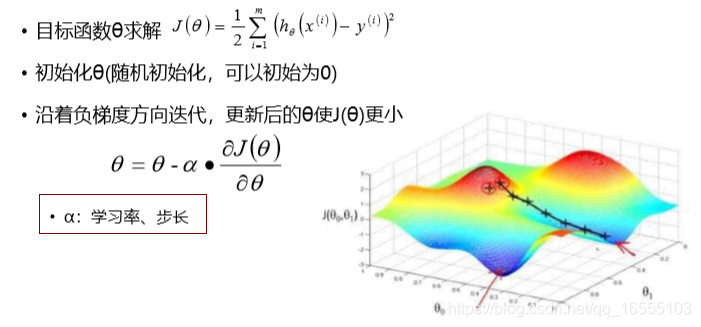
3、什么是梯度下降?BGD、SGD、MBGD这三种有什么区别?调优策略?
1.1 它是一种迭代更新的算法,求解无约束条件下凸函数的极值问题。
1.2 BGD叫批量梯度下降,它是需要所有样本梯度累加后 更新一次模型参数,循环迭代至终止条件;公式为:pass
SGD叫随机梯度下降,它指的是每次更新模型参数只需要一个样本,循环迭代至终止条件;公式:pass
MBGD小批量随机梯度下降,结合BGD与SGD的优缺点。公式:pass
BGD更新速度较慢,但它比较稳定,可以抗拒较多异常样本
SGD更新速度比BGD要快,但它需要训练集异常样本较少;SGD受到异常样本的影响,有可能跳出局部最优解,在训练集
中有大量正常样本是效果不会比BGD差太多,SGD在最优解收敛时会出现波动。
MBGD保证算法的训练过程比较快,又需要保证最终参数训练的准确率。
1.3 调优策略?
学习率的选择:学习率较大时,可能回跳过局部最优甚至发散。学习率较小时迭代速度较慢。
初始值的选择:梯度下降是一种局部最优的求解方法,因而初始值不同会导致模型求解结果不同,因此我们可以取不
同的初始值,求得使得损失函数最小的参数作为模型最优参数。
标准化:由于样本不同特征的取值范围不同,可能会导致在各个不同参数上迭代速度不同,为 了减少特征取值的影响,可
以将特征进行标准化操作。1、线性回归BGD
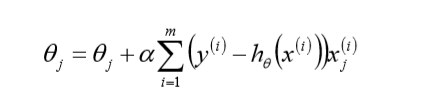
2、线性回归SGD

3、 线性回归MBGD
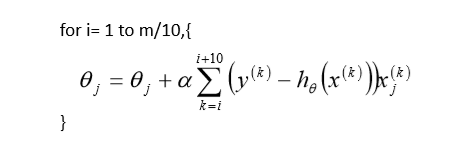
十一、线性回归的API使用
import os,time,re
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import sklearn
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split,KFold,GridSearchCV
from sklearn.metrics import r2_score,mean_squared_error,mean_absolute_error
from sklearn.model_selection import KFold
from sklearn.externals import joblibX_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.2,random_state=28) ---- 分割数据1、基础线性回归
linearModel = LinearRegression(fit_intercept=True)属性:
linearModel.coef_ --------- 返回是一个二维数组(一个权重系数向量)
linearModel.intercept_ --------- 返回是一个一维数组
方法:
linearModel.fit(X_train,Y_train)
linearModel.predict(X_test)
linearModel.score(X_train,Y_train)
linearModel.score(X_test,Y_test)
linearModel.get_params()
linearModel.set_params()2、多项式线性回归
多项式扩展 + 线性回归(Ridge、Lasso)
Ploy = PolynomialFeatures(degree=2)
Lr = LinearRegression(fit_intercept=False)
algo = Pipeline(steps=[
('Poly',Ploy), ----- 左边的参数是后面模型的key,右边的参数是模型对象
('Lr',Lr)
])3、Ridge线性回归
from sklearn.linear_model import RidgeCV, Ridge
linearModel = Ridge(alpha=1.0, cv=3, fit_intercept=True)
属性:
参考基本线性回归
-------------------------------------------------------------------------------------------------
linearModel = RidgeCV(alphas=[0.001, 0.01, 0.1, 10.0], cv=3, fit_intercept=True)
属性:
linearModel.coef_ --------- 返回是一个二维数组(一个权重系数向量)
linearModel.intercept_ --------- 返回是一个一维数组
linearModel.alpha_ --------- 估计惩罚项系数4、Lasso线性回归
from sklearn.linear_model import LassoCV, Lasso
algo = LassoCV(alphas=[0.001, 0.01, 0.1, 10.0], cv=3, fit_intercept=True)
algo = Lasso(alpha=1.0, cv=3, fit_intercept=True)5、弹性网络回归
class sklearn.linear_model.ElasticNet(alpha=1.0, l1_ratio=0.5, fit_intercept=True,
normalize=False, precompute=False, max_iter=1000, copy_X=True, tol=0.0001,
warm_start=False, positive=False, random_state=None, selection='cyclic')
'''
alpha=1.0 ------ 惩罚项系数
l1_ratio=0.5 ------ l1、l2的比例
fit_intercept=True ------ 是否训练截距项
'''6、管道流
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline- 管道流 -------- 注意: 管道流操作训练以后 训练集测试集 还是原来的特征向量,内部仅仅用的copy数据。
algo = Pipeline(steps=[
('Poly',Ploy), ----- 左边的参数是后面模型的key,右边的参数是模型对象
('Rg',Rg)
])
'''
steps ---- 管道流的步骤
'''
"""
steps: 给定管道流中的执行步骤,除了最后一步属于算法模型外,前面的均为特征工程操作。
在管道流训练的时候,训练方式等价于:
pipline.fit(x_train, y_train) ==> 触发内部的模型训练操作,除了最后一步外,其它所有操作调用对应的fit_transform API
poly.fit(x_train, y_train)
x_train = poly.transform(x_train)
lr.fit(x_train, y_train)
或者理解为:
lr.fit(
poly.fit_transform(x_train, y_train),
y_train
)
pipline.predict(x_test) ==> 触发内部的模型转换以及模型预测功能,除了最后一步外,其它的全部调用transform API
x_test = poly.transform(x_test)
lr.predict(x_test)
或者
lr.predict(poly.transform(x_test))
"""
algo.set_params(Poly__degree = 5)
print('多项式展开后Poly函数信息:',algo.get_params()['Poly'])
# 训练模型
algo.fit(X_train,Y_train) ------- 管道模型对象 algo
print("训练线性回归模型的格式为:{}".format(np.shape(algo.get_params()['Poly'].transform(X_train))))
------ 注意 管道流操作 训练以后 返回的训练集测试集还是原来的特征向量,可以通过这种方式查看扩展后的数据
# 模型评估
print("训练线性回归模型的格式为:{}".format(np.shape(X_train)))
------ 注意 管道流操作 训练以后 返回的训练集测试集还是原来的特征向量
print('多项式展开后的训练集的R方值:',algo.score(X_train,Y_train))
print('多项式展开后的测试集的R方值:',algo.score(X_test,Y_test))
print('多项式展开后Lr模型的权重参数:',algo.get_params()['Lr'].coef_)
print('多项式展开后Lr模型的权重参数:',Lr.coef_)
print('多项式展开后Lr模型的截距参数:',algo.get_params()['Lr'].intercept_)
print('多项式展开后Lr模型信息:',algo.get_params()['Lr']) # {'copy_X': True, 'fit_intercept': False, 'n_jobs': None, 'normalize': False}
print('多项式展开后Poly模型信息:',algo.get_params()['Poly'].get_feature_names())
print('多项式展开后Poly模型信息:',Ploy.get_feature_names())
# 可视化:
Y_testPredict = algo.predict(X_test).reshape(-1,1)
Y_testTrue = np.array(Y_test).reshape(-1,1)
fig = plt.figure()
plt.plot(Y_testPredict,'g-',label = 'Predict')
plt.plot(Y_testTrue,'r-',label = 'True' )
plt.legend()
plt.show()
属性:
方法:
algo.get_params()['Poly'] --- 取管道流的模型对象。
algo.set_params(Poly__degree = 5) --- pipeline 设置参数需要用两个下划线:'key名__参数名'
- 多项式扩展
Ploy = PolynomialFeatures(degree=2) # degree ----- 给定扩展多项式的维度
属性:
方法:
Ploy.get_feature_names() ------------- 获取扩展后的特征属性名的 一维数组
fit(X [,y]) 计算输出功能的数量。
fit_transform(X [,y]) 适合数据,然后转换它。
get_feature_names([input_features]) 返回输出要素的要素名称
get_params([深]) 获取此估算工具的参数。
set_params(\ * \ * PARAMS) 设置此估算器的参数。
transform(X [,y]) 将数据转换为多项式要素7、KFold ----- K折交叉认证
1、第一种:sklearn 内的模型
kf = KFold(n_splits=5,shuffle=True,random_state=10)
'''# 定义一个KFold的对象
# KFold一般用于查看模型在当前数据集上的整体效果
'''
2、第二种:sklearn 内置方法
sklearn.model_selection.cross_val_score(estimator, X, y=None, groups=None, scoring=None,
cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch='2*n_jobs')
sklearn.model_selection.cross_val_predict(estimator, X, y=None, groups=None, cv=None,
n_jobs=1, verbose=0, fit_params=None, pre_dispatch='2*n_jobs', method='predict')
'''
estimator = ? ------ 用于加叉验证的模型
X, y=None, ------ 训练集 X Y
cv=None ------ 几折加叉验证
scoring=None ------ 交叉验证的评估指标
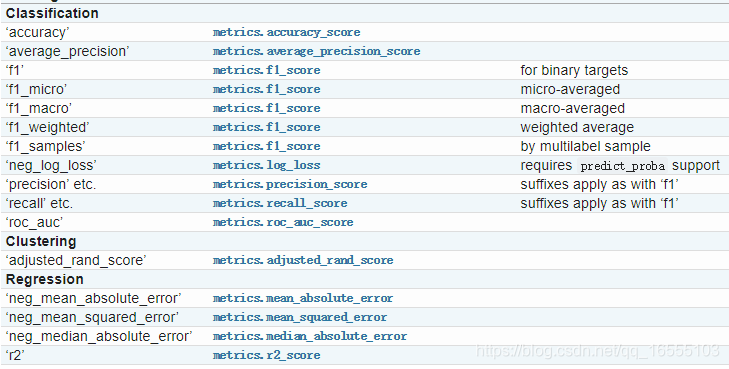
https://scikit-learn.org/0.18/modules/model_evaluation.html#scoring-parameter
'''
# 分割训练集与测试集 --------- KFold 不需要用 train_test_split 进行分割
'''# 定义一个KFold的对象
# KFold一般用于查看模型在当前数据集上的整体效果
'''
kf = KFold(n_splits=5,shuffle=True,random_state=10)
R2_Train_scoresList = []
R2_Test_scoresList = []
Train_MSEList = []
for train_index,test_index in kf.split(X):
# print(train_index) # 返回时一个索引值,使用时需要将原数据转化为数组类型
# print(test_index)
X_train = np.array(X)[train_index]
X_test = np.array(X)[test_index]
Y_train = np.array(Y)[train_index]
Y_test = np.array(Y)[test_index]
print("数据Y的格式:{}, 以及Y的数据类型:{}".format(np.shape(Y_test), type(Y_test)))8、GridSearchCV ------- 网格交叉认证
1、注意:
1.1、管道流操作训练以后 训练集测试集 还是原来的特征向量,内部仅仅用的copy数据
1.2、GridSearch只能得到最优的模型参数,不能获得所有参数组的结果(需要自己写for循环遍历参数组加叉验证)from sklearn.model_selection import GridSearchCV
GridCV = GridSearchCV(estimator= algo,param_grid = param_grid,cv= 5 )
'''
estimator= algo ------- 用于网格交叉验证的模型,可以是Pipeline流
param_grid = param_grid ------- 网格交叉验证的参数组,它是一个字典类型的,value是参数列表
cv= 5 ------- 每组参数做几折交叉验证
'''
'''
注意:网格交叉验证不能接直接使用 GridSearchCV 中的模型调用内部参数,需要用网格交叉验证
gridcv.best_estimator_.get_params()['dtree'] 获取最优模型
'''
属性:
best_estimator_:估算器
通过搜索选择的估计器,即在左数据上给出最高分(或如果指定的最小损失)的估计器。如果refit = False,则不可用。
best_score_:float
左侧数据的best_estimator得分。
best_params_:dict
参数设置可在保持数据上获得最佳结果。
best_index_:int
cv_results_对应于最佳候选参数设置的(数组的)索引。
方法:
fit(X [,y,groups]) 运行适合所有参数集。
get_params([深]) 获取此估算工具的参数。
inverse_transform(\ * args,\ * \ * kwargs) 使用找到的 最佳参数 在估计器上调用inverse_transform。
predict(\ * args,\ * \ * kwargs) 使用找到的最佳参数在估算器上调用预测。
predict_log_proba(\ * args,\ * \ * kwargs) 使用找到的 最佳参数 在估算器上调用predict_log_proba。
predict_proba(\ * args,\ * \ * kwargs) 使用找到的 最佳参数 在估算器上调用predict_proba。
score(X [,y]) 如果估计器已经重新调整,则返回给定数据的分数。
set_params(\ * \ * PARAMS) 设置此估算器的参数。
transform(\ * args,\ * \ * kwargs) 使用找到的 最佳参数 调用估计器上的变换。
==========================================================================================
Rg= Ridge(alpha=0.5,fit_intercept=False)
algo = Pipeline(steps=[
('Poly',Ploy),
('Rg',Rg)
])
'''
GridSearchCV
'''
param_grid ={
'Poly__degree':[2,3,4],
'Rg__fit_intercept':[False,True],
'Rg__alpha':[0.5,1.1,5],
'Rg__random_state':[10,25]
}
GridCV = GridSearchCV(estimator= algo,param_grid = param_grid,cv= 5 )
# 训练模型
GridCV.fit(X_train,Y_train)9、metrics 库 -------- 参数顺序:Y真实值、Y预测值
YY_train_predict = algo.predict(X_train)
YY_train = Y_train
print('手动计算R方值:{}'.format(1- (np.sum((YY_train_predict - YY_train)**2)) / (np.var(YY_train)*np.size(YY_train))))
print('多项式展开后的训练集的R值:{}'.format(r2_score(YY_train,YY_train_predict)))
----- 与.score() 不同,这里必须传入 y的真实值与预测值
print('多项式展开后的训连集的MSE:{}'.format(mean_squared_error(YY_train,YY_train_predict)))
----- 与.score() 不同,这里必须传入 y的真实值与预测值
print('多项式展开后的训连集的RMSE:{}'.format(np.sqrt(mean_squared_error(YY_train,YY_train_predict))))
print('多项式展开后的训连集的MAE:{}'.format(mean_absolute_error(YY_train,YY_train_predict)))Classification metrics
See the Classification metrics section of the user guide for further details.
metrics.accuracy_score(y_true, y_pred[, ...]) Accuracy classification score.
metrics.auc(x, y[, reorder]) Compute Area Under the Curve (AUC) using the trapezoidal rule
metrics.average_precision_score(y_true, y_score) Compute average precision (AP) from prediction scores
metrics.brier_score_loss(y_true, y_prob[, ...]) Compute the Brier score.
metrics.classification_report(y_true, y_pred) Build a text report showing the main classification metrics
metrics.cohen_kappa_score(y1, y2[, labels, ...]) Cohen’s kappa: a statistic that measures inter-annotator agreement.
metrics.confusion_matrix(y_true, y_pred[, ...]) Compute confusion matrix to evaluate the accuracy of a classification
metrics.f1_score(y_true, y_pred[, labels, ...]) Compute the F1 score, also known as balanced F-score or F-measure
metrics.fbeta_score(y_true, y_pred, beta[, ...]) Compute the F-beta score
metrics.hamming_loss(y_true, y_pred[, ...]) Compute the average Hamming loss.
metrics.hinge_loss(y_true, pred_decision[, ...]) Average hinge loss (non-regularized)
metrics.jaccard_similarity_score(y_true, y_pred) Jaccard similarity coefficient score
metrics.log_loss(y_true, y_pred[, eps, ...]) Log loss, aka logistic loss or cross-entropy loss.
metrics.matthews_corrcoef(y_true, y_pred[, ...]) Compute the Matthews correlation coefficient (MCC) for binary classes
metrics.precision_recall_curve(y_true, ...) Compute precision-recall pairs for different probability thresholds
metrics.precision_recall_fscore_support(...) Compute precision, recall, F-measure and support for each class
metrics.precision_score(y_true, y_pred[, ...]) Compute the precision
metrics.recall_score(y_true, y_pred[, ...]) Compute the recall
metrics.roc_auc_score(y_true, y_score[, ...]) Compute Area Under the Curve (AUC) from prediction scores
metrics.roc_curve(y_true, y_score[, ...]) Compute Receiver operating characteristic (ROC)
metrics.zero_one_loss(y_true, y_pred[, ...]) Zero-one classification loss.
Regression metrics
See the Regression metrics section of the user guide for further details.
metrics.explained_variance_score(y_true, y_pred) Explained variance regression score function
metrics.mean_absolute_error(y_true, y_pred) Mean absolute error regression loss
metrics.mean_squared_error(y_true, y_pred[, ...]) Mean squared error regression loss
metrics.median_absolute_error(y_true, y_pred) Median absolute error regression loss
metrics.r2_score(y_true, y_pred[, ...]) R^2 (coefficient of determination) regression score function.10、保存、加载模型
from sklearn.externals import joblib
path_Poly = './models/poly1.pkl'
path_algo = './models/algo.pkl'
for once in [path_Poly,path_algo]:
path_dir = os.path.dirname(once) # ./models
if not os.path.exists(path_dir):
os.makedirs(path_dir)
joblib.dump(Poly,path_Poly)
joblib.dump(algo,path_algo)
-----------------------------------------------------------------------------------------------------------
免费数据
https://archive.ics.uci.edu/ml/datasets.html

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









