







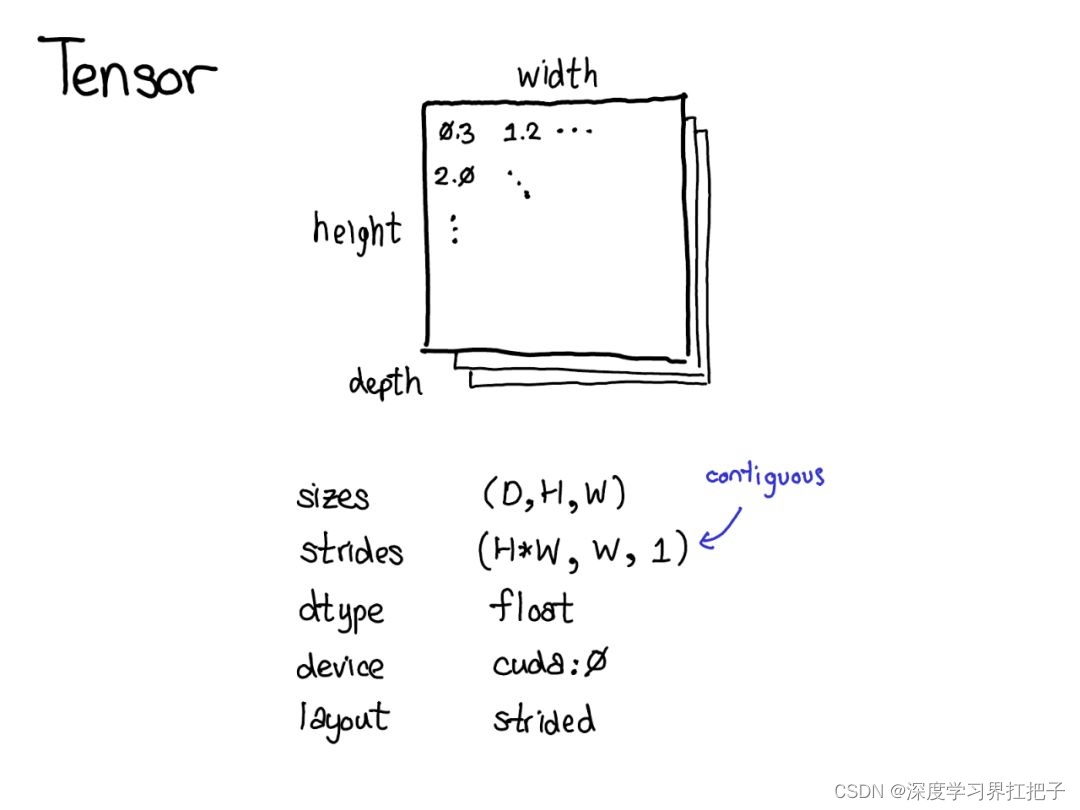
张量(Tensors):PyTorch的核心数据结构,用于存储和操作多维数组。
自动微分(Autograd):PyTorch的自动微分引擎,可以自动计算梯度,这对于训练神经网络至关重要。
数据加载和预处理:了解如何使用PyTorch的数据加载器(DataLoader)和转换(Transform)来加载和预处理数据。
神经网络模型:
常用的神经网络层:如全连接层、卷积层、循环层等。
常用的神经网络结构:如多层感知机(MLP)、卷积神经网络(CNN)、循环神经网络(RNN)和长短时记忆网络(LSTM)等。
模型的构建和训练:掌握如何定义神经网络模型,如何设置损失函数和优化器,以及如何训练模型。
深度学习优化算法:
梯度下降算法及其变种(如随机梯度下降、批量梯度下降、Adam等)。
正则化技术(如L1、L2正则化,Dropout等),以防止过拟合。
PyTorch高级特性:
动态图计算:PyTorch使用动态图进行计算,这使得模型构建和调试更加灵活。
分布式训练:了解如何在多台机器上并行训练模型,以加速训练过程。
模型部署和导出:了解如何将训练好的模型部署到生产环境,以及如何将模型导出为其他格式供其他平台使用。
自然语言处理(NLP)基础:
词嵌入(Word Embeddings):了解如何将单词表示为向量形式,以便在神经网络中使用。
序列模型:如RNN、LSTM和Transformer等,在NLP任务中非常重要。
NLP任务:如文本分类、情感分析、命名实体识别等,了解这些任务的基本概念和评估方法。
以下是一个简单的示例,展示了如何使用PyTorch来实现一个简单的文本分类任务(例如,情感分析):
首先,你需要安装PyTorch和torchtext库(用于数据加载和处理)。你可以使用pip来安装:
bash
pip install torch torchtext
接下来是一个简单的PyTorch NLP代码示例:
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.legacy.data import Field, TabularDataset, BucketIterator
# 定义字段
TEXT = Field(sequential=True, tokenize='spacy', lower=True)
LABEL = Field(sequential=False, use_vocab=False)
# 数据字段
fields = [('text', TEXT), ('label', LABEL)]
# 加载数据(这里假设你有一个.csv文件,其中包含两列:text和label)
train_data, test_data = TabularDataset.splits(
path='./data', train='train.csv', validation=None, test='test.csv', format='csv', skip_header=True, fields=fields
)
# 构建词汇表
TEXT.build_vocab(train_data, max_size=10000, min_freq=1, vectors="glove.6B.100d", unk_init=torch.Tensor.normal_)
# 定义模型
class TextClassificationModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, output_dim, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx)
self.fc = nn.Linear(embedding_dim, output_dim)
def forward(self, text):
embedded = self.embedding(text)
# 取嵌入的平均值(简单的方法,也可以考虑其他池化策略)
avg_embed = embedded.mean(dim=1)
logits = self.fc(avg_embed)
return logits
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
OUTPUT_DIM = 2 # 假设有两个类别
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
model = TextClassificationModel(INPUT_DIM, EMBEDDING_DIM, OUTPUT_DIM, PAD_IDX)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 定义设备(CPU或GPU)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
criterion = criterion.to(device)
# 数据迭代器
train_iterator, test_iterator = BucketIterator.splits(
(train_data, test_data), batch_sizes=(64, 64), device=device, sort_key=lambda x: len(x.text),
sort_within_batch=False, repeat=False
)
# 训练循环(这里只展示伪代码)
num_epochs = 5
for epoch in range(num_epochs):
for batch in train_iterator:
optimizer.zero_grad()
predictions = model(batch.text).squeeze(1)
loss = criterion(predictions, batch.label)
loss.backward()
optimizer.step()
# 在这里可以添加验证逻辑和评估指标
# 在测试集上评估模型(这里只是伪代码)
model.eval()
with torch.no_grad():
for batch in test_iterator:
predictions = model(batch.text).max(1)[1]
# 在这里可以添加计算准确率的逻辑
# 注意:上述代码是一个简化的示例,实际使用时需要添加数据预处理、模型保存和加载、更复杂的评估逻辑














 239
239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









