






一、Stable Diffusion的技术原理
Stable Diffusion是一种基于Latent Diffusion Models(LDMs)实现的文本到图像(text-to-image)生成模型。其工作原理主要基于扩散过程,通过模拟数据的随机演化行为,实现数据的生成与变换。
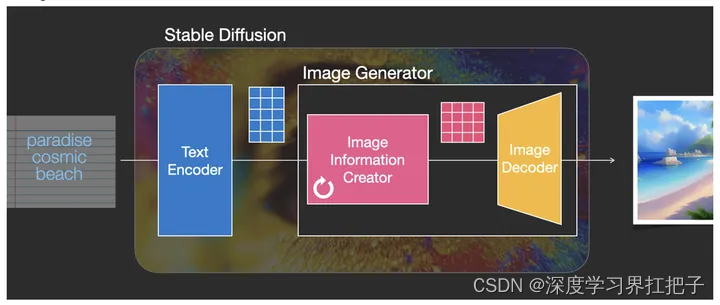
初始化:Stable Diffusion的起始点是一个随机噪声,这个噪声通过一系列的变换,逐渐接近并最终生成我们想要的图像。这个初始化的随机噪声可以理解为图像的一种潜在表示(Latent Representation)。
扩散过程:在扩散过程中,模型会将噪声逐渐地向原始数据集的中心值靠近。这个过程中,模型会学习到数据的分布特性,以及如何将噪声变换为符合这种分布的数据。

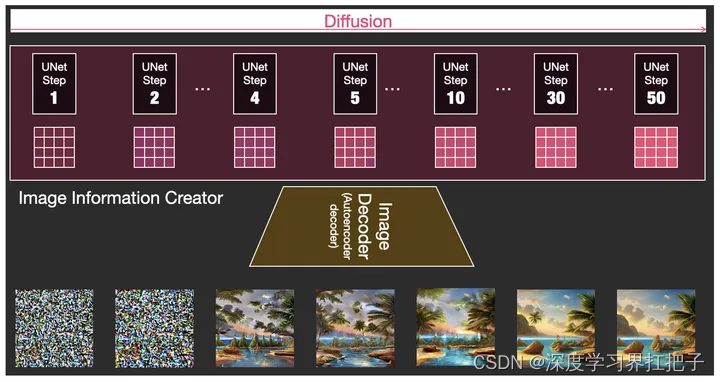
反向扩散:与扩散过程相反,反向扩散过程则是将噪声逐渐变换为我们想要的图像。这个过程中,模型会根据学习到的数据分布特性,对噪声进行逐步的变换和调整,最终生成符合我们需求的图像。
值得注意的是,Stable Diffusion中的扩散过程与反向扩散过程都是通过参数化的马尔可夫链(Markov Chain)来实现的。这使得Stable Diffusion具有极高的灵活性和可定制性,可以根据不同的需求进行调整和优化。
二、Stable Diffusion的应用前景
Stable Diffusion在图像处理、艺术创作、广告设计等领域具有广泛的应用前景。
图像处理:Stable Diffusion可以用于图像的生成、去噪、增强等任务。通过调整模型的参数和输入,我们可以生成符合特定需求的图像,如风格迁移、超分辨率重建等。
艺术创作:Stable Diffusion为艺术家提供了一种全新的创作方式。他们可以通过输入文字描述,让模型自动生成符合其想象的图像。这种方式不仅可以提高创作的效率,还可以帮助艺术家探索新的创作灵感。
广告设计:Stable Diffusion可以根据广告的需求,自动生成符合要求的图像素材。这不仅可以节省设计师的时间和精力,还可以提高广告的吸引力和效果。
此外,Stable Diffusion还可以与其他技术结合使用,如自然语言处理(NLP)技术,实现更复杂的任务,如文本到视频的转换等。














 1890
1890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









