









0. 参考
- 中文任务还是SOTA吗?我们给SimCSE补充了一些实验:https://kexue.fm/archives/8348
- simcse在英文数据上显著超过了bert-flow和bert-whitening
- SimCSE—简单有效的对比学习:https://zhuanlan.zhihu.com/p/375659368
1. 概述

2. 什么是SimCse
2.1 无监督的训练方法
一个句子,encoder得到embedding,通过dropout得到的embedding作为正例,其他的句子得到的embedding作为负例,loss函数上面是正例的余弦值的函数,分子是其负例的和,-log[esim(正例)/sum(esim(负例))],正例相似度越高,loss越小,所以符合要求,训练的话就直接这么训练参数拿到embedding?

2.1.1 实验超参数值:
droupout:0.1,0代表不进行dropout,fixed dropout=0.1,代表dropout的位置不变,每次结果都一样,就不能学到东西。
2.1.2 注意的一些东西:
SimCSE论文超强解析:https://zhuanlan.zhihu.com/p/377612458
batchsize比较大512,所以负例为n-1个,其实可能可以为2(n-1),效果可能好一点
cosine做了scale
数据增强,每个batch不同样本的dropout不一样
loss函数:对比损失?拉近类内,扩大类间距离。
对比学习,一个batch中n个样本,自己的增强数据/非自己的增强数据,有点像求了cosine值后的交叉熵,怎么实现有个图,可以参考。
2.2 有监督的方法
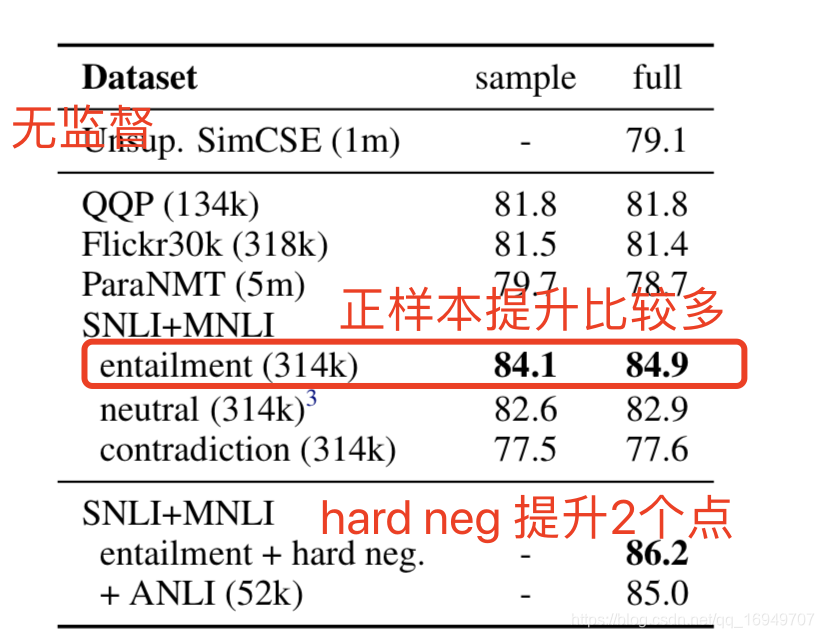
数据集标签:entailment(蕴涵),neutral(中立),contradiction(相反)
分数为:斯皮尔曼相关系数
entailment蕴含作为正例
contradiction作为hard neg
添加hard neg石墨烯可以从84.9提升到86.2,提升量还是比较大的。
2.2.1 监督对比学习长啥样

https://blog.csdn.net/qq_16949707/article/details/117044300
2.2.2 本文

loss函数:跟当前的正样本,和其他的正负样本都有关系,对比学习。

3. 总结
有监督比无监督强,无监督利用hard neg比只用entailment正样本强,所以到底他是咋构造监督学习的正负样本的呀,正样本还需要用dropout来构造吗?估计要看下论文以及代码才能知道了。
4. 代码
原文代码(英文句子支持fassi):https://github.com/princeton-nlp/SimCSE
苏剑林(中文实验):https://github.com/bojone/SimCSE/blob/main/eval.py















 1734
1734











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









