







跟着chatgpt一起学|2.clickhouse入门(1)-CSDN博客
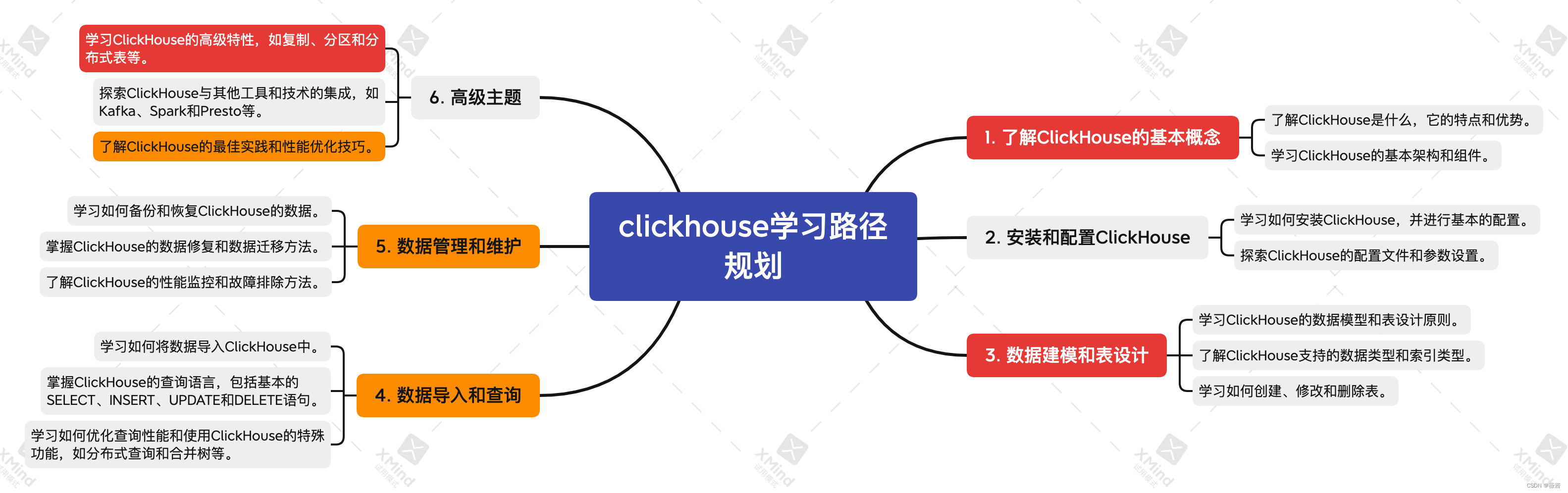
chatgpt规划的学习路径如下:
目录
2.数据建模和表设计
2.1 数据模型和表设计原则
ClickHouse是一个面向列的数据库管理系统,它的数据模型和表设计原则反映了这个特性。以下是一些关键的数据模型和表设计原则
1. 列式存储
ClickHouse的数据是按列存储的,这意味着同一列中的数据是连续存储的。这种存储方式非常适合执行聚合操作,因为它可以快速读取单一列的大量数据,并在内存中进行有效的向量化计算。
2. 数据分区
在ClickHouse中,表通常会被分区来提高查询性能和数据管理效率。分区通常是基于时间或其他逻辑进行的,例如,可以按月或按年来分区事件数据。这样做可以减少查询不需要的数据,因为系统可以针对特定的分区执行查询。
3. 主键和索引
ClickHouse的表可以定义主键,用于对数据进行排序和创建索引。主键不需要是唯一的,但它决定了数据的物理排序方式。良好设计的主键可以显著提高某些类型查询的性能。
4. 数据分片
为了提高大规模数据集的处理能力和容错性,ClickHouse支持在多个节点间分布数据。数据分片允许表在不同的服务器上存储数据的不同部分,从而可以并行处理查询。
5. 数据压缩
由于列式存储,相同列的数据类型是一样的,这使得数据可以高效压缩,节省存储空间。ClickHouse使用多种压缩算法来减少磁盘空间的使用。
6. 数据类型选择
在设计表时,应该选择最合适的数据类型。例如,如果一个字段只存储几种状态,可以使用枚举类型而不是字符串类型。
7. 冗余与去范式化
为了提高查询性能,ClickHouse中的表设计通常倾向于去范式化。这意味着可以在表中存储冗余数据来避免复杂的连接操作。
8. 物化视图和汇总表
ClickHouse支持物化视图和汇总表,这些可以用来存储预计算的聚合数据,从而加快聚合查询的速度。
9. 使用LowCardinality类型
针对具有大量重复值的字符串列,可以使用`LowCardinality`数据类型来优化存储和查询性能。
综上所述,ClickHouse的表设计原则主要集中在利用其列式存储的优势,通过合理的数据分区、分片、主键选择和压缩策略来优化性能和存储效率。
2.1.1 什么是LowCardinality类型?
在ClickHouse数据库中,`LowCardinality` 数据类型是一种用于优化存储和查询性能的特殊数据类型。它旨在用于那些具有相对较低基数(cardinality,即唯一值的数量)的列。换句话说,当一个列中的值重复率很高时,`LowCardinality` 数据类型特别有用。 `LowCardinality` 数据类型实现了对常见值的字典编码(dictionary encoding),其中每个唯一值都被映射到一个数字标识符。在数据存储时,只存储这些标识符而不是重复的值,这样可以显著减少存储空间并提高查询效率。
例如,如果你有一个字符串类型的列,其中包含大量重复的国家名称,使用 `LowCardinality(String)` 可以减少存储占用,并加快过滤和聚合操作,因为操作可以在数字标识符上执行,而不需要处理完整的字符串值。 要注意的是,`LowCardinality` 数据类型最适合那些基数不会随着时间变化而大幅增长的场景。如果基数随着时间的推移而显著增加,字典的大小和管理开销也会增长,这可能会降低性能。 使用 `LowCardinality` 数据类型时,可以在创建表或添加列时指定,例如:
CREATE TABLE example (
id UInt32,
country LowCardinality(String),
...
) ENGINE = ...上述创建表的SQL语句定义了一个带有 `LowCardinality(String)` 类型的 `country` 字段。
2.1.2 什么是数据分片?
在 ClickHouse 中,数据分片(Sharding)是指将数据按照某种规则分布到不同的物理服务器上的过程,这样可以将数据和查询负载分散到多个节点,从而提高系统的水平扩展性和查询处理能力。
ClickHouse 是一个用于联机分析处理(OLAP)的列式数据库管理系统,它可以通过数据分片和复制来实现高性能和高可用性。在 ClickHouse 的分布式架构中,每个节点可以存储整个数据库的一部分数据,而整个集群的节点共同形成了一个单一的逻辑数据库。
数据分片的关键在于选择一个合适的分片键(Sharding Key)。分片键决定了数据如何在不同的节点之间分配。例如,可以根据一个列的值(如用户ID、时间戳或任何其他字段)来分片数据,使得具有相同或相似键值的数据位于同一个分片上。ClickHouse 使用分片键对数据进行哈希,然后根据哈希值分配到不同的分片。
ClickHouse 支持自定义分片策略,允许使用不同的函数来决定数据的分布方式。例如,可以使用以下方式在创建分布式表时指定分片策略:
CREATE TABLE distributed_table AS local_table
ENGINE = Distributed(cluster, database, table, sharding_key);在这个例子中,`Distributed` 引擎创建了一个分布式表,其中 `cluster` 指定了要使用的集群配置(通常在配置文件中定义),`database` 和 `table` 指定了本地表的名称,这表明分布式表会将数据分发到指定集群的每个节点上的这个本地表中。`sharding_key` 是用于数据分片的键。
数据分片允许ClickHouse执行分布式查询,其中查询会被发送到多个分片,并在各个分片上并行执行。然后,每个分片的结果会被收集并合并,以形成最终的查询结果。这种方式可以大幅提升处理大数据集的能力,是 ClickHouse 应对大规模数据挑战的关键特性之一。
2.2 ClickHouse支持的数据类型和索引类型
2.2.1 ClickHouse支持的数据类型
1. 数值类型:
`Int8`, `Int16`, `Int32`, `Int64`, `Int128`, `Int256` 有符号整数
`UInt8`, `UInt16`, `UInt32`, `UInt64`, `UInt128`, `UInt256` 无符号整数
`Float32`, `Float64` 浮点数
`Decimal(P, S)` 定点数,P 是精度,S 是小数点后的位数
2. 字符串类型:
`String` 字符串
`FixedString(N)` 长度固定的字符串,N 为长度
3. 日期和时间类型:
`Date` 日期
`DateTime` 时间戳
`DateTime64` 高精度时间戳
4. 数组类型:
`Array(T)` T 表示数组元素的类型
5. 枚举类型:
`Enum8`, `Enum16` 枚举类型
6. 复合类型:
`Tuple(T1, T2, ...)`
`Nested` 类似于有结构的数组
7. 地理信息系统类型:
`Point`, `Ring`, `Polygon`, `MultiPolygon` 地理空间数据类型
8. 特殊类型:
`IPv4`, `IPv6` IP 地址
`UUID` 通用唯一标识符
`LowCardinality(T)` 低基数优化的类型,T 是基础数据类型
9. Nullable 类型:
`Nullable(T)` 可以包含 NULL 的数据类型,T 是基础数据类型
10.低基数类型
`LowCardinality(T)` - 用于优化具有低基数值的列的存储,T 是基础数据类型,例如 `LowCardinality(String)`
2.2.2 ClickHouse支持的索引类型
1. 主键索引(Primary Key Index)
这是用于快速数据分区(数据存储和检索)的索引。在创建表时指定,并且不能更改。ClickHouse 使用主键索引来快速缩小数据扫描的范围。例如,如果我们有一个按日期分区的表,主键可以是 `(EventDate, EventTime)`。
2. 辅助索引(Secondary Indexes)
这些是非物化的(投影索引不完全是),用于提高查询性能的索引。ClickHouse 有几种类型的辅助索引:
- 跳跃索引(Skipping Indexes):
当查询执行时,跳跃索引会帮助系统跳过不包含所需数据的数据块。
- `minmax` 索引,可以在查询时跳过不满足条件的数据块,以加快查询速度。
- `set`索引,基于集合的索引
- `tokenbf_v1` 索引可以创建布隆过滤器索引,用于快速检索包含特定词汇的数据。
- `ngrambf_v1` 同上
- 投影索引(Projection Indexes):
投影索引是表中列的子集,可以存储为独立的结构,以加快特定查询的执行。投影可以包括列的物化视图,也可以包括通过表达式计算出的数据。
2.2.3 Clickhouse支持的索引类型举例
1.创建一个带有主键和`minmax`索引的表
CREATE TABLE example_table
(
EventDate Date,
EventTime DateTime,
EventName String,
EventValue Float64,
INDEX minmax_event_time_idx EventTime TYPE minmax GRANULARITY 3
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventDate)
ORDER BY (EventDate, EventTime);在这个例子中,`EventDate` 和 `EventTime` 是主键索引的一部分,而 `minmax_event_time_idx` 是一个跳跃索引。主键索引大家都比较熟悉了,minmax索引的工作机制如下:
- 粒度
索引粒度定义了多少个数据块会被放在一起进行索引。在这个例子中,粒度为 3 意味着每 3 个数据块会有一个单独的索引项。
- 索引项
每个索引项记录了对应的数据块组(在这里是每 3 个数据块)中 `EventTime` 字段的最小值和最大值。
- 查询优化
当执行一个查询时,如果查询条件涉及到 `EventTime` 字段,ClickHouse 会检查每个索引项,以确定是否有必要读取对应的数据块。例如,如果查询是寻找在某个特定时间范围内的事件,ClickHouse 会使用 `minmax` 索引来快速跳过那些时间范围完全不重叠的数据块。
例如我们有一个查询:
SELECT *
FROM example_table
WHERE EventTime >= '2023-01-01 12:00:00' AND EventTime <= '2023-01-01 13:00:00';在这个查询中,我们寻找 `EventTime` 在 '2023-01-01 12:00:00' 到 '2023-01-01 13:00:00' 之间的事件。ClickHouse 会检查 `minmax_event_time_idx` 索引来确定哪些数据块组可能包含这个时间范围内的数据。如果某个数据块组的最大值小于 '2023-01-01 12:00:00' 或最小值大于 '2023-01-01 13:00:00',那么这个数据块组就不会包含满足条件的 `EventTime`,因此可以跳过,不用读取和处理。
`minmax` 索引可以显著加快针对时间范围的查询,尤其是当数据集非常大时。通过减少需要读取的数据块数量,`minmax` 索引有助于降低磁盘 I/O,从而提高查询性能。然而,每个索引都有一定的存储开销,并且在插入数据时需要计算,所以使用时要根据实际情况进行权衡。
2.创建带有 `set` 索引的表的示例
CREATE TABLE example_table
(
event_type String,
event_date Date,
event_data String,
INDEX event_type_idx event_type TYPE set(0) GRANULARITY 4
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(event_date)
ORDER BY (event_date, event_type);整体和前面的minmax类似。
3.创建带有 `ngrambf_v1` 索引的表的示例
该索引基于 N-gram 和布隆过滤器(Bloom filter)技术,可以有效减少在执行包含 LIKE 或 MATCH 操作的查询时需要扫描的数据量。
CREATE TABLE example_table
(
-- 定义表字段
id UInt64,
text_field String,
...
-- 定义 ngrambf_v1 索引
INDEX ngrambf_text_field_idx text_field TYPE ngrambf_v1(3, 512, 3, 0) GRANULARITY 1
)
ENGINE = MergeTree()
ORDER BY id;在这个例子中,创建了一个 `ngrambf_v1` 索引 `ngrambf_text_field_idx`,针对 `text_field` 字段。索引参数 `(3, 512, 3, 0)` 表示:
- 使用 3 为 N-gram 的长度。
- 布隆过滤器的大小为 512 位。
- 存储在布隆过滤器中的 N-gram 的最大个数为 3。
- N-gram 的起始位置偏移为 0。
`GRANULARITY 1` 指定了索引的粒度,这里设为 1,表示每个数据块都会被索引。
N-gram:
是指从文本中提取的长度为 N 的字符序列。例如,对于字符串 "ClickHouse",其 2-gram(双元组)包括 "Cl"、"li"、"ic"、"ck"、"kH"、"Ho"、"ou"、"us"、"se"。
布隆过滤器:
是一种概率性数据结构,用于测试一个元素是否在一个集合中。布隆过滤器可以高效地存储和查询数据,但它有一定的误识别率(false positive rate),意味着在某些情况下,布隆过滤器可能会错误地表示一个元素在集合中,尽管实际上它不在。
4.创建带有 `ngrambf_v1` 索引的表的示例
`tokenbf_v1` 索引是 ClickHouse 中的一种数据跳过索引,其设计用于优化文本字段上基于令牌(token)的搜索查询。该索引类型结合了令牌化(tokenization)和布隆过滤器(Bloom filter)技术,以提高执行包含 `LIKE`、`ILIKE`、`IN` 或 `==` 操作的字符串查询时的性能。
CREATE TABLE example_table
(
-- 定义表字段
id UInt64,
text_field String,
...
-- 定义 tokenbf_v1 索引
INDEX tokenbf_text_field_idx text_field TYPE tokenbf_v1(64, 3, 0) GRANULARITY 1
)
ENGINE = MergeTree()
ORDER BY id;令牌化:将文本字符串分解成一系列的令牌(tokens),通常是单词或短语。例如,对于字符串 "ClickHouse is fast",其令牌可能是 "ClickHouse"、"is"、"fast"。
在这个例子中,创建了一个 `tokenbf_v1` 索引 `tokenbf_text_field_idx`,针对 `text_field` 字段。索引参数 `(64, 3, 0)` 表示:
- 布隆过滤器的大小为 64 位。
- 存储在布隆过滤器中的令牌的最大个数为 3。
- 令牌的起始位置偏移为 0。
`GRANULARITY 1` 指定了索引的粒度,这里设为 1,表示每个数据块都会生成布隆过滤器。
5.创建投影索引的示例
它允许为表创建一个或多个投影。投影是表的一个子集,可以包含表中的部分列或者通过表达式计算得到的新列,还可能有自己的排序规则(ORDER BY)。投影的目的是优化特定查询,通过物化存储经常查询的列的特定排列或计算结果,以加快这些查询的执行速度。
CREATE TABLE example_table
(
id UInt64,
timestamp DateTime,
value Float64,
...
)
ENGINE = MergeTree()
ORDER BY (timestamp, id);
-- 创建一个投影,只包含 id 和 value 列,并按 value 排序
ALTER TABLE example_table ADD PROJECTION projection_name
(
SELECT id, value
ORDER BY value
);在这个例子中,`example_table` 是一个按照 `timestamp` 和 `id` 排序的表。通过 `ALTER TABLE` 语句添加了一个名为 `projection_name` 的投影,它只包含 `id` 和 `value` 这两个列,并且按照 `value` 列的值排序。这意味着,如果常常有基于 `value` 列的查询,ClickHouse 可以利用这个投影来提高这类查询的性能。
创建投影的语法类似于创建表的语法,包括定义列以及指定排序规则。创建投影不会立即生成数据,而是在后续的数据插入、合并或优化操作中逐渐构建的。一旦投影被构建,它就会自动用于适合的查询。
需要注意的是,投影会占用额外的磁盘空间,因为它们物化存储了额外的数据。因此,在决定使用投影时,应当平衡查询性能的提升和额外资源消耗之间的关系。投影索引主要适用于那些有着复杂查询模式和性能要求的场景。















 5471
5471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









