







问题:
小文件指的是那些size比HDFS的block size(默认64M)小的多的文件。如果在HDFS中存储小文件,那么在HDFS中肯定会含有许许多多这样的小文件(不然就不会用hadoop了)。而HDFS的问题在于无法很有效的处理大量小文件。
任何一个文件,目录和block,在HDFS中都会被表示为一个object存储在namenode的内存中,每一个object占用150 bytes的内存空间。所以,如果有10million个文件,没一个文件对应一个block,那么就将要消耗namenode 3G的内存来保存这些block的信息。如果规模再大一些,那么将会超出现阶段计算机硬件所能满足的极限。不仅如此,HDFS并不是为了有效的处理大量小文件而存在的。它主要是为了流式的访问大文件而设计的。对小文件的读取通常会造成大量从datanode到datanode的seeks和hopping来retrieve文件,而这样是非常的低效的一种访问方式。
大量小文件在mapreduce中的问题
Map tasks通常是每次处理一个block的input(默认使用FileInputFormat)。如果文件非常的小,并且拥有大量的这种小文件,那么每一个map task都仅仅处理了非常小的input数据,并且会产生大量的map tasks,每一个map task都会消耗一定量的bookkeeping的资源。比较一个1GB的文件,默认block size为64M,和1Gb的文件,没一个文件100KB,那么后者没一个小文件使用一个map task,那么job的时间将会十倍甚至百倍慢于前者。hadoop中有一些特性可以用来减轻这种问题:可以在一个JVM中允许task reuse,以支持在一个JVM中运行多个map task,以此来减少一些JVM的启动消耗(通过设置mapred.job.reuse.jvm.num.tasks属性,默认为1,-1为无限制)。另一种方法为使用MultiFileInputSplit,它可以使得一个map中能够处理多个split。
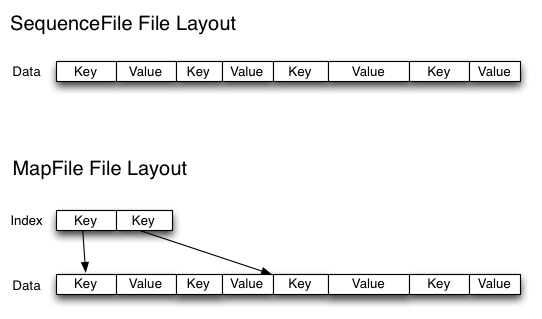
SequenceFile
package org.bigdata.util;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.SequenceFile.Reader;
import org.apache.hadoop.io.SequenceFile.Writer;
import org.apache.hadoop.io.SequenceFile.Writer.Option;
import org.apache.hadoop.io.Text;
public class SequenceFileDemo {
public static void main(String[] args) throws IOException {
Configuration cfg = HadoopCfg.getConfiguration();
Path path = new Path("seqfile");
Option optPath = SequenceFile.Writer.file(path);
Option optKey = SequenceFile.Writer.keyClass(IntWritable.class);
Option optValue = SequenceFile.Writer.valueClass(Text.class);
Writer writer = SequenceFile.createWriter(cfg, optPath, optKey,
optValue);
for (int i = 0; i < 100; i++) {
writer.append(new IntWritable(i), new Text("hello"));
}
IOUtils.closeStream(writer);
IntWritable key = new IntWritable();
Text value = new Text();
Reader.Option optionFile = Reader.file(path);
Reader reader = new Reader(cfg, optionFile);
while (reader.next(key, value)) {
System.out.println(key + "---->" + value);
}
reader.close();
}
}
MapFile
package org.bigdata.util;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.MapFile.Reader;
import org.apache.hadoop.io.MapFile.Writer;
import org.apache.hadoop.io.MapFile.Writer.Option;
import org.apache.hadoop.io.Text;
public class MapFileDemo {
public static void main(String[] args) throws IOException {
Configuration cfg = HadoopCfg.getConfiguration();
Path path = new Path("mapfile");
Option optKey = Writer.keyClass(IntWritable.class);
org.apache.hadoop.io.SequenceFile.Writer.Option optValue = Writer
.valueClass(Text.class);
Writer writer = new Writer(cfg, path, optKey, optValue);
for (int i = 100; i < 100; i++) {
writer.append(new IntWritable(i), new Text("hello"));
}
IOUtils.closeStream(writer);
IntWritable key = new IntWritable();
Text value = new Text();
Reader reader = new Reader(path, cfg);
while (reader.next(key, value)) {
System.out.println(key + "---->" + value);
}
reader.close();
}
}
MapReduce
package org.bigdata.util;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.SequenceFile.Reader;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.ReflectionUtils;
public class SequenceFileMapReduce {
public static Reader reader = null;
public static Configuration cfg = null;
public static class SequenceFileMapper extends
Mapper<Text, Text, Text, Text> {
@Override
protected void map(Text key, Text value, Context context)
throws IOException, InterruptedException {
key = (Text) ReflectionUtils.newInstance(reader.getKeyClass(), cfg);
value = (Text) ReflectionUtils.newInstance(reader.getValueClass(),
cfg);
while (reader.next(key, value)) {
...
}
}
}
...
}
通常对于“the small files problem”的回应会是:使用SequenceFile。这种方法是说,使用filename作为key,并且file contents作为value。实践中这种方式非常管用。回到10000个100KB的文件,可以写一个程序来将这些小文件写入到一个单独的SequenceFile中去,然后就可以在一个streaming fashion(directly or using mapreduce)中来使用这个sequenceFile。不仅如此,SequenceFiles也是splittable的,所以mapreduce可以break them into chunks,并且分别的被独立的处理。和HAR不同的是,这种方式还支持压缩。block的压缩在许多情况下都是最好的选择,因为它将多个records压缩到一起,而不是一个record一个压缩。
将已有的许多小文件转换成一个SequenceFiles可能会比较慢。但是,完全有可能通过并行的方式来创建一个一系列的SequenceFiles。(Stuart Sierra has written a very useful post about converting a tar file into a SequenceFile—tools like this are very useful)。更进一步,如果有可能最好设计自己的数据pipeline来将数据直接写入一个SequenceFile。















 836
836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









