







 这篇博客介绍了MoCo(动量对比)方法,一种无监督视觉表征学习的策略,通过对比学习视角看待字典查找。文章详细阐述了如何构建动态队列字典、动量编码更新,以及这种方法在ImageNet和下游任务中的表现。MOCO在实例识别任务中展示了竞争力,并暗示了无监督与有监督学习差距的缩小。
这篇博客介绍了MoCo(动量对比)方法,一种无监督视觉表征学习的策略,通过对比学习视角看待字典查找。文章详细阐述了如何构建动态队列字典、动量编码更新,以及这种方法在ImageNet和下游任务中的表现。MOCO在实例识别任务中展示了竞争力,并暗示了无监督与有监督学习差距的缩小。
文章目录
前言
论文链接: https://arxiv.org/pdf/1911.05722.pdf.
提出了一种无监督视觉表征学习的动量对比(MoCo)方法。从对比学习[29]作为字典查找的角度出发,我们建立了一个带有队列和移动平均编码器的动态字典。这使得能够即时构建大型且一致的词典,从而促进对比式的无监督学习。MOCO在ImageNet分类的公共线性协议下提供有竞争力的结果。更重要的是,MoCo学到的表征很好地转移到了下游任务中。在Pascal VOC、COCO和其他数据集上,MOCO可以在7个检测/分割任务中超过其监督的训练前同行,有时甚至远远超过它。这表明,在许多视觉任务中,无监督表征学习和有监督表征学习之间的差距已经基本缩小。
一、Introduction
最近的几项研究提出了使用与对比损失相关的方法进行无监督视觉表征学习的有希望的结果。虽然这些方法受到各种动机的驱动,但可以认为它们是在构建动态词典。字典中的“关键字”(令牌)从数据(例如,图像或补丁)中采样,并由编码器网络表示。无监督学习训练编码器执行字典查找:编码的“查询”应该与其匹配键相似,而与其他关键字不同。学习被表述为使对比损失最小化[29]。
从这个角度来看,我们假设希望建立以下字典:(1)大(2)随着训练期间的演变而保持一致。直观地说,较大的字典可能会更好地对底层连续的高维视觉空间进行采样,而字典中的关键字应该由相同或相似的编码器表示,以便它们与查询的比较是一致的。然而,使用对比损失的现有方法可以在这两个方面中的一个方面受到限制
动量对比(MoCo)作为一种建立大型且一致的字典的方法,用于无监督学习,但存在对比损失(图1)。将字典维护为数据样本队列:当前小批次的编码表示入队,最旧的出队。该队列将字典大小与最小批大小解耦,从而允许其较大。此外,由于字典关键字来自前面的几个小批次,因此提出了一种缓慢推进的关键字编码器,作为查询编码器的基于动量的移动平均来实现,以保持一致性。

MOCO是一种为对比学习构建动态词典的机制,可用于各种pretext任务。在本文中,我们遵循一个简单的实例识别任务:如果查询是同一图像的编码视图(例如,不同的作物),则查询匹配关键字。使用这个pretext任务,MoCo在ImageNet数据集中显示了线性分类通用协议下的竞争性结果。
二、Method
Contrastive Learning as Dictionary Look-up
对比学习和它的最新发展可以被认为是训练编码器完成字典查找任务,如下所述。
考虑一个编码查询
q
q
q和一组编码样本
{
k
0
,
k
1
,
k
2
,
.
.
.
}
\left \{k_{0},k_{1},k_{2},...\right \}
{k0,k1,k2,...},它们是字典的关键字。假设字典中有一个键(表示为
k
+
k_{+}
k+)与Q匹配。对比损失是当
q
q
q与其正键
k
+
k_{+}
k+相似而与所有其他键(被认为是
q
q
q的负键)不同时其值较低的函数。利用点积来度量相似性,本文考虑了一种称为InfoNCE的对比损失函数的形式:

其中
τ
τ
τ是温度超参数。总和是一个以上的正样本和
K
K
K个负样本。直观地说,这种损失是尝试分类
q
q
q 作为
k
+
k_{+}
k+的
(
K
+
1
)
(K+1)
(K+1)路基于Softmax的分类器的对数损失。对比损失函数也可以基于其他形式,例如margin-based 损失和NCE损失的变体。
对比损失用作训练表示查询和关键字的编码器网络的无监督目标函数。通常,查询表示是 q = f q ( x q ) q=f_{q}(x^{q}) q=fq(xq),其中 f q f_{q} fq是编码器网络, x q x^{q} xq是查询样本(同样, k = f k ( x k ) k=f_{k}(x^{k}) k=fk(xk))。它们的实例化取决于特定的pretext任务。输入 x q x^{q} xq和 x k x^{k} xk可以是图像、patches或由一组patches组成的上下文。网络 f q f_{q} fq和 f k f_{k} fk可以是相同的、部分共享的或不同的。
Momentum Contrast
从上面的观点来看,对比学习是一种在高维连续输入(如图像)上构建离散词典的方法。字典是动态的,因为key是随机采样的,并且key编码器在训练期间进化。作者的假设是,好的特征可以通过覆盖丰富的负样本集的大型词典来学习,而词典关键字的编码器在进化过程中尽可能保持一致。基于这一动机,我们提出动量对比,如下所述。
Dictionary as a queue.
我们方法的核心是将字典作为数据样本队列进行维护。这允许我们重用前面几个小批次中的编码键。队列的引入将字典大小与小批量大小解耦。我们的字典大小可以比典型的小批量大小大得多,并且可以灵活而独立地设置为超参数。
词典里的样本逐渐被替换了。当前小批次将排队到字典中,队列中最旧的小批次将被删除。字典始终表示所有数据的采样子集,而维护此字典的额外计算是可管理的。此外,删除最旧的小批次可能是有益的,因为它的编码key是最过时的,因此与最新的key最不一致。
Momentum update
使用队列可以使字典变得更大,但也使得通过反向传播更新key编码器变得困难(梯度应该传播到队列中的所有样本)。一种直接的解决方案是从查询编码器 f q f_{q} fq复制key编码器 f k f_{k} fk,忽略该梯度。但是这种解决方案在实验中的效果很差。我们假设这样的失败是由快速变化的编码器引起的,这降低了key表示的一致性。我们建议更新动量来解决这个问题。
形式上,表示
f
k
f_{k}
fk为
θ
K
θ_{K}
θK的参数和
f
q
f_{q}
fq为
θ
q
θ_{q}
θq的参数,我们更新
θ
K
θ_{K}
θK通过:

这里
m
∈
[
0
,
1
)
m∈[0,1)
m∈[0,1)是动量系数。只有参数
θ
q
θ_{q}
θq通过反向传播更新。公式(2)中的动量更新使得
θ
K
θ_{K}
θK比
θ
q
θ_{q}
θq更平稳地演化。因此,虽然队列中的key由不同的编码器(在不同的小批量中)编码,但是这些编码器之间的差异可以很小。在实验中,相对较大的动量(例如,m=0.999,我们的默认值)比较小的值(例如,m=0.9)工作得更好,这表明缓慢演变的key编码器是利用队列的核心。

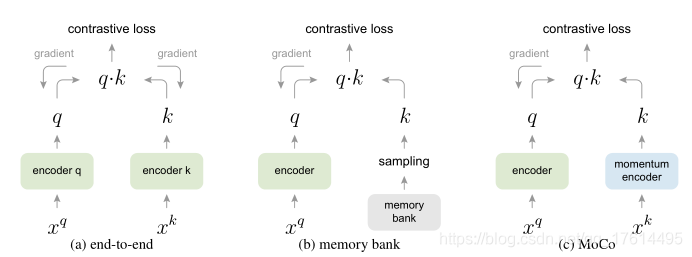
通过反向传播进行的端到端更新是一种自然机制(例如,图2a)。它使用当前小批次中的样本作为字典,因此键被一致地编码(通过相同的编码器参数集)。但是字典大小与小批量大小结合在一起,受到GPU内存大小的限制。它还面临着大批量小批量优化的挑战。最近的一些方法是基于由本地位置驱动的pretext任务,其中可以通过多个位置使词典大小更大。但这些借口任务可能需要特殊的网络设计,例如修补输入[46]或定制接受字段大小[2],这可能会使这些网络转移到下游任务变得复杂。
三、解析
这个对比学习的策略很Nice。
# positive logits: Nx1
l_pos = bmm(q.view(N,1,C), k.view(N,C,1))
# negative logits: NxK
l_neg = mm(q.view(N,C), queue.view(C,K))
# logits: Nx(1+K)
logits = cat([l_pos, l_neg], dim=1)
# contrastive loss, Eqn.(1)
labels = zeros(N) # positives are the 0-th
loss = CrossEntropyLoss(logits/t, labels)
这个地方应该很多人会懵。我当初看也是懵和同事讨论了一下才知道。
# positive logits: Nx1
l_pos = bmm(q.view(N,1,C), k.view(N,C,1))
这个地方求解的相当于一个余弦相似度的值。先来看看余弦相似度怎么求

再来看看源码的实现。

首先经过了一个L2正则。L2正则基本解决了cos余弦的分母部分。然后用正则后的值进行矩阵相乘。就得到了余弦相似度。

接下来这个操作,应该很多人也会懵。为啥label要为0?
# positive logits: Nx1
labels = zeros(N) # positives are the 0-th
两个向量越相似,则余弦相似度的值越接近1。正交的话就为0。one-hot编码中0的表示为[1,0,0,0,0,0] (假如是6分类)。相当于第一列为1,后面的都为0。符合我们loss要求解的目的。
总结
moco是一个实例级别的对比学习,忽视了同类样本之间的关系。感觉应该在分割,检测中效果更好。分类中感觉不太适用,感兴趣可以针对这个问题进行改进。

















 1795
1795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









