







前言
论文地址:https://arxiv.org/abs/1904.11492?context=cs.LG.
Non-Local Network(NLnet)通过将特定于查询的全局上下文聚合到每个查询位置,为捕获远程依赖项提供了一种开创性的方法。然而,通过严格的实证分析发现,对于图像中不同的查询位置,Non-Local Network建模的全局上下文几乎是相同的。在本文中,作者利用这一发现创建了一个基于查询无关公式的简化网络,它保持了NLnet的准确性,但计算量大大减少。进一步观察到,这种简化的设计与挤压激励网络(SENET)具有相似的结构。因此,我们将它们统一到一个用于全局上下文建模的三步通用框架中。在通用框架内,设计了一个更好的实例化,称为全局上下文(GC)块,它是轻量级的,可以有效地对全局上下文进行建模。轻量级的特性允许我们将其应用于骨干网络中的多个层来构建全局上下文网络(GCNet),该网络在各种识别任务的主要基准上通常都优于简化的NLnet和SENet。
一、Introduction
捕获远距离依赖关系的目的是提取视觉场景的全局理解,这被证明有利于广泛的识别任务,如图像/视频分类、目标检测和分割。在卷积神经网络中,由于卷积层在局部邻域内建立像素关系,所以长期依赖关系主要由深层堆积的卷积层来建模。然而,直接重复卷积层计算效率低且难以优化。这将导致对远程依赖关系的无效建模,部分原因是在远距离位置之间传递消息的困难。
为了解决这个问题,Non-Local Network被建议通过自我注意机制使用一层来对远程依赖进行建模。对于每个查询位置,非局部网络首先计算查询位置与所有位置之间的成对关系,形成关注图,然后用关注图定义的权重对所有位置的特征进行加权和。最后将聚集的特征添加到每个查询位置的特征以形成输出。
Non-Local Network中的特定于查询的注意力权重通常暗示对应位置对查询位置的重要性。虽然可视化特定于问题的重要性权重将有助于深入理解,但在原始论文中很大程度上缺少这样的分析。作者弥补了这一遗憾,如图1所示,但令人惊讶的是,我们观察到不同查询位置的注意图几乎相同,这表明只学习了与查询无关的依赖关系。
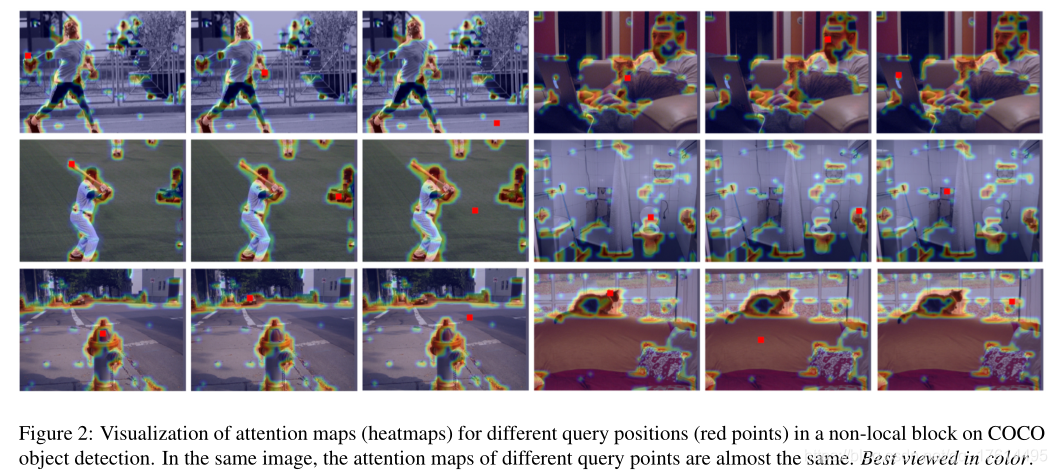
contribution:
● context模块,将所有位置的特征聚合在一起,形成一个全局的环境特征;
● 特征转换模块,以捕获通道方面的相互依赖关系;
● 融合模块,将全局上下文特征融合到所有位置的特征中。
二、Non-local Networks
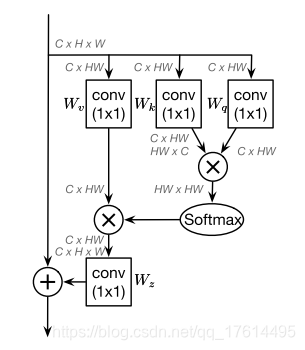
虽然non-local block想要计算出每一个位置特定的全局上下文,但是经过训练之后,全局上下文是不受位置依赖的。non-local形式上看有点像transformer的q,k,v的操作。但是仔细看这个图他这个方法貌似没有捕获远距离依赖关系。softmax是针对dim=2的位置做的。这个地方做softmax感觉有点迷,个人感觉在这个地方做sofatmax还不如对之前Wk,Wq位置的
C
×
H
W
C\times HW
C×HW的tensor做softmax。感觉是强行为了和后续的
C
×
H
W
C\times HW
C×HW相乘而做的softmax。
nn.softmax讲解: https://blog.csdn.net/weixin_41391619/article/details/104823086.
三、Method
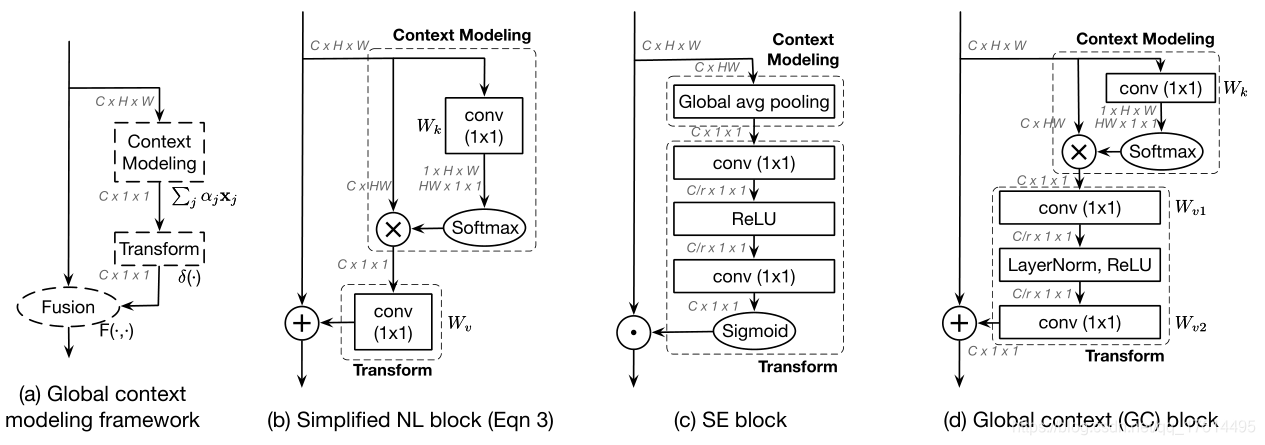
我们从最后的结果来看,GCnet得到的是一个
C
×
1
×
1
C\times 1\times1
C×1×1,与
C
×
H
×
W
C\times H\times W
C×H×W进行一个broadcast加法运算。
作者通过计算一个全局的attention map来简化non-local block,并且对所有位置共享这个全局attention map,同时忽略 Wz。为了进一步减少简化版non-local block的计算量,将 Wv 移到attention pooling的外面。
import torch
import torch.nn as nn
import torchvision
class GlobalContextBlock(nn.Module):
def __init__(self,
inplanes,
ratio,
pooling_type='att',
fusion_types=('channel_add', )):
super(GlobalContextBlock, self).__init__()
assert pooling_type in ['avg', 'att']
assert isinstance(fusion_types, (list, tuple))
valid_fusion_types = ['channel_add', 'channel_mul']
assert all([f in valid_fusion_types for f in fusion_types])
assert len(fusion_types) > 0, 'at least one fusion should be used'
self.inplanes = inplanes
self.ratio = ratio
self.planes = int(inplanes * ratio)
self.pooling_type = pooling_type
self.fusion_types = fusion_types
if pooling_type == 'att':
self.conv_mask = nn.Conv2d(inplanes, 1, kernel_size=1)
self.softmax = nn.Softmax(dim=2)
else:
self.avg_pool = nn.AdaptiveAvgPool2d(1)
if 'channel_add' in fusion_types:
self.channel_add_conv = nn.Sequential(
nn.Conv2d(self.inplanes, self.planes, kernel_size=1),
nn.LayerNorm([self.planes, 1, 1]),
nn.ReLU(inplace=True), # yapf: disable
nn.Conv2d(self.planes, self.inplanes, kernel_size=1))
else:
self.channel_add_conv = None
if 'channel_mul' in fusion_types:
self.channel_mul_conv = nn.Sequential(
nn.Conv2d(self.inplanes, self.planes, kernel_size=1),
nn.LayerNorm([self.planes, 1, 1]),
nn.ReLU(inplace=True), # yapf: disable
nn.Conv2d(self.planes, self.inplanes, kernel_size=1))
else:
self.channel_mul_conv = None
def spatial_pool(self, x):
batch, channel, height, width = x.size()
if self.pooling_type == 'att':
input_x = x
# [N, C, H * W]
input_x = input_x.view(batch, channel, height * width)
# [N, 1, C, H * W]
input_x = input_x.unsqueeze(1)
# [N, 1, H, W]
context_mask = self.conv_mask(x)
# [N, 1, H * W]
context_mask = context_mask.view(batch, 1, height * width)
# [N, 1, H * W]
context_mask = self.softmax(context_mask)
# [N, 1, H * W, 1]
context_mask = context_mask.unsqueeze(-1)
# [N, 1, C, 1]
context = torch.matmul(input_x, context_mask)
# [N, C, 1, 1]
context = context.view(batch, channel, 1, 1)
else:
# [N, C, 1, 1]
context = self.avg_pool(x)
return context
def forward(self, x):
# [N, C, 1, 1]
context = self.spatial_pool(x)
out = x
if self.channel_mul_conv is not None:
# [N, C, 1, 1]
channel_mul_term = torch.sigmoid(self.channel_mul_conv(context))
out = out * channel_mul_term
if self.channel_add_conv is not None:
# [N, C, 1, 1]
channel_add_term = self.channel_add_conv(context)
out = out + channel_add_term
return out
总结
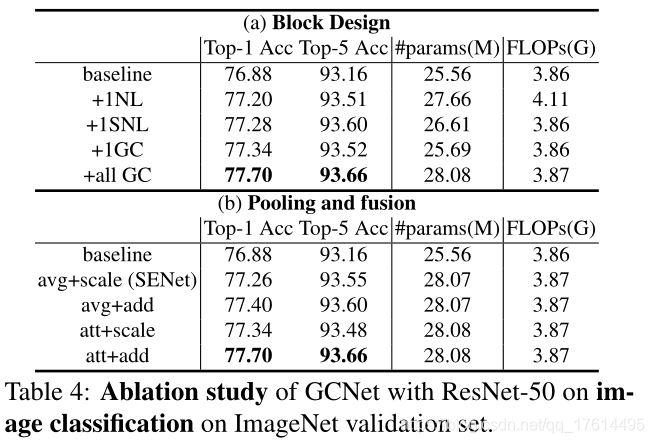
GCnet相当于一个SENet的变种,感觉他还是在处理通道上的问题,相当于在编码的过程中融入了一个全局信息。并没有论文中讲的那么玄乎。从下表来看,其实和SEnet差不了太多。GCNet和SEnet这种attention方式,感觉在检测分割里面会比分类更有效一点,尤其是在yolo最后的yololayer中。毕竟相比较于原始的featuremap,每个像素点融入了GCblock中的信息。

















 1568
1568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









