






如何在VS Code中使用本地LLM作为免费的编程Copilot
- Medium:How to use a local LLM as a free coding copilot in VS Code
您想拥有一个由人工智能驱动的项目,而无需向微软支付GitHub Copilot的费用吗?您想拥有一个在沙漠中也能离线运行、在家里也能运行的解决方案吗?想支持开源软件?您可能会对使用本地LLM作为编程助手感兴趣,您只需按照下面的说明操作即可。
在开始之前,让我们先简述一下本地LLM与GitHub Copilot的优缺点,确保这个选项适合你。
使用本地LLM的优缺点
优点:
- 免费——只需多支付一点电费
- 数据安全——数据永远不会离开您的设备
- 无需联网
- 对系统提示有完整的控制权
缺点:
- 硬件要求——要求更好的效果需要更好的设备
- 模型较差——最好的模型是专有的,对于消费级硬件来说太大了
使用工具
- Continue:https://continue.dev/
- LM Studio:https://lmstudio.ai/
准备工作
首先下载LM Studio安装程序,然后运行刚下载的安装程序。安装完成后,打开LM Studio。现在在LM Studio的主页上,中间有一个搜索栏。在这个搜索栏(或左侧的搜索选项卡,结果都是一样的)中输入您要使用的模型名称,我建议从Code Llama 7B - Instruct开始,如果我只搜索"code llama",第一个结果就是它。现在的任务是选择要下载的模型量化。为了节省内存,LLM会从16位表示法量化为更少的位数,这就需要用质量来换取大小。
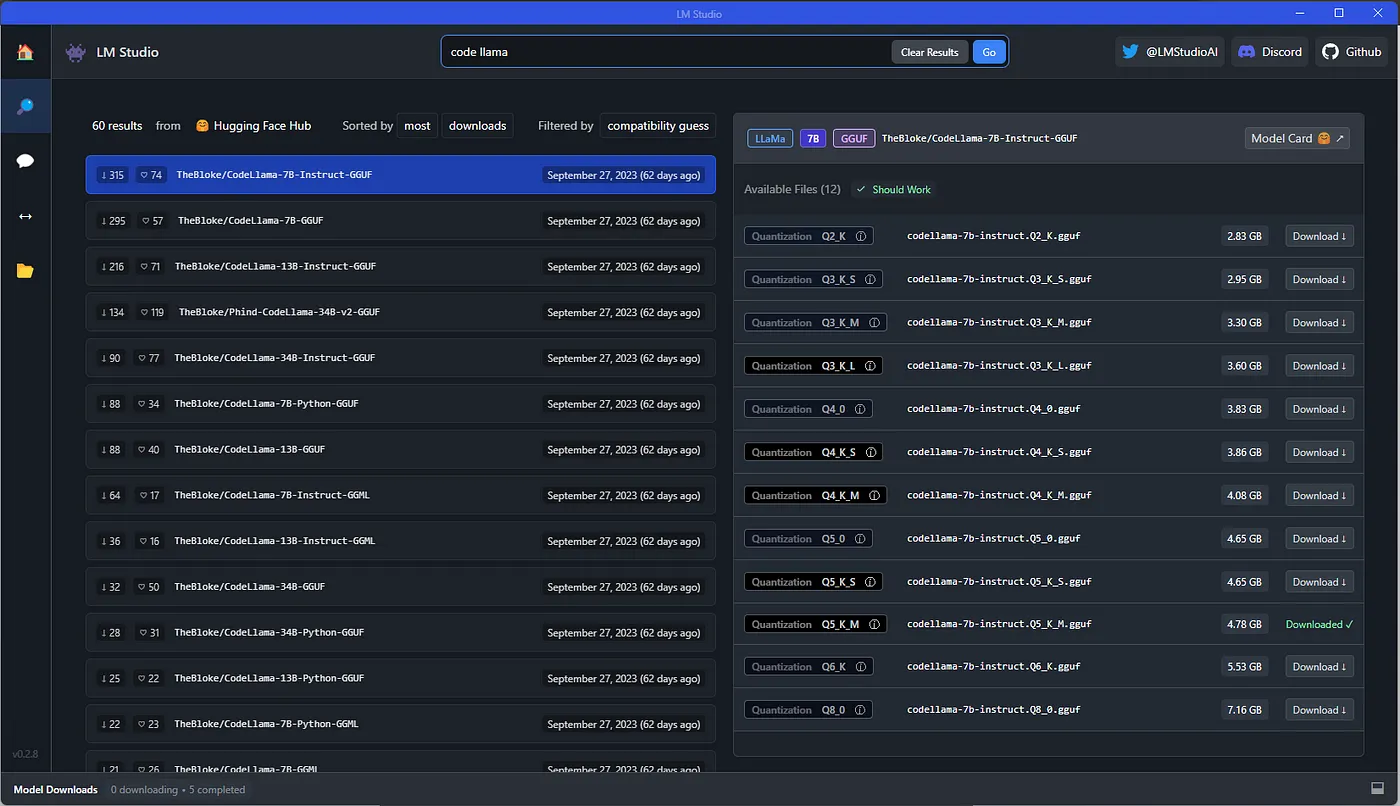
此时,您可以切换到LM Studio中的"人工智能聊天"选项卡,在加载模型后直接与模型聊天。这里我们将重点介绍LM Studio的服务器功能,以便与Continue VS Code扩展一起使用。
在LM Studio的本地服务器选项卡上,点击顶部的"选择要加载的模型"按钮(假设您还没有这样做来与模型聊天)。如果此操作失败,您可能选择的模型/量化对您的RAM来说太大了。如果您有GPU,也许可以通过将其加载到GPU来节省内存,否则您就必须选择一个更小的模型/量化。如果模型加载成功,就可以点击"Start Server(开始服务器)"按钮,然后就可以在本地服务器上托管模型了!
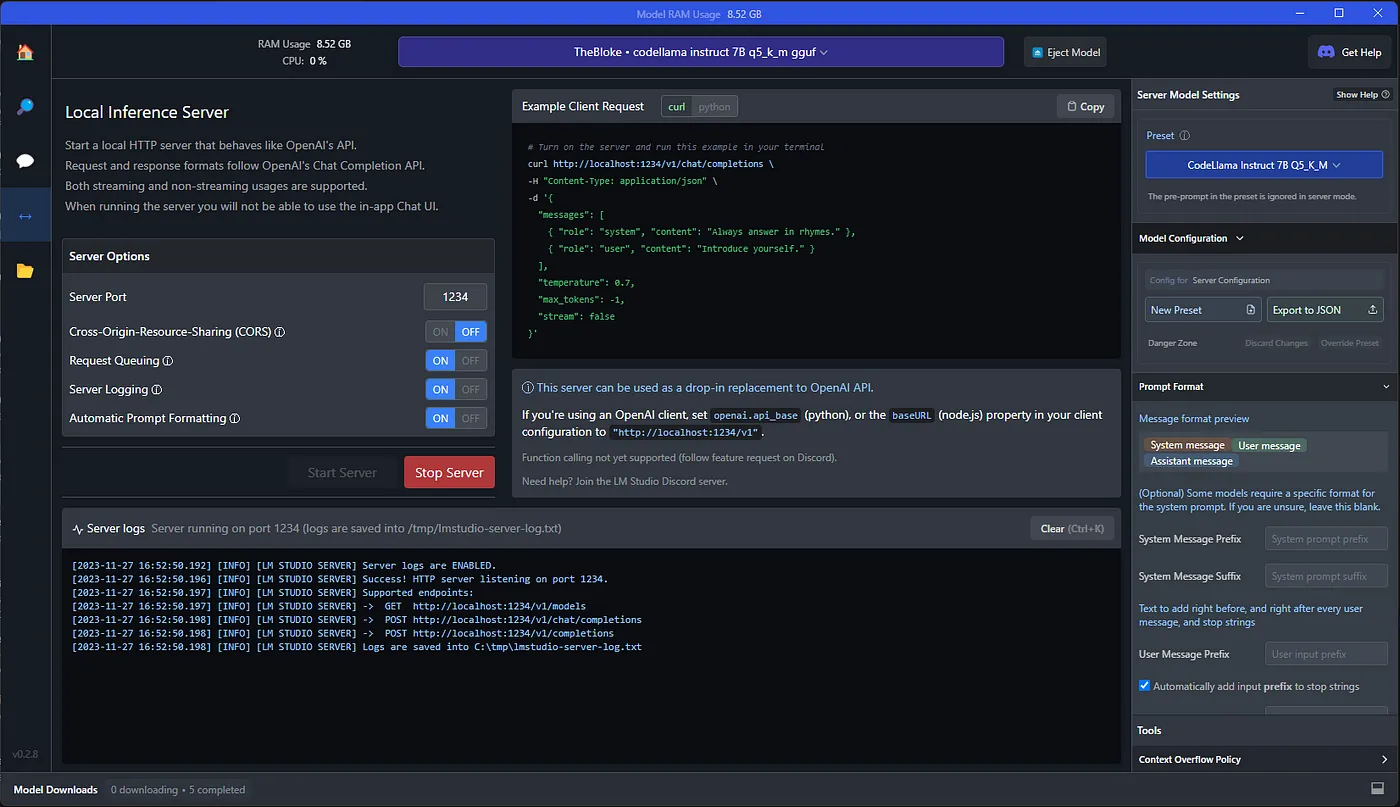
完成上述步骤后,前往VS Code下载开源Continue扩展。
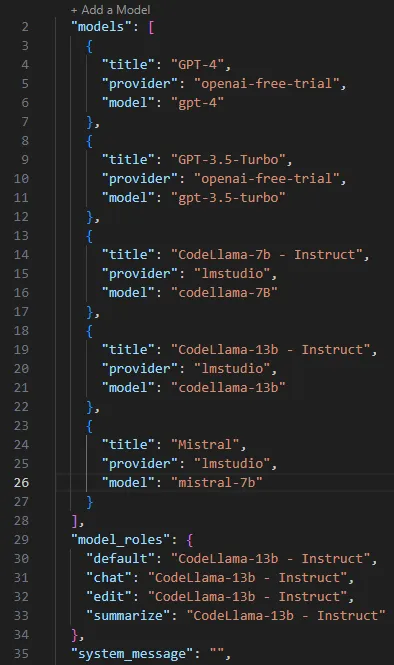
下载Continue后,我们只需将其连接到LM Studio服务器。为此,我们需要编辑Continue的config.json文件。在Windows上,该文件位于C:/Users/{user}/.continue/config.json,而在Linux或Mac上,该文件应位于~/.continue/config.json。请为计划使用的每个模型在"models"数组中添加一个JSON对象。您需要提供"title"、“provider"和"model"字段。如果愿意,还可以提供"server_url"字段,但如果"provider"字段设置为"lmstudio”,则会假定您使用的是http://localhost:1234的默认地址/端口。您还可以通过更改"model_roles"对象来设置当前使用的模型。最后,还可以通过设置"system_message"字段来设置系统提示。
您还可以在Continue的图形用户界面中设置系统提示,方法是单击Continue标签左下方的齿轮图标并编辑"系统消息"文本框。您可以通过更改Continue标签底部的方框来切换Continue在图形用户界面中使用的模型,但要注意的是,如果您使用LM Studio服务器将其设置为另一个模型,那么也要在LM Studio中加载相应的模型。否则,Continue图形用户界面将显示错误的模型。
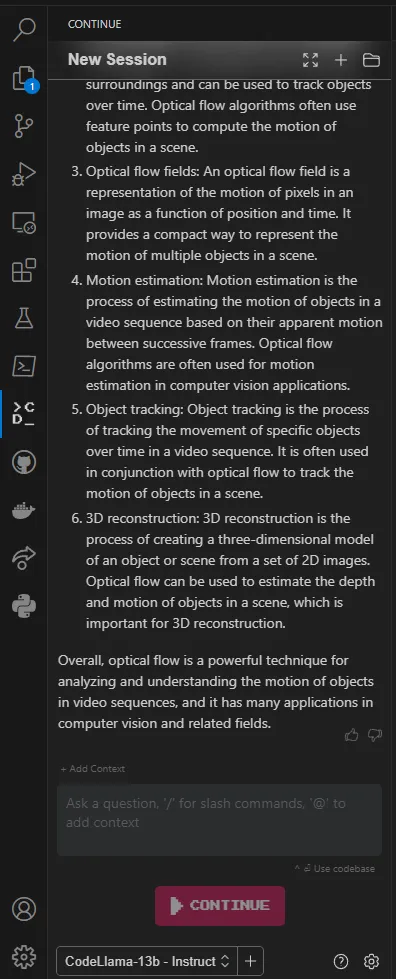
此时,您应该可以在本地LLM中使用Continue!Continue可以回答有关代码的问题、编辑代码或从头开始生成文件。详情请查看Continue文档。如果您想在不联网的情况下使用Continue,让LM Studio利用硬件的潜力来更快地运行模型,或者在LM Studio中为不同的模型保存预设配置,那么请继续下一节的内容。
调整设置
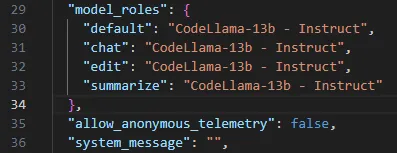
如果你想在本地完全使用Continue,请返回config.json文件并添加这一行,禁止匿名遥控,这样Continue就不会尝试与外界交互。
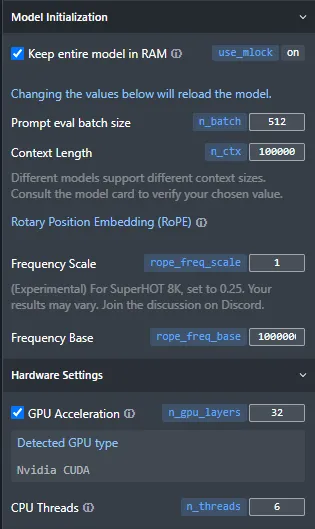
默认情况下,推理速度并不是特别快,因为它只使用CPU的4个线程,这对你的系统来说可能不是最佳选择。如果您有GPU,可以将模型加载到GPU上,从而大大加快推理速度。为此,只需选中LM Studio右侧滚动菜单底部的"GPU加速"复选框,并将n_gpu_layers设置为非零即可。正如"GPU加速"旁边的信息图标所指出的,从一个较小的数值(10-20)开始设置,直到您对GPU利用率感到满意为止。
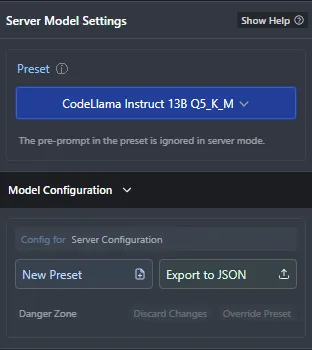
一旦有了满意的配置,就可以点击"新建预设"按钮进行保存。这将使其成为预设菜单中的一个选项,并使切换型号变得轻而易举。
现在就可以免费运行带有GPU加速功能的本地LLM编程Copilot!
扩展阅读
- LangGPT 社区:https://www.langgpt.ai/
- 数据摸鱼wx订阅号


















 940
940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









