






MiniGPT4系列之一部署篇:在RTX-3090 Ubuntu服务器部署步骤详解_seaside2003的博客-CSDN博客
MiniGPT4系列之二推理篇:在RTX-3090 Ubuntu服务器推理详解_seaside2003的博客-CSDN博客
MiniGPT4系列之三模型推理 (Web UI):在RTX-3090 Ubuntu服务器推理_seaside2003的博客-CSDN博客
启动控制器
切换到,FastChat目录下,执行以下命令:
python3 -m fastchat.serve.controller
虽然出现ERROR,但后面经验证毫无影响,不要担心。
启动model worker
新开一个窗口,执行以下命令,当进程完成模型的加载后,会看到「Uvicorn running on ...」,下面也有一些ERROR,无需理会:
python3 -m fastchat.serve.model_worker --model-name 'vicuna-7b-v1.1' --model-path /home/train/mycharm/new/vicuna
发送测试消息
再新开一个窗口,执行以下命令,出现一行字就结束了:
python3 -m fastchat.serve.test_message --model-name vicuna-7b-v1.1
启动gradio网络服务器
在此窗口内,执行以下命令,有些ERROR,不用管:
python3 -m fastchat.serve.gradio_web_server
端口映射
此时可以在服务器上访问这个地址就可以,但服务器通常没有界面,需要做个映射
再新开一个窗口,执行以下命令:
sudo iptables -t nat -A PREROUTING -p tcp --dport 8080 -j REDIRECT --to-port 7860再执行:
sudo service iptables save
下面就是见证奇迹的时刻了,你可以打开浏览器和模型聊天了。可以在通过内网IP地址:端口号访问服务了,具体地址和端口号要根据自己的设置修改。
成功运行后界面如下图所示,可以正常对话了:
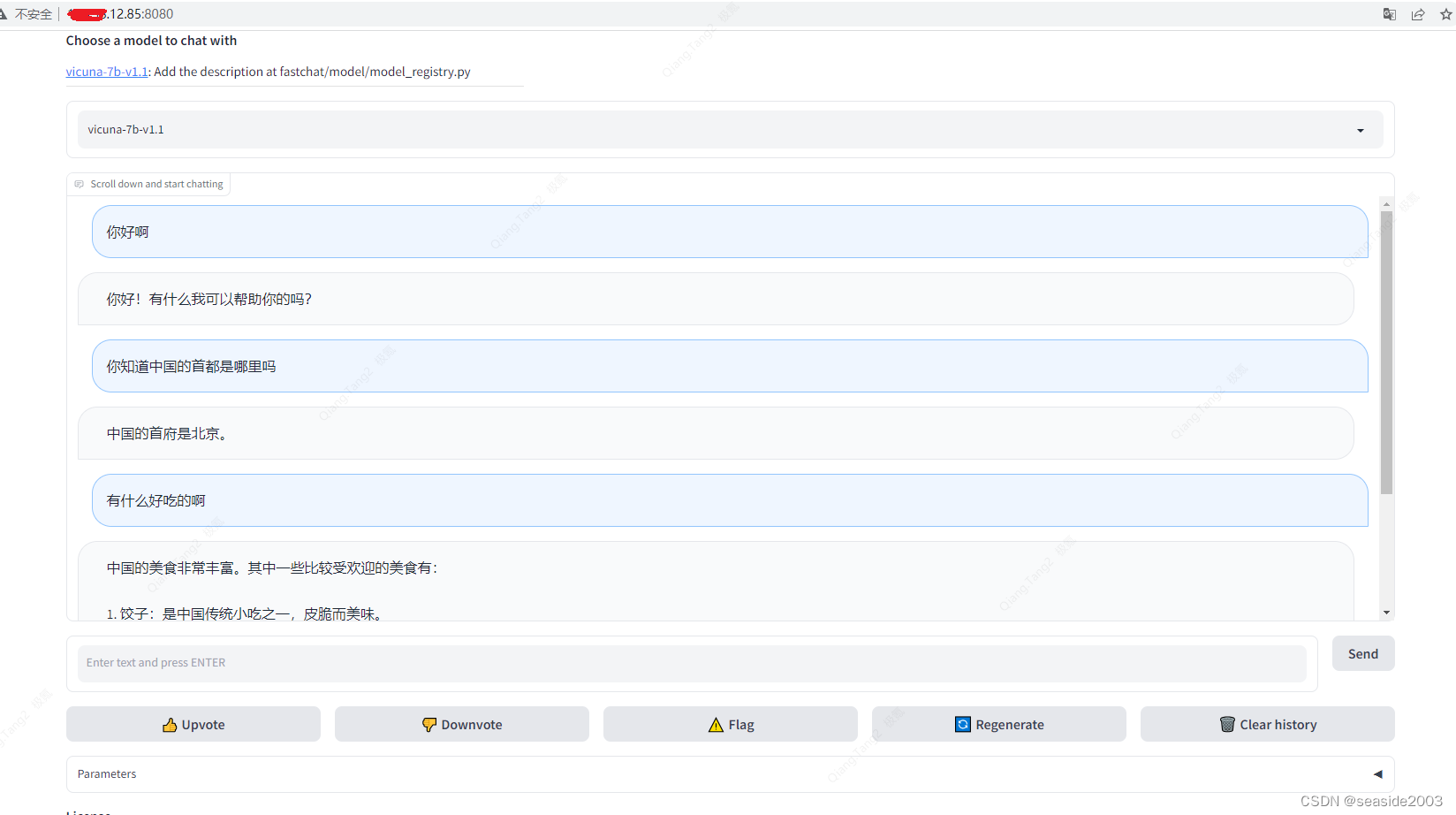
成功返回内容后,三个窗口响应请求的情况:



GPU资源消耗情况:

至此,已完成除训练外的所有工作,congratulations!
最后提一下,这个帖子,写的也还可以,可以参考:
LLM系列 | 02: Vicuna简介及模型部署实测-阿里云开发者社区
错误及解决办法:
在执行:python3 -m fastchat.serve.controller时出现以下错误:
ERROR:[Errno 98] error while attempting to bind on address ('127.0.0.1', 21001): address already in use
主要是端口占用,需要找到该端口对应的pid,kill掉即可

执行以下命令:
sudo netstat -tunlp可以看出21001端口对应的pid为810758
执行以下命令:
sudo kill -9 810758然后再次运行就会成功:
python3 -m fastchat.serve.controller















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









