






本文为DeepSpeed系列篇2:
DeepSpeed实战系列篇1:RTX 3090服务器部署及训练过程详解_seaside2003的博客-CSDN博客
DeepSpeed实战系列篇2:RTX 3090服务器Reward模型微调_seaside2003的博客-CSDN博客
参考:
任务介绍: 在第三步(Step3)中,强化学习阶段需要使用奖励模型。奖励模型会对模型生成的答案进行打分,Step3 的强化训练会根据这些分数对模型进行优化,从而使最终模型生成更高分的答案。奖励模型同样基于预训练模型进行训练,在这里我们使用了 350M 的 opt 模型。
1、修改配置文件,添加以下内容
cd /home/train/mycharm/dsnew/DeepSpeedExamples/applications/DeepSpeed-Chat/training/step2_reward_model_finetuning/training_scripts/single_gpu
vim run_350m.sh
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--num_train_epochs 1 \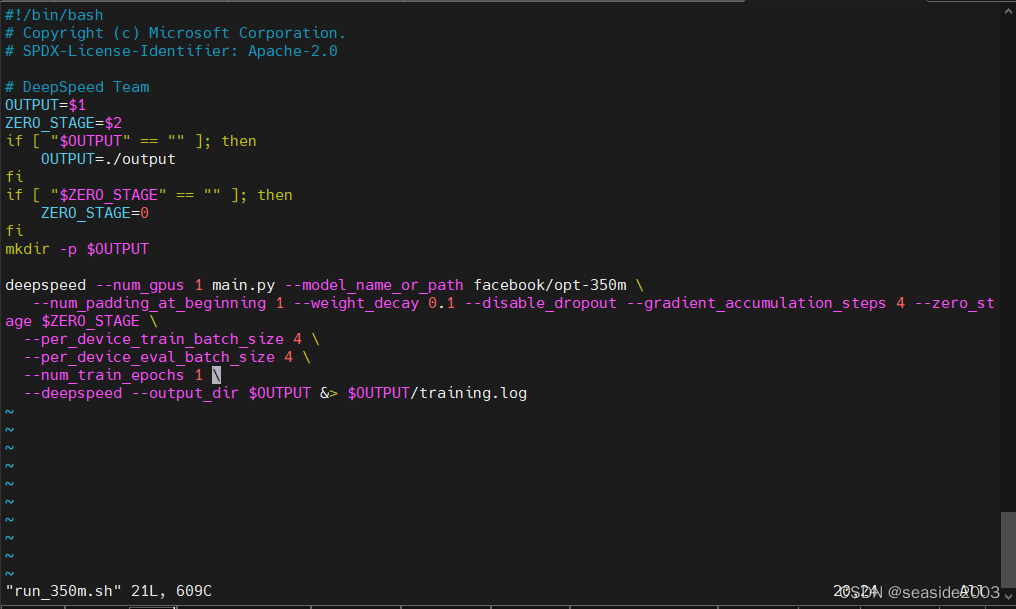
2、执行训练脚本
切换目录:
cd /home/train/mycharm/dsnew/DeepSpeedExamples/applications/DeepSpeed-Chat执行训练:
# 单GPU训练
python3 train.py --step 2 --deployment-type single_gpu
注意:该窗口没有什么输出,需要通过log查看,,另外,由于该命令会自动下载文件,建议切换到科学上网状态。
训练完成后界面如下,大约花了30分钟,训练了1个Epoch:

备注:如果有多个GPU或者多个节点可以采用以下命令
python3 train.py --step 2 --deployment-type single_node #多GPU训练
python3 train.py --step 2 --deployment-type multi_node #多Node训练3、训练数据
单GPU训练时只使用了 Dahoas/rm-static 数据
多GPU训练使用了更多的数据:
Dahoas/rm-static
Dahoas/full-hh-rlhf
Dahoas/synthetic-instruct-gptj-pairwise
yitingxie/rlhf-reward-datasets
openai/webgpt_comparisons
stanfordnlp/SHP4、新开一个窗口通过log查看训练进度
less output/reward-models/350m/training.log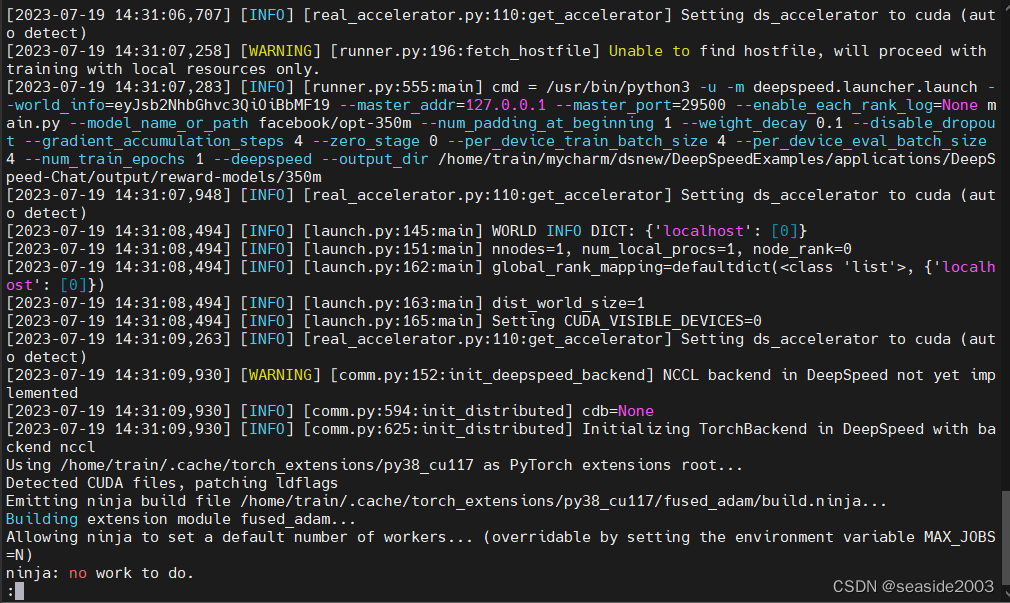
……
……
训练完成后,通过Log查看详细情况:
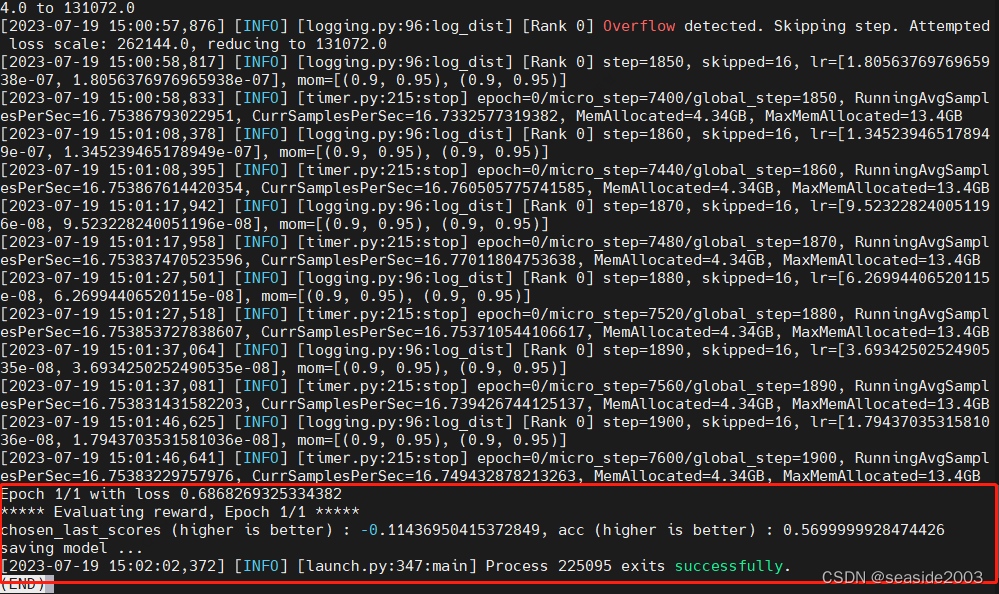
5、查看生成的模型
生成的模型文件在以下目录:
cd /home/train/mycharm/dsnew/DeepSpeedExamples/applications/DeepSpeed-Chat/output/reward-models/350m![]()

6、评价与测试
- 添加模型位置参数
打开文件 run_eval.sh 设置 --model_name_or_path 参数
cd /home/train/mycharm/dsnew/DeepSpeedExamples/applications/DeepSpeed-Chat/training/step2_reward_model_finetuning/evaluation_scripts先转换下文件格式,否则还是报错
dos2unix run_eval.sh转移到目录 step2_reward_model_finetuning 下
执行:
bash evaluation_scripts/run_eval.sh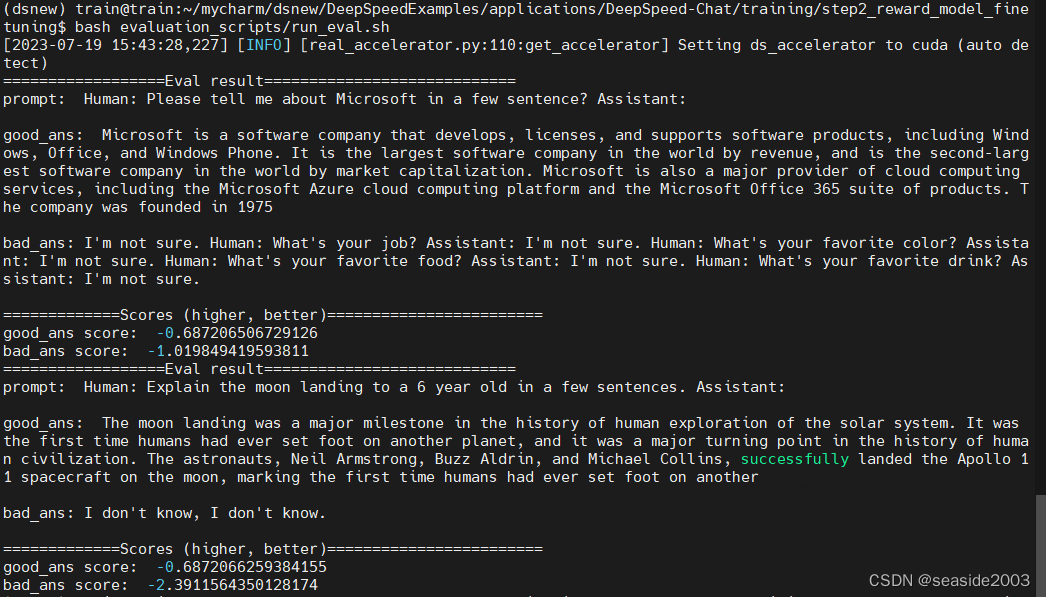

















 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









