







文章目录
1.基本使用
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p>Hello</p>', 'lxml')
print(soup.p.string)
结果:
Hello
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p>Hello</p>', 'lxml')
print(soup.prettify())

2.标签选择器
选择元素
格式:BeautifulSoup对象名.标签名
只返回匹配的第一个标签
例如:
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.title)
print(type(soup.title))
print(soup.title.string)
print(soup.head)
print(soup.p)

选择名称(name)
格式:BeautifulSoup对象名.标签名.name
获取属性(attrs)
格式:BeautifulSoup对象名.标签名.attrs['属性名']
可以调用attrs获取所有属性
html = """<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.a.attrs['class'])
print(soup.a.attrs)
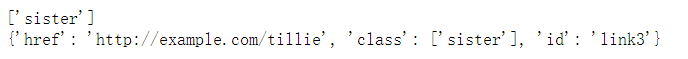
获取内容(string)
格式:BeautifulSoup对象名.标签名.string
嵌套选择
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.head.title)
print(type(soup.head.title))
print(soup.head.title.string)

子节点和子孙节点
选择(所有直接)子节点:BeautifulSoup对象名.标签名.contents,返回值为一个列表
html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.p.contents)

选择子节点:BeautifulSoup对象名.标签名.children,返回值为一个迭代器对象
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.p.children)
for i, child in enumerate(soup.p.children):
print(i, child)

获取子孙节点:BeautifulSoup对象名.标签名.descendants,返回值为一个迭代器对象
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
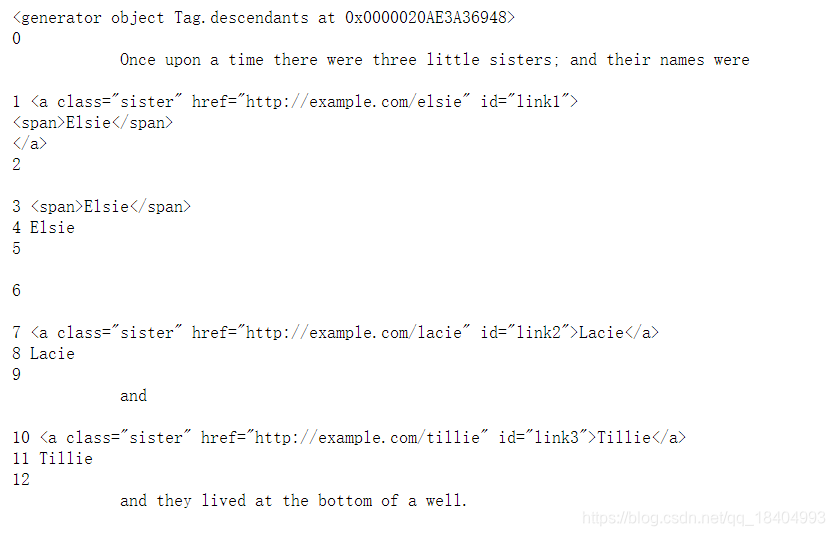
print(soup.p.descendants)
for i, child in enumerate(soup.p.descendants):
print(i, child)
父节点和祖先节点
获取父节点:BeautifulSoup对象名.标签名.parent
获取祖先节点:BeautifulSoup对象名.标签名.parents
兄弟节点
获取后一个兄弟节点:BeautifulSoup对象名.标签名.next_sibling
获取前一个兄弟节点:BeautifulSoup对象名.标签名.previous_sibling
获取后面所有兄弟节点:BeautifulSoup对象名.标签名.next_siblings
获取前面所有兄弟节点:BeautifulSoup对象名.标签名.previous_siblings
3.标准选择器
find_all(name , attrs , recursive , text , **kwargs)
name(标签名)
BeautifulSoup对象名.find_all('标签名'),返回值为列表
attrs(属性名)
BeautifulSoup对象名.find_all(attrs={'属性名':'属性值'}),返回值为列表
一些常见属性也可以直接通过属性名进行查找。
print(soup.find_all(id='list-1'))
print(soup.find_all(class_='element'))
text(文本内容)
BeautifulSoup对象名.find_all(text='文本内容'),返回值为列表,内容为text的内容。
find(name , attrs , recursive , text , **kwargs)
find()方法的用法和find_all()一直,但返回值为单个元素
find_parents() find_parent()
find_next_siblings() find_next_sibling()
find_all_next() find_next()
find_all_previous() find_previous()
4.CSS选择器
通过select()直接传入CSS选择器即可完成选择
获取属性
对象名['属性名']或者对象名.attrs['属性名']
获取内容
获取标签里的文本:对象名.get_text()或者对象名.string
5.小案例
以爬取西北大学新冠肺炎防控专题网站一个新闻页面为例,使用本节所学内容:
import requests
import re
from lxml import etree
from bs4 import BeautifulSoup
#函数1:请求网页
def page_request(url):
ua = {'User-Agent':'User-Agent:Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1'}
resp = requests.get(url,headers = ua)
print("请求状态:%d"%(resp.status_code))
html = resp.content.decode('utf-8')
return html
#函数2:解析网页
def page_analysis(html):
soup = BeautifulSoup(html, 'lxml')
title = soup.title
#打印网页标题
print(title.get_text())
#解析网页内容
info = []
info_list = soup.select('ul.lm_list > li')
for item in info_list:
title = item.a.attrs['title']
url = "http://yqfk.nwu.edu.cn/"+item.a.attrs['href']
date = item.span.string
info_item ={
'title':title,
'url':url,
'date':date
}
info.append(info_item)
print(info)
return info
#写入csv
def csv_def(info):
import csv
with open(r'D:\nwu.csv','a',encoding='utf-8-sig',newline='') as cf:
w = csv.DictWriter(cf,fieldnames = ['title','url','date'])
w.writeheader()
w.writerows(info)
print("爬取完成!")
url = 'http://yqfk.nwu.edu.cn/xxdt.htm'
html = page_request(url)
info = page_analysis(html)
csv_def(info)
















 2083
2083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









