







在上一章节中介绍了多层感知机最关键的BP算法,在这一节中主要对包括BP算法在内的多层感知机的一些细节问题进行概述。
激活函数
这里,是神经元j的诱导局部域。根据这种非线性性,输出的范围位于
之内。对式(1.1)两边取
的微分,得:
(1.2)
由于,所以导数可以表示为:
(1.3)
如果神经元j位于输出层,,其中
为输出层的神经元j的输出结果。因此神经元j的局域梯度可表示为:
(1.4)
这里是输出层的神经元j的期望响应。对任意一个隐藏层的神经元,可以将局域梯度表示为:
(1.5)
从式(1.3)可以看出,导数当
=0.5时取最大值,当
=0或1时取最小值0。因此突触权值改变最多的是那些函数信号位于他们的中间范围之间的网络神经元。正是反向传播的这个特点导致它作为学习算法的稳定性。
2、双曲正切函数:
(1.6)
它对的导数如下:
(1.7)
如果神经元j位于输出层,它的局域梯度是:
(1.8)
如果神经元j位于隐藏层,有:
(1.9)
对logistic函数用(1.4)以及(1.5),对双曲函数使用(1.8)以及(1.9),不需要激活函数的具体信息就可以计算局域梯度。
学习率:
这里a称为动量常数,通常是正数,为了观察动量常数对突触权值的影响,将式(1.10)重写为一个时间序列:
(1.11)
又由于等于
,因此
(1.12)
在这个关系的基础上,来做深入的分析:
1、当前修正值代表指数加权的时间序列的和。欲使时间序列收敛,动量常量的绝对值必须限制在0到1之间。当a等于0时,相当于(1.10)中没有第一项。
2、当偏导数在连续迭代中有相同的代数符号,指数加权和
在数量上增加,所以,权值被大幅调整。趋于在稳定的下降方向加速下降。
3、当偏导数在迭代中有相反的代数符号,指数加权和
在数量上减少,所以,权值调整不大。迭代中呈现一种左右摆动的稳定效果。
停止准则
当每一回合的均方误差变化的绝对速率足够小时,我们认为反向传播算法已经收敛。
但是这两个收敛准则都有其明显缺点。另外一个收敛准则就是检查神经网络的泛化性能,当泛化性能达到峰值时,停止迭代。
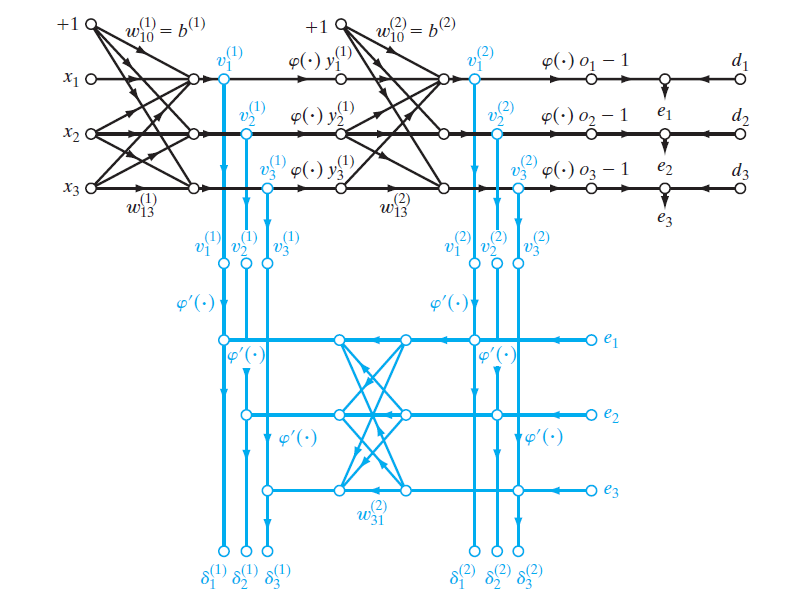
下面给出反向传播算法计算局域梯度的一个信号流程图















 2870
2870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









