







《神经网络与机器学习》第4章前半段笔记以及其他地方看到的东西的混杂…第2、3章的内容比较古老预算先跳过。
不得不说幸亏反向传播的部分是《神机》里边人话比较多的部分,看的时候没有消化不良。
多层感知机
书里前三章的模型的局限都很明显,对于非线性可分问题苦手,甚至简单的异或都弄不了。于是多层感知机(也就是传说中的神经网络)就被发明了出来对付这个问题。
多层感知机就是由一系列的感知机,或者说神经元组成,每个神经元都接受若干的输入(树突)并产生一个输出(轴突)。
这些神经元被分成若干层,每一层的神经元的输出都被作为下一层的神经元的输入,直到最外一层。这时最外一层的输出就是整个神经网络的输出。
由于神经网络的神经元数目变多了,因此可存储的信息量也增加了,复杂度也提高了,可以解决一些更难的,感知机和LSM算法解决不了的问题。
神经网络工作原理
神经网络中,每个神经元都具备一系列权值参数和一个激活函数 ϕ(x) 。神经元的工作方式如下:
设一系列输入值为 x1,x2,x3,...,xm ,权值参数为 w0,w1,w2,w3,...,wm , w0 为偏置项。
定义局部诱导域 v=w0+w1x1+w2x2+...+wmxm=wTx ,
其中 x=[1,x1,x2,x3,...,xm]T 为输入向量, w=[w0,w1,w2,w3,...,wm]T 为权值向量。
然后激活函数将局部诱导域 v 的值从整个实数集映射到某个需要的区间,作为神经元的输出值。比如激活函数为符号函数
于是输出
激活函数的形式有很多,最常用的是 sigmoid 函数:
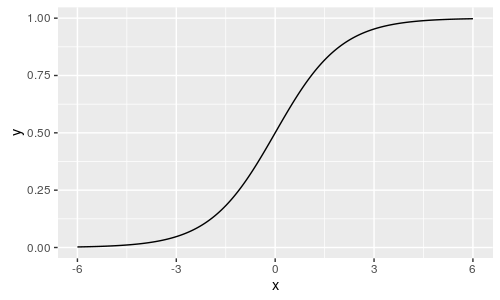
以及双曲正切函数:
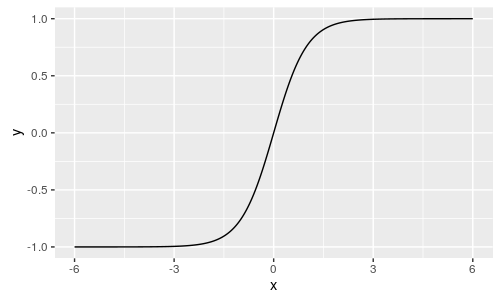
于是整个神经网络的工作方式如下:
首先有一系列输入 x1,x2,x3,...,xm ,加上作为偏置的1记为输入向量 x , x=[1,x1,x2,x3,...,xm]T 。
把 x 输入给网络第一层的每个神经元各自产生输出,设第一层有p个神经元,那么就会产生p个输出 y11,y12,y13,...,y1p (上标1表示其出自第一层神经元)。
其中 y11=ϕ(v11)=ϕ(w1T1x) , y12=ϕ(v12)=ϕ(w1T2x) ,…, y1p=ϕ(v1p)=ϕ(w1Tpx) ,以此类推。( w12 表示第一层的第二个神经元的权值向量)
这系列输出值组成第一层的输出向量 y1 。 y1=[y11,y12,...,y1p]T 。再把输出值向量像输入向量那样,前边带上1,组成第二层的输出向量 x1 。 x1=[1,y11,y12,.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1352
1352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









