







深度学习:Pytorch nn模块函数解读
nn
nn.Parameter()
这个方法可以把不可以训练的Tensor变成可以通过反向传播更新的参数。
我们以线性回归为例:
先看一下普通的版本
import torch
from torch import nn
class Linear_Regression(nn.Module):
def __init__(self):
super(Linear_Regression, self).__init__()
self.test = torch.rand(1, 2)
self.linear = nn.Linear(2, 1)
def forward(self, x):
y = self.linear(x)
return y
input = torch.rand([3, 2])
linear = Linear_Regression()
print(linear(input))
print((list(linear.named_parameters())))
打印结果分别为 线性回归的输出 与模型的参数

下面是 引用 nn.Parameter()的版本
import torch
from torch import nn
class Linear_Regression(nn.Module):
def __init__(self):
super(Linear_Regression, self).__init__()
self.test = nn.Parameter(torch.rand(1, 2))
self.linear = nn.Linear(2, 1)
def forward(self, x):
y = self.linear(x)
return y
input = torch.rand([3, 2])
linear = Linear_Regression()
print(linear(input))
print((list(linear.named_parameters())))
结果如下:
发现可更新的参数多了个test

nn.Embedding()
nn.Embeddding接受两个重要参数:
num_embeddings:字典的大小,就是我这个序列有多少个词
embedding_dim:要将单词编码成多少维的向量
代码如下:
假设我有5个词,我要把这个5个词转换成3维的tensor
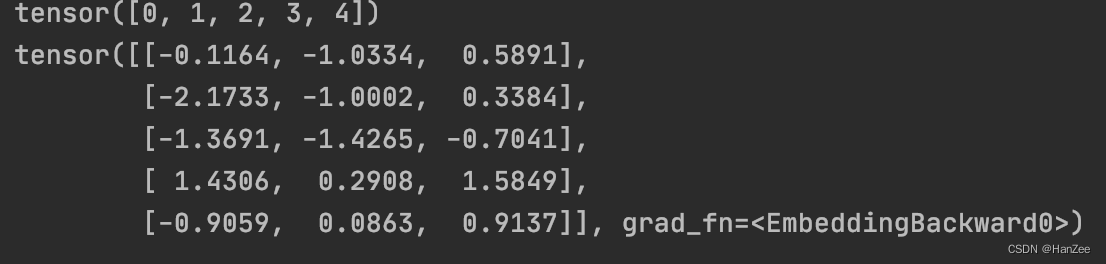
input = torch.arange(5)
print(input)
emb = nn.Embedding(5,3)
print(emb(input))
Torch
torch.cat
torch.cat(tensors,dim=0,out=None)→ Tensor
torch.cat()对tensors沿指定维度拼接,但返回的Tensor的维数不会变
>>> import torch
>>> a = torch.rand((2, 3))
>>> b = torch.rand((2, 3))
>>> c = torch.cat((a, b))
>>> a.size(), b.size(), c.size()
(torch.Size([2, 3]), torch.Size([2, 3]), torch.Size([4, 3]))
可以看到c和a、b一样都是二维的。
torch.stack()
torch.stack(tensors,dim=0,out=None)→ Tensor
torch.stack()同样是对tensors沿指定维度拼接,但返回的Tensor会多一维
>>> import torch
>>> a = torch.rand((2, 3))
>>> b = torch.rand((2, 3))
>>> c = torch.stack((a, b))
>>> a.size(), b.size(), c.size()
(torch.Size([2, 3]), torch.Size([2, 3]), torch.Size([2, 2, 3]))
可以看到c是三维的,比a、b多了一维。
torch.squeeze
torch.squeeze(input, dim=None, out=None)
参数:
input (Tensor) – 输入张量
dim (int, optional) – 如果给定,则input只会在给定维度挤压
out (Tensor, optional) – 输出张量
作用:
将输入张量形状中的1 去除并返回。 如果输入是形如(A×1×B×1×C×1×D),那么输出形状就为: (A×B×C×D)
当给定dim时,那么挤压操作只在给定维度上。例如,输入形状为: (A×1×B), squeeze(input, 0) 将会保持张量不变,只有用 squeeze(input, 1),形状会变成 (A×B)。
注意: 返回张量与输入张量共享内存,所以改变其中一个的内容会改变另一个。
为何去掉1?
多维张量本质上就是一个变换,如果维度是 1 ,那么,1 仅仅起到扩充维度的作用,而没有其他用途,因而,在进行降维操作时,为了加快计算,是可以去掉这些 1 的维度。
x = torch.randn(size=(2, 1, 2, 1, 2))
x.shape
输出结果如下:
torch.Size([2, 1, 2, 1, 2])
y = torch.squeeze(x)#表示把x中维度大小为1的所有维都已删除
y.shape
输出结果如下:
torch.Size([2, 2, 2])
torch.linspace()
torch.linspace(start, end, steps=100, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
函数的作用是,返回一个一维的tensor(张量),这个张量包含了从start到end(包括端点)的等距的steps个数据点。
常用的几个参数含义:
start:开始值
end:结束值
steps:分割的点数,默认是100
dtype:返回值(张量)的数据类型
import torch
print(torch.linspace(3,10,5))
结果:tensor([ 3.0000, 4.7500, 6.5000, 8.2500, 10.0000])
type=torch.float
print(torch.linspace(-10,10,steps=6,dtype=type))
结果:tensor([-10., -6., -2., 2., 6., 10.])

















 1062
1062











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











